Inferring Age from Linguistic and Verbal Cues in Celebrity Interviews
DOI: https://doi.org/10.1145/3616901.3616902
FAIML 2023: 2023 International Conference on Frontiers of Artificial Intelligence and Machine Learning, Beijing, China, April 2023
Current research shows that humans are able to make accurate inferences about people's age by listening to their speech, but automatic age recognition is challenging due to the limited amount of public corpora with realistic data. We add age annotations to VoxCeleb1&2 to make them longitudinal datasets suitable for age prediction tasks. The annotated dataset contains 730,281 utterances from 4432 speakers. Each celebrity appears 165 times in the final dataset on average, which allows aging analysis over time. Both age group classification and age regression are performed based on audio and transcripts of celebrity interviews. We achieve classification accuracy of 46.1% on female subjects and 40.0% on male subjects. For age regression, a mean absolute error of 8.22 years is achieved using audio features combined with sentence embeddings. To quantify how our prediction reflects the individual process of aging, we calculate the number of points that need to be removed to make age estimation monotonically increasing for each celebrity over time. The aging process is best captured for celebrities in children and young adult groups, in which an average of 1.25 and 1.57 points need to be removed for female and male subjects respectively with p-values 0.006 and 0.019.
ACM Reference Format:
Yunting Yin and Steven Skiena. 2023. Inferring Age from Linguistic and Verbal Cues in Celebrity Interviews. In 2023 International Conference on Frontiers of Artificial Intelligence and Machine Learning (FAIML 2023), April 14-16, 2023, Beijing, China. ACM, New York, NY, USA, 11 Pages. https://doi.org/10.1145/3616901.3616902
1 INTRODUCTION
Predicting the age of the speaker from an audio recording is a challenging task with a variety of interesting applications. Matching the apparent age of a speaker with a recorded age on file provides an extra level of security in voice operated systems. Other applications include display of ambient age-dependent advertisements, age-adaptive dialogue adjustment in vehicles, as well as forensic applications such as identifying the age of suspects from speech recordings. Speech signal is also a promising biomarker for cognitive impairment and dementing illness [1] [2] caused by aging, which makes vocal age a potential risk estimate of developing these diseases.
Various studies have shown that for human listeners, their mean absolute error of estimating a child's (2-9 years) age is approximately 2 years, while their estimation error for young adults (23-34 years) and older adults (56 years and older) are approximately 10 years and 13 years respectively. The human estimation error gets larger when the speaker falls into the senior age group [3] [4]. There are many challenges here in doing vocal age prediction computationally, particularly with samples drawn over recording devices of differing quantity, and ambient environments with substantially different degrees of background noise.
In this paper, we examine the use of audio and text embeddings to estimate age on an audio dataset collected in the wild, but annotated over the course of our study. Our work has three main contributions:
- Age Prediction Dataset Preparation – We add age annotation to the well-known VoxCeleb datasets [5][6] to create a new resource for the task of age prediction. VoxCeleb was originally conceived as a dataset for speaker identification research, but can be linked to birth date information through Wikipedia. Our cleaned audio dataset contains 730,281 utterances from 4432 subjects, with a wide age range from 10 to 95. The same subject may appear multiple times in the dataset recorded at different ages, providing a resource to study the effect of aging on individuals. This resource will be made available on publication.
- Vocal Age Prediction on Short Samples – We address the task of predicting age and classifying age groups given an audio of length shorter than 10 seconds. We experiment with various embeddings and conduct a text complexity analysis to choose feature representations being used in prediction models. We achieve a mean absolute error of 8.22 years in age regression task, and an age group classification accuracy of 46.1% on female subjects and 40.0% on male subjects.
- Longitudinal Analysis of Aging – We perform monotonicity analysis on the aging process by looking at how our age prediction result changes over time when the subject grows older, and observe that our estimated age increases as the real age of speakers increases. The aging process is best captured in the youngest age group, in which 1.25 and 1.57 data points per individual need to be removed in order for their predicted age to be monotonically increasing over time.
This paper is organized as follows. A literature review on age prediction based on voice is conducted in Section 2. The procedure to collect data and add annotation is introduced in Section 3. In section 4, we describe how we extract the audio and text features for prediction. Age prediction results using different features and machine learning models are discussed in Section 5. Conclusion and future directions of the work are discussed in Section 6.
2 LITERATURE REVIEW
Speaker age prediction has practical commercial applications such as age-dependent advertisements, age-adaptive dialogue adjustment in vehicles, caller-agent pairing, as well as forensic applications such as determining the age of suspects from their voice and collecting biometric evidence.
The Age Sub-Challenge at Interspeech 2010 [7] led to substantial work on speaker age prediction. Feld et al. [8] present a GMM-SVM supervector system for speaker age prediction that is adopted from speaker recognition research, and an experimental study on parameter selection. One of the challenges in age prediction through voices is the accuracy in underrepresented age groups. Lingenfelser et al. [9] apply decision level fusion and ensemble methods including Mean Rule and variants of Cascading Specialists on the AGENDER corpus [7], and these methods achieve balanced classification accuracy on all classes. Li et al. [10] and Bocklet et al. [11] build the age prediction system by combining multiple models together. The former focuses on acoustic-level methods and fused multiple GMM-SVM mean-supervector systems to improve classification accuracy. The latter builds five models in different feature spaces including spectral features, prosodic features, and glottal features, and combines these models in different configurations.
More recent research work on this topic includes [12] and [13], in which the authors explore methods to infer non-linguistic traits including age based on short durations of speech. Grzybowska et al. [14] combine i-vector and acoustic features to perform age regression, and apply cosine distance scoring as well as regression result mapping for age classification. Their classification is more accurate for the children, senior male, and senior female age groups. Ghahremani et al. [15] apply an end-to-end x-vector DNN architecture for age estimation which outperforms an i-vector baseline. Datasets used in these papers include aGender, NIST SRE08, and NIST SRE10, but they are not suitable for our project because they are not longitudinal. The goal of our project is to evaluate change in speech over time, so instead of using these datasets directly, we choose to curate a longitudinal dataset in which the same speakers talk over a long period of time.
Compared to previous work [16] [17] done on age annotation of VoxCeleb datasets, our work differs from them in three aspects: First, when building the dataset, we keep utterances spoken by the same celebrity at different times, so that one celebrity can appear in the dataset at different ages; Second, we analyze how our age prediction reflects the process of aging; Third, we experiment with sentence embeddings in addition to audio embeddings for age estimation tasks.
3 DATASET PREPARATION
VoxCeleb1 and 2 [5][6] are audio-visual datasets consisting of short clips of human speech, extracted from interview videos uploaded to YouTube. According to the dataset website, VoxCeleb contains speech from speakers spanning a wide range of different ethnicities, accents, professions, and ages. Each segment is at least 3 seconds long. VoxCeleb1 contains metadata including both speaker name and YouTube URL of the video, while VoxCeleb2 only provides video link. In order to make the dataset suitable for age prediction tasks, data cleaning and curation is done to add age information and remove unusable data. The data preparation steps are illustrated in Figure 1, and are described in detail in the following subsections.
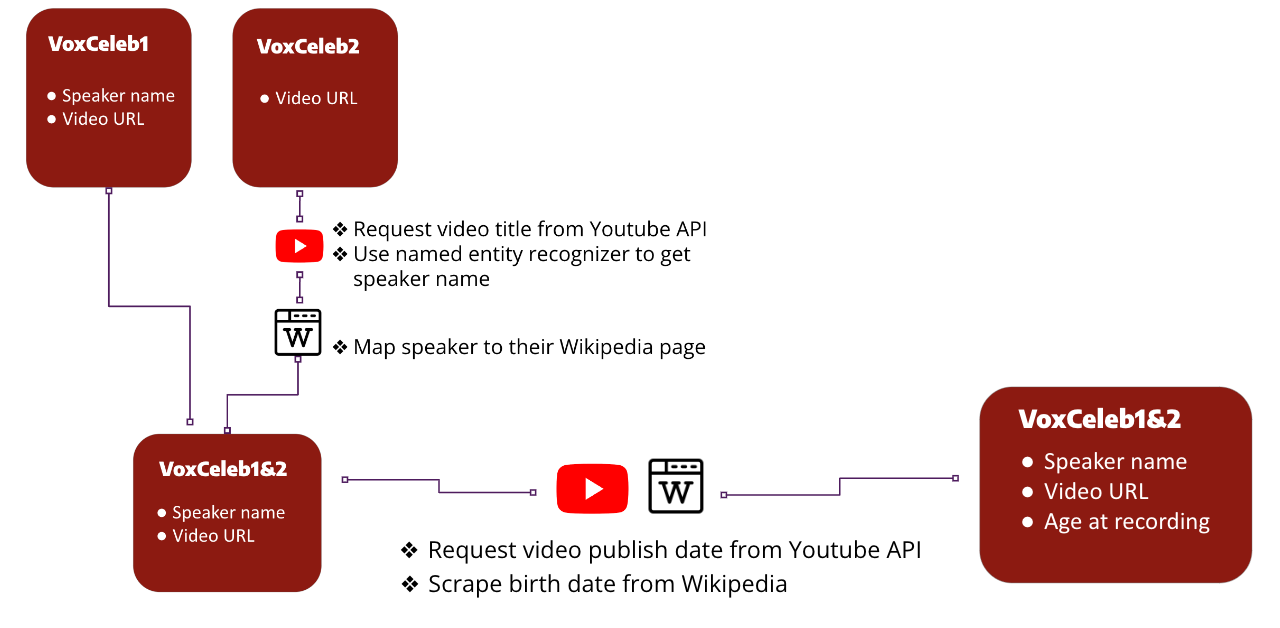
3.1 Name annotation
Both VoxCeleb1 and VoxCeleb2 provide gender information of the speaker as well as the YouTube URL from which the video is extracted. Only VoxCeleb1 provides celebrity names, while VoxCeleb2 is anonymous. To add speaker name to VoxCeleb2, we request the YouTube video title through YouTube API, and run a named entity recognition algorithm on each video title. After extracting PERSON entities, we look at all the names corresponding to the same speaker id. If the count of the most common name is greater than double the count of the second most common name, we select the most common name as the celebrity name. Speakers for which we are not confident about their names are removed from the dataset.
3.2 Age annotation
Age can be annotated given speaker names and video URLs. Since YouTube videos do not have recording dates, we use the video publish date of each interview as a proxy for its recording date. Video publish dates are requested through YouTube API, and birth dates of celebrities are scraped from Wikipedia. Age at the time of video is calculated as the difference between video publish date and celebrity birth date. We remove the video clips from the dataset when it falls into one of the following cases: 1) YouTube URLs are no longer available 2) multiple people may have the same name so we cannot determine who is the speaker 3) birth date is not public on Wikipedia. Celebrities who have passed away are also removed from the dataset, because some of the videos are published after their death date.
3.3 Dataset statistics
After these steps, 730,281 utterances from 4,432 speakers remain in the dataset. Of the remaining speakers, 34.7% are female, and 65.7% are male. The dataset is then partitioned into non-overlapping training set and test set. Number of clips for each integer age is shown in Figure 2 (left), and a plot of number of celebrities vs. number of appearances in the dataset is shown in Figure 2 (right).

|

|
3.4 Data sharing
Data and code will be available on GitHub after publication of the final article (https://github.com/sbu-dsl).
4 FEATURE EXTRACTION
4.1 Audio embedding extraction
We experimented with multiple audio embeddings including i-vector, x-vector, and VGGVox embedding, among which VGGVox embedding outperforms the rest. VGGVox is a neural embedding system based on VGG-M CNN, which is known for good classification performance. The model takes spectrograms computed with 16,000 sampling rate and frame length 0.025 as input, extracts and pools frame-level features into utterance-level speaker features, and outputs 1024-dimensional embedding. The model architecture is shown in Figure 3.
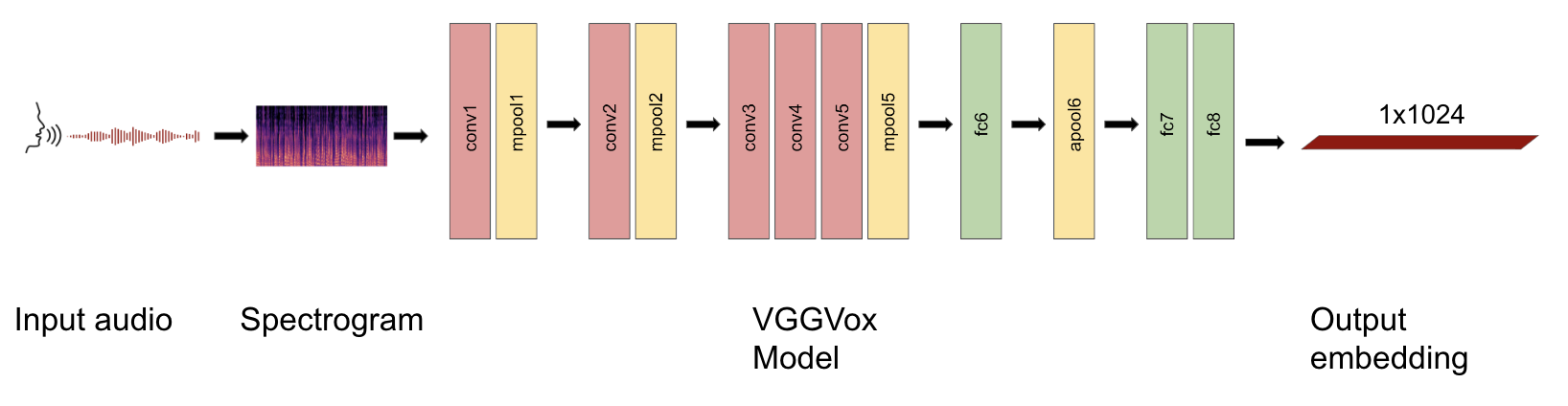
4.2 Sentence embedding extraction
Sentence embeddings capture semantic information and represent sentences as feature vectors. We first obtain transcripts of the audio clips using the Speech Recognition library (https://pypi.org/project/SpeechRecognition), and then use the SentenceTransformers library [18] to extract sentence embeddings from the following pre-trained models:
- MPNet: A model trained on a large-scale dataset (over 160GB text corpora) and fine-tuned on a variety of down-streaming tasks (GLUE, SQuAD, etc). The model maps sentences into 768-dimensional vector space capturing semantic information [19].
- Multilingual Universal Sentence Encoder: A retrieval focused multilingual sentence encoding model that maps sentences to cross-lingual representations [20].
- ALBERT: A lightweight variant of BERT that models inter-sentence coherence and uses parameter-reduction techniques to lower memory consumption and increase the training speed of BERT [21].
- MiniLM: A variant of BERT that uses task-agnostic model compression and conducts deep self-attention distillation. In its teacher student model, the student is trained by deeply mimicking the self-attention module of the teacher. It also uses the technique of distilling the self-attention module of the last Transformer layer of the teacher, as well as using scaled dot-product between values in the self-attention module as the new deep self-attention knowledge [22].
We experiment with these sentence embeddings on the age regression task. The annotated dataset is randomly splitted into training set (60%) and test set (40%), in which there are no overlapping celebrities. Age regression accuracy based on sentence embedding alone is shown in Table 1. Principal component analysis is performed on each type of embedding to observe accuracy with reduced dimensions.
| Embedding | Dimension | Linear Regression | Ridge Regression | MLP |
| MPNet | 768 | 10.95 | 10.97 | 11.58 |
| 500 | 12.31 | 12.30 | 12.34 | |
| 100 | 12.16 | 12.16 | 12.15 | |
| Multilingual Universal Sentence Encoder | 512 | 11.34 | 11.00 | 11.25 |
| 200 | 11.83 | 11.83 | 11.88 | |
| 100 | 11.76 | 11.75 | 11.58 | |
| ALBERT | 768 | 11.42 | 11.11 | 11.74 |
| 500 | 11.65 | 11.65 | 11.95 | |
| 100 | 11.46 | 11.58 | 11.58 | |
| MiniLM | 384 | 11.40 | 11.10 | 11.01 |
| 200 | 11.68 | 11.68 | 11.77 | |
| 100 | 11.63 | 11.63 | 11.72 |
5 AGE PREDICTION USING COMBINED AUDIO AND TEXT FEATURES
5.1 Age regression accuracy
For age estimation using combined audio and text features, we use the same training set and test set split as that in the previous section. We experiment with three regression models and different combinations of the features. The mean absolute error measured in years is shown in Table 2. The audio embedding alone performs best when its original dimension is preserved, and the accuracy of each model improves as text embedding is concatenated to audio embedding. Overall, ridge regression using combined VGGVox and MPNet embeddings performs best and achieves an error of 8.22 years, which means our prediction is about 8 years off on average for all the celebrities in the dataset.
| Embedding | Dimension | Linear Regression | Ridge Regression | MLP |
| VGGVox | 1024 | 8.75 | 8.35 | 8.52 |
| 500 | 11.71 | 11.39 | 11.59 | |
| 200 | 11.52 | 11.36 | 11.59 | |
| 100 | 11.40 | 11.31 | 11.59 | |
| VGGVox + MPNet | 1792 | 8.25 | 8.22 | 8.65 |
| VGGVox + Multilingual Universal Sentence Encoder | 1536 | 8.29 | 8.27 | 8.34 |
| VGGVox + ALBERT | 1792 | 8.34 | 8.31 | 8.53 |
| VGGVox + MiniLM | 1408 | 8.35 | 8.32 | 8.26 |
5.2 Age group classification accuracy
For the age classification task, celebrity ages are divided into five equal buckets so that each bucket has the same amount of data. We divide the data in this way to mitigate the problem of imbalanced data since most of the celebrities fall into middle age groups. We apply a variety of machine learning models including logistic regression, support vector classifier, decision trees, random forest, KNeighbors classifier, AdaBoost [23], multi-layer perceptron, and LSTM to perform multi-class classification. Description of the classification models used are as follows:
- Logistic regression with one-vs-rest scheme using L2 penalty is used for our experiments, which calculates the argmax of probabilities obtained by each model to make predictions.
- Support Vector Classifier finds a hyperplane that best divides a dataset into separate classes and maximizes the margin between the hyperplane and points closest to the hyperplane.
- Decision trees infer decision rules from training data and fork in tree structures until a prediction decision is made for a given record.
- Random forest is an ensemble method consisting of an uncorrelated forest of decision trees to make overall combined predictions.
- KNeighbors classifier calculates the distances between test data and all training data, selects a specified number of points closest to the test data, and votes for the most frequent label.
- AdaBoost is a boosting technique that combines weak learners and adjusts error metric for each iteration to find the best split. The algorithm is able to identify outliers, i.e., examples that are either mislabeled in the training data, or which are inherently ambiguous and hard to categorize [24].
- Multi-layer perceptron is a neural network structure that optimizes the log-loss function using stochastic gradient descent.
- LSTM is a recurrent neural network that recognizes long-term dependencies in sequential data.
The classification accuracies are higher for female celebrities, although there are fewer of them in the dataset. Logistic regression achieves the best classification accuracy of 46.1% on female subjects and 40.0% on male subjects. The overall accuracies of these models are shown in Table 3.
| Classification Model | Age Group Classification Female | Male |
| Baseline (Random Guessing) | 0.200 | 0.200 |
| Logistic Regression | 0.461 | 0.400 |
| SVC | 0.434 | 0.399 |
| Decision Trees | 0.306 | 0.300 |
| Random Forest | 0.428 | 0.374 |
| KNeighbors | 0.337 | 0.319 |
| AdaBoost | 0.399 | 0.366 |
| Multi-layer Perceptron | 0.402 | 0.356 |
| LSTM | 0.392 | 0.371 |
Normalized confusion matrices in Figure 4 show classification accuracy for each age group. Numbers shown on the diagonal represent the percentage of correctly classified subjects for each age bucket. The youngest and oldest age groups have the highest classification accuracy, while the middle age groups are more difficult to distinguish, which is similar to human performance.

|

|
5.3 Text length analysis
According to accuracies shown in Table 2, all prediction models improve when the sentence embeddings are added. We perform text length analysis to see if the length of text affects age prediction. We expect the error to be reduced for clips with longer transcripts. The length distribution of each audio clip measured in number of words is shown in Figure 5. The text lengths form a normal distribution centered around 15 words per audio clip with outliers clustered around 5 words per audio clip.
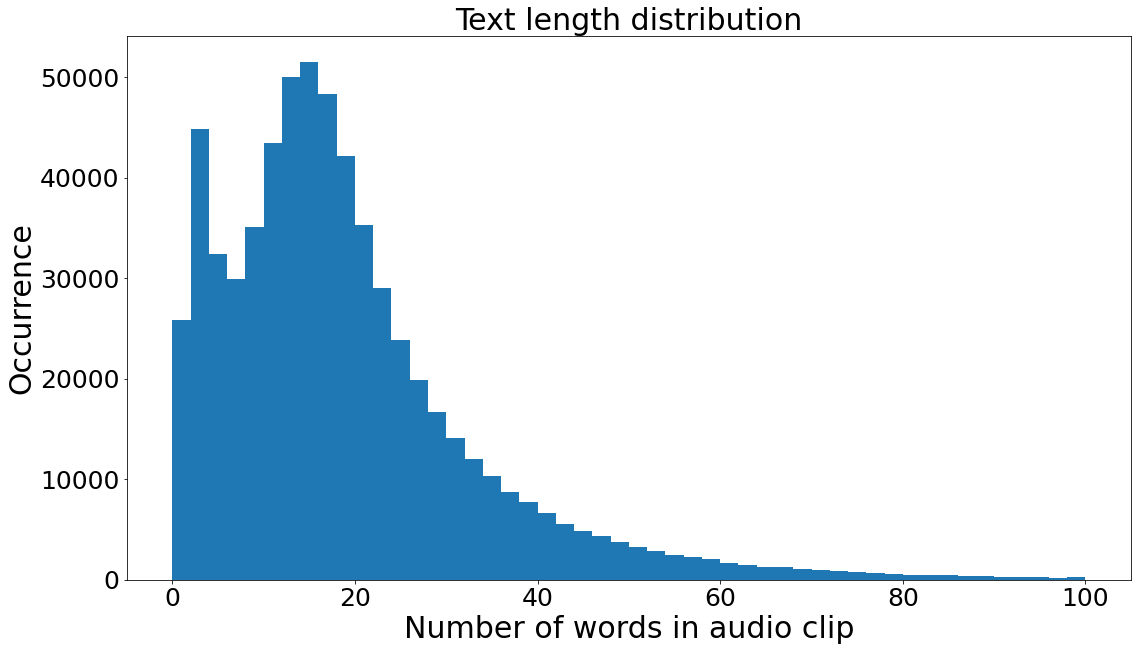
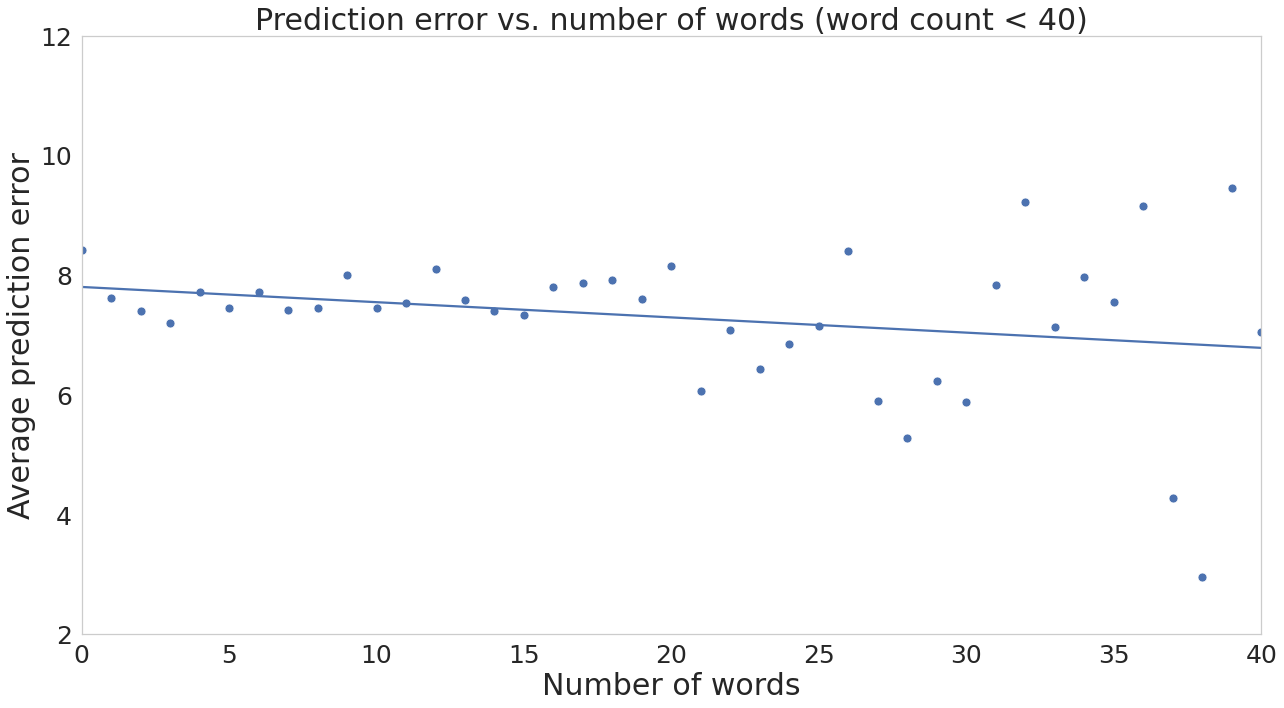
We further examine the clips with word count lower than 40, since most of the clips fall in this range. Figure 6 shows the dot plot of average prediction error for each word count. The age prediction error is reduced when there are more words spoken in the interview clip as expected. There is a negative correlation of -0.252 between average prediction error and number of words.
5.4 Monotonicity analysis
Meaningful age prediction results should reflect each individual process of aging. We examine this process using our best regression model for the two age groups we find easily identifiable – the youngest age group containing children and young adults, and the oldest age group containing older adults. The number of points that need to be deleted to make these polylines monotonically increasing are calculated as a longest increasing subsequence problem. The average number of points to be removed per speaker is calculated for comparison. Based on the result, aging in the youngest age group is best captured. To make the polylines monotonically increasing, 1.25 and 1.57 points need to be removed for female and male respectively. To visualize how our estimated age changes as the real age of speaker increases, dots belonging to the same speaker in the youngest age group are connected and drawn as a polyline in Figure 7. Asa Butterfield in the male celebrity plot is one of the celebrities showing good aging prediction. He has 4 monotonically increasing data points ranging from 14 years old to 19 years ago. On the other hand, the age prediction result for Dakota Fanning in the female celebrity plot does not reflect the process of aging, as her predicted age decreases slightly when she ages from 16 years old to 22 years old.

|

|
Permutation tests are performed to check if our result is statistically significant. Random permutations of estimated age are generated, and the number of points to be removed to satisfy monotonicity is calculated for each permutation. Table 4 shows our calculated statistics for each age group. The p-value for female and male celebrities younger than 30 are 0.006 and 0.019 respectively, which indicates that observations in the youngest age group are not likely to be obtained by chance, since they have a p-value close to zero.
| Age Group | Number of subjects | Average number of points to be removed |
p-value |
||
| Female | Male | Female | Male | ||
| Youngest (11-28) | 124 | 1.25 | 1.57 | 0.006 | 0.019 |
| 28-33 | 155 | 2.30 | 1.37 | 0.33 | 0.20 |
| 33-41 | 191 | 2.25 | 2.68 | 0.147 | 0.333 |
| 41-52 | 189 | 2.22 | 3.85 | 0.216 | 0.147 |
| Oldest (52-95) | 111 | 2.39 | 2.17 | 0.088 | 0.647 |
6 CONCLUSION
We have annotated age on an audio dataset containing a large number of celebrities, and performed analysis on their speech. We have shown that a combination of audio and text embeddings give an age estimation result more accurate than human listeners. Our age prediction result changes in the same direction as the aging process, especially in the young children's age group. An extension of this work can take the visual aspect of the dataset into consideration. The video clips of celebrities talking can be fetched from YouTube through APIs and facial recognition techniques can be applied to predict age and analyze the process of aging. We leave these as future work.
REFERENCES
- Matej Martinc and Senja Pollak. “Tackling the ADReSS Challenge: A Multimodal Approach to the Automated Recognition of Alzheimer's Dementia”. In: Proc. Interspeech 2020. 2020, pp. 2157–2161.
- Jiahong Yuan et al. “Disfluencies and Fine-Tuning Pre-Trained Language Models for Detection of Alzheimer's Disease”. In: Proc. Interspeech 2020. 2020, pp. 2162–2166.
- Moyse E. Age estimation from faces and voices: A review. Psychologica Belgica. 2014;54(3).
- Moyse E, Beaufort A, Brédart S. Evidence for an own-age bias in age estimation from voices in older persons. European Journal of Ageing. 2014;11(3):241-247.
- A. Nagrani, J. S. Chung, and A. Zisserman. “VoxCeleb: a large-scale speaker identification dataset”. In:INTERSPEECH. 2017.
- J. S. Chung, A. Nagrani, and A. Zisserman. “VoxCeleb2: Deep Speaker Recognition”. In: INTERSPEECH. 2018.
- B. Schuller et al. “The INTERSPEECH 2010 paralinguistic challenge”. In: INTERSPEECH. 2010.
- M. Feld, F. Burkhardt, and Christian A. Muller. “Automatic speaker age and gender recognition in the car for tailoring dialog and mobile services”. In: INTERSPEECH. 2010.
- Florian Lingenfelser et al. “Age and gender classification from speech using decision level fusion and ensemble based techniques”. In: INTERSPEECH. 2010.
- Ming Li, Chi-Sang Jung, and Kyu Jeong Han. “Combining five acoustic level modeling methods for automatic speaker age and gender recognition”. In: INTERSPEECH. 2010.
- Tobias Bocklet et al. “Age and gender recognition based on multiple systems - early vs. late fusion.” Jan. 2010, pp. 2830–2833.
- Shareef Babu Kalluri, Deepu Vijayasenan, and Sriram Ganapathy. “A Deep Neural Network Based End to End Model for Joint Height and Age Estimation from Short Duration Speech”. In: ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2019, pp. 6580–6584.
- Shareef Babu Kalluri, Deepu Vijayasenan, and Sriram Ganapathy. “Automatic speaker profiling from short duration speech data”. In: Speech Communication 121 (2020), pp. 16–28.
- Joanna Grzybowska and Stanislaw Kacprzak. “Speaker Age Classification and Regression Using i-Vectors”. In: Interspeech 2016. 2016, pp. 1402–1406.
- Pegah Ghahremani et al. “End-to-end Deep Neural Network Age Estimation”. In: Proc. Interspeech 2018. 2018, pp. 277–281.
- Khaled Hechmi, et al.(2021). "VoxCeleb Enrichment for Age and Gender Recognition." 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU).
- Naohiro Tawara, Atsunori Ogawa, Yuki Kitagishi, and Hosana Kamiyama, “Age-vox-celeb: Multi-modal corpus for facial and speech estimation,” in ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6963–6967.
- Nils Reimers and Iryna Gurevych. “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks”. In:Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Nov. 2019.
- Kaitao Song et al. “MPNet: Masked and Permuted Pre-training for Language Understanding”. In: Advances in Neural Information Processing Systems. Ed. by H. Larochelle et al. Vol. 33. Curran Associates, Inc., 2020, pp. 16857–16867.
- Yinfei Yang et al. “Multilingual Universal Sentence Encoder for Semantic Retrieval”. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Online: Association for Computational Linguistics, July 2020, pp. 87–94.
- Zhenzhong Lan et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. 2019. doi:10.48550/ARXIV.1909. 11942. url: https://arxiv.org/abs/1909.11942.
- Wenhui Wang et al. “MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers”. In: Advances in Neural Information Processing Systems. Ed. by H. Larochelle et al. Vol. 33. Curran Associates, Inc., 2020, pp. 5776–5788.
- Yoav Freund and Robert E Schapire. “A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting”. In: Journal of Computer and System Sciences 55.1 (1997), pp. 119–139.
- Robert E. Schapire. “A Brief Introduction to Boosting”. In: Proceedings of the 16th International Joint Conference on Artificial Intelligence – Volume 2. IJCAI’99. Stockholm,Sweden: Morgan Kaufmann Publishers Inc., 1999, pp. 1401–1406.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from permissions@acm.org.
FAIML 2023, April 14–16, 2023, Beijing, China
© 2023 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 979-8-4007-0754-4/23/04…$15.00.
DOI: https://doi.org/10.1145/3616901.3616902