Are you a Foodie looking for New Cookies to try out? Better not ask an LLM
DOI: https://doi.org/10.1145/3639856.3639896
AIMLSystems 2023: The Third International Conference on Artificial Intelligence and Machine Learning Systems, Bangalore, India, October 2023
Large Language Models (LLMs) have become our new go-to pals for asking anything including product recommendations. In fact, some people predict that LLMs will replace the search engines in near future. Therefore, it is imperative to measure how diverse an LLM's product recommendations are – a less diverse recommendation may imply bias towards selected sellers, and thus have adverse effect on others. Specifically, diversity is known to counter popularity bias, aid in personalization and catalogue coverage, impede cold start problem and effects of fake reviews. In this work, we explore arguably the two most popular LLMs: GPT-3.5 and GPT-4, and analyse the diversity of their recommendations on different categories of products. Surprisingly, we found that GPT-4 is less diverse than its predecessor. We believe that the diversity framework mentioned in this work will serve as a guidance for e-commerce businesses who are exploring LLMs to provide recommendations to their customers.
ACM Reference Format:
Binay Gupta, Saptarshi Misra, Anirban Chatterjee, and Kunal Banerjee. 2023. Are you a Foodie looking for New Cookies to try out? Better not ask an LLM. In The Third International Conference on Artificial Intelligence and Machine Learning Systems (AIMLSystems 2023), October 25--28, 2023, Bangalore, India. ACM, New York, NY, USA 4 Pages. https://doi.org/10.1145/3639856.3639896
1 INTRODUCTION
Diversity often helps in personalisation and generating more user engagement [9, 13], for example, the average number of podcasts streamed per user increased by 28.90% on Spotify by embracing diversity based recommendation strategy. Additionally, diversity also improves catalogue coverage [12] because more items are displayed to the users who may then choose to buy these items. Diversity has also been shown to aid in cold start problem for new users and newly launched products by promoting a broader range of recommendations [7, 26]. Diversity in retail recommendation systems provides several advantages. It helps counter popularity bias, ensuring that less popular items receive adequate exposure, thus preventing dissatisfaction among both sellers and customers. Additionally, diversity enhances personalization by allowing customers to explore and understand their preferences. It aligns with the long tail theory, where revenue is generated from a broad range of items, not just the popular ones. Moreover, diversity improves catalogue coverage, addressing the issue of limited representation of items.
Some works predict that Large Language Models (LLMs) will serve as recommender systems in future [10, 24], while others foresee current recommender systems to be augmented with LLMs for better recommendations [6, 14]. In either case, it is important to measure the level of diversity that an LLM's recommendations contain. In this work, we study the comparative performance of the two state-of-the-art LLMs, GPT-3.5 and GPT-4, in terms of providing more diverse recommendations. This is of significant interest to the retail organisations as it can help to gain and retain customers and generate more revenue by providing diverse recommendations to the users. The next part of the work talks about the experimentation framework, followed by the comparative results and their analysis.
| Product Category | Products | Qualifier |
|---|---|---|
| Electronics | Smartphone, Laptop, Tablet, | No Qualifier, beautiful, reliable, |
| Smart TV, Wireless Earbuds, Camera, Printer, | durable, authentic, shiny | |
| Game Console, Headphones, Smart Watch | ||
| Home Appliances | Air fryer, Coffee maker, Vacuum cleaner, Refrigerator, | No Qualifier, beautiful, reliable, |
| Washing machine, Dishwasher, Microwave oven, Toaster, | durable, authentic, shiny | |
| Kettle, Blender | ||
| FMCG - Toiletries | Toilet Paper, Detergent, Hand Soap, Air freshener, | No Qualifier, Fresh, Healthy, Affordable, |
| Toothpaste, Shampoo, Soap, Shaving cream, | Natural, Sustainable, Innovative, | |
| Diapers, Baby wipes | Nourishing | |
| FMCG - Edible | Bread, Milk, Eggs, Cheese, Butter, | No Qualifier, Healthy, Organic, Natural |
| Cookies, Juice, Coffee, Tea, Oil, | Flavorful, Wholesome, Convenient, | |
| Affordable, Satisfying |
2 METHODOLOGY
Recommender systems are currently popularly used by large retail chains for suggesting products to customers based on their prior search history and helping them to do shopping from the convenience of their homes in few clicks. They help these companies in higher customer onboarding and retention and a much better and faster user experience. With the recent hype around LLMs, they are being used as part of these recommender systems. More details about the application of LLMs in recommender systems can be found out in various prior works in this context, such as [6, 14].
Now, there is a community interest and significant proof of the effectiveness of LLMs in recommender systems, and bias and diversity of recommended products is an important consideration for a retail organisation in order to give good recommendation to the customers for high customer retention, customer onboarding and higher revenues. So, it is important to find out if the recommendations provided by the state-of-the-art LLMs are diverse enough. We study the recommendation results from the two most popular LLMs – GPT-3.5 and GPT-4 for this purpose. An overview of our experimental setup is shown in Figure 1. The steps involved in this process are briefly as follows:
Data Collection: At first, necessary data needs to be collected for evaluation. We consider 4 popular retail product categories: Electronics, Home Appliances, FMCG (Fast Moving Consumer Goods) - Toiletries and FMCG - Edible. For each product category, based on some reliable sources of reference, we scrap some popular products in that category and some popular qualifiers (search adjectives for the product names). [1, 2, 3, 4, 5, 8, 11, 15, 16, 17, 18, 19, 21, 22, 25] are the data sources we have used to scrape this necessary data. The top products and corresponding qualifiers for the four different product categories have been identified from these sources and are illustrated in Table 1.
Prompt: A very small, simple yet effective prompt is used to generate responses from both GPT-3.5 and GPT4. The format of the prompt is shown below:
"Name <N> <qualifier> <product> available in market as list of (brand name, company name) tuple format."
Here, N is the size of the tuple-list, qualifiers and products are already described above.
Evaluation: For each product and the corresponding relevant qualifiers, we compute the diversity scores of the recommendations from both GPT-3.5 and GPT-4 models. We perform this evaluation for various temperatures for each product and search qualifier combination search term from temperature 0 to 2 with intervals of 0.1.
2.1 Diversity measurement scores
In this section, we talk about two popular and relevant metrics used in literature to measure this diversity within a single sample.
- Herfindahl–Hirschman index: Herfindahl–Hirschman index (HHI) [20] is a measure of the size of firms in relation to the industry and an indicator of the amount of competition among them. For a list L having N items which is shared among B brands:
where H denotes the HHI score. HHI value is bounded between [0,1/B]\begin{equation} H = \sum _{i=1}^{B} ({\frac{No.\ of\ items\ \epsilon \ {brand}_{i}}{N}})^{2} \end{equation}
(1) - Pielou Index: Pielou Index [23] is a smoothened version of the HHI index score.
where Dpieu denotes the Pielou Index, S denotes the number of species, ni denotes the abundance of the ni-th species and N denotes the total abundance of each species. Pielou index is a way to measure how the species are evenly distributed in a community. Its value is defined between 0 and 1, where 1 represents a community with perfect evenness, and it decreases to zero as the relative abundances of the species diverge from evenness.\begin{equation} {D}_{pieu} = \sum _{i=1}^{S} \frac{{n}_{i}({n}_{i}-1)}{N(N-1)} \end{equation}
(2)
Thus, we use Pielou index as our diversity score in our further experiments. Consequently, in the rest of the text, we refer to the Pielou index as the diversity score.
3 RESULTS
For performing the comparative evaluation of GPT-3.5 and GPT-4 models with respect to their ability to provide diverse recommendations, we conduct a 3-step experimentation.
First, for each product search term (product category with corresponding qualifier), for both GPT-3.5 and GPT-4 models, the diversity scores are computed for each temperature from 0 to 2 with an interval of 0.1. The diversity scores are averaged for each temperature for each model and plotted. The corresponding plot is illustrated in Figure 2(a). The plot clearly shows that for each temperature, GPT-3.5 model has a higher diversity score compared to GPT-4 model. This clearly indicates that GPT-3.5 model produces more diverse results, when compared temperature wise.
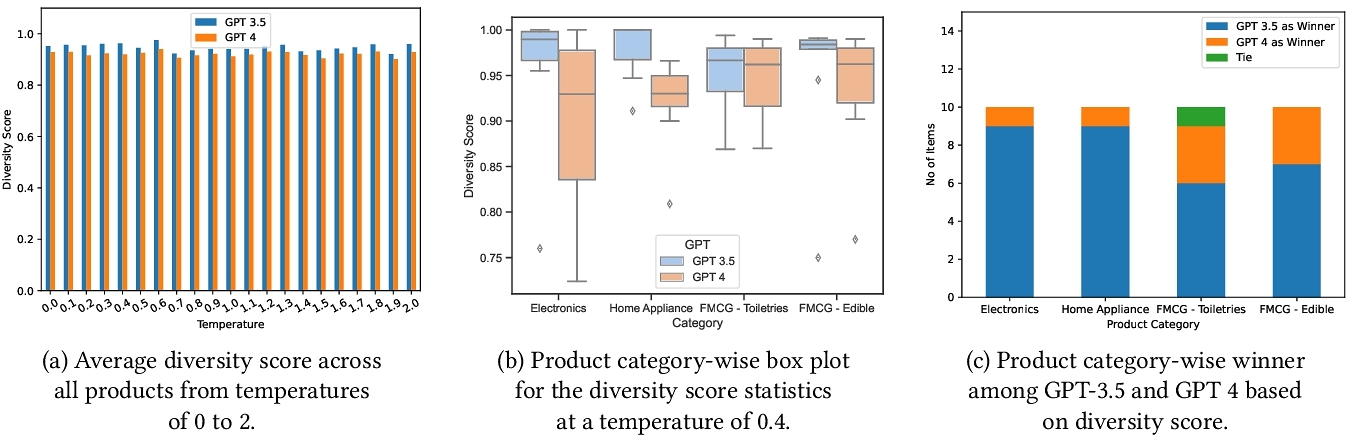
Next, we focused on temperature 0.4 for diversity comparison between GPT-3.5 and GPT-4. GPT-3.5 consistently showed higher diversity scores. Box plots in Figure 2(b) highlighted this, affirming GPT-3.5’s superiority in delivering diverse recommendations over GPT-4 across various statistics.
Now, we perform the diversity score comparison in terms of the number of product items in each category where each of GPT-3.5 and GPT-4 models give more recommendation. This comparative plot is shown in Figure 2(c), which again clearly depicts the superiority of GPT-3.5 compared to GPT-4 in terms of providing more diverse recommendations.
Also, we perform another experiment. Sometimes, if the original search term from the user is slightly rephrased, the diversity in the recommendations might improve significantly. We perform this analysis on some product term searches and our hypothesis proves to be true, as shown in Table 2.
| Product Name | GPT-3.5 Score | GPT-4 Score | Alternative Name | GPT-3.5 Score | GPT-4 Score |
|---|---|---|---|---|---|
| Printer | 0.76 | 0.733 | Stylish printer | 0.956 | 0.822 |
| Gaming Console | 0.733 | 0.711 | Cool Gaming Console | 0.956 | 0.922 |
| Soap | 0.911 | 0.867 | Body Soap | 0.978 | 0.911 |
| Shampoo | 0.889 | 0.889 | Hair Cleanser | 0.933 | 0.922 |
| Cookies | 0.8 | 0.756 | Biscuits | 0.84 | 0.84 |
Table 2 shows that for many of the product search terms, like ’Cookies’, GPT-4 model recommendations show a lower diversity compared to GPT-3.5.
4 CONCLUSION
This work provides an experimental framework to evaluate multiple LLMs in terms of diversity in their recommendations. It shows that GPT-4 might be superior in terms of providing more optimal recommendations and results in general but, at least in the context of diversity of retail products, GPT-3.5 surprisingly turns out to be superior. Further, it would be interesting to do more such analysis in different other product domains.
REFERENCES
- 2023. https://www.statista.com/topics/2843/home-appliance-industry-in-the-us/#topicOverview.
- 2023. https://www.statista.com/topics/2103/household-products/.
- Amazon. 2023. https://www.amazon.com/.
- Bonappetit. 2023. https://www.bonappetit.com/.
- Epicurious. 2023. https://www.epicurious.com/.
- Wenqi Fan, Zihuai Zhao, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Jiliang Tang, and Qing Li. 2023. Recommender Systems in the Era of Large Language Models (LLMs). CoRR abs/2307.02046 (2023). https://doi.org/10.48550/arXiv.2307.02046
- Ignacio Fernández-Tobías, Paolo Tomeo, Iván Cantador, Tommaso Di Noia, and Eugenio Di Sciascio. 2016. Accuracy and Diversity in Cross-domain Recommendations for Cold-start Users with Positive-only Feedback. In ACM Transactions on Interactive Intelligent Systems. 119–122. https://doi.org/10.1145/2959100.2959175
- Foodnetwork. 2023. https://www.foodnetwork.com/.
- David Holtz, Ben Carterette, Praveen Chandar, Zahra Nazari, Henriette Cramer, and Sinan Aral. 2020. The Engagement-Diversity Connection: Evidence from a Field Experiment on Spotify. In EC ’20: Proceedings of the 21st ACM Conference on Economics and Computation, Vol. 13. 75–76. https://doi.org/10.1145/3391403.3399532
- Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian J. McAuley, and Wayne Xin Zhao. 2023. Large Language Models are Zero-Shot Rankers for Recommender Systems. CoRR abs/2305.08845 (2023). https://doi.org/10.48550/arXiv.2305.08845
- Business Insider. 2023. https://www.businessinsider.in/business/.
- Marius Kaminskas and Derek Bridge. 1966. Diversity, Serendipity, Novelty, and Coverage: A Survey and Empirical Analysis of Beyond-Accuracy Objectives in Recommender Systems. In The measurement of diversity in different types of biological collections. Journal of Theoretical Biology., Vol. 13. 131–144. https://doi.org/10.1016/0022-5193(66)90013-0
- Bart P. Knijnenburg, Martijn C. Willemsen, Zeno Gantner, Hakan Soncu, and Chris Newell. 2012. Explaining the user experience of recommender systems. In User Modeling and User-Adapted Interactio, Vol. 22. 441–504. https://doi.org/10.1007/s11257-011-9118-4
- Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Xiangyang Li, Chenxu Zhu, Huifeng Guo, Yong Yu, Ruiming Tang, and Weinan Zhang. 2023. How Can Recommender Systems Benefit from Large Language Models: A Survey. CoRR abs/2306.05817 (2023). https://doi.org/10.48550/arXiv.2306.05817
- Mintel. 2023. https://www.mintel.com/.
- Nestle. 2023. https://www.nestle.com/brands/.
- Nielsen. 2023. https://www.nielsen.com/us/.
- Nozzle.ai. 2023. https://www.nozzle.ai/insights/a-quick-guide-to-profitable-amazon-keyword-research.
- Oberlo. 2023. https://www.oberlo.com/statistics/most-popular-electronics.
- United States Department of Justice.2018. In The measurement of diversity in different types of biological collections. Journal of Theoretical Biology., Vol. 13. 131–144. https://doi.org/10.1016/0022-5193(66)90013-0
- Pepsico. 2023. https://www.coca-colacompany.com/brands.
- P&G. 2023. https://us.pg.com/brands/.
- E.C. Pilou. 1966. In The measurement of diversity in different types of biological collections. Journal of Theoretical Biology., Vol. 13. 131–144. https://doi.org/10.1016/0022-5193(66)90013-0
- Scott Sanner, Krisztian Balog, Filip Radlinski, Ben Wedin, and Lucas Dixon. 2023. Large Language Models are Competitive Near Cold-start Recommenders for Language- and Item-based Preferences. CoRR abs/2307.14225 (2023). https://doi.org/10.48550/arXiv.2307.14225
- Unilever. 2023. https://www.unilever.com/brands/.
- Liang Zhang, Quanshen Wei, Lei Zhang, Baojiao Wang, and Wen-Hsien Ho. 2020. Diversity Balancing for Two-Stage Collaborative Filtering in Recommender Systems. Applied Sciences 10 (2020), 1257. https://api.semanticscholar.org/CorpusID:213771645
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from permissions@acm.org.
AIMLSystems 2023, October 25–28, 2023, Bangalore, India
© 2023 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 979-8-4007-1649-2/23/10.
DOI: https://doi.org/10.1145/3639856.3639896