FoodNet: Simplifying Online Food Ordering with Contextual Food Combos
DOI: https://doi.org/10.1145/3493700.3493728
CODS-COMAD 2022: 5th Joint International Conference on Data Science & Management of Data (9th ACM IKDD CODS and 27th COMAD), Bangalore, India, January 2022
Bundling complementary dishes into easy-to-order food combos is vital to providing a seamless food ordering experience. Manually curating combos across several thousands of restaurants and millions of dishes is neither scalable nor can be personalized. We propose FoodNet, an attention-based deep learning architecture with a monotonically decreasing constraint of diversity, to recommend personalized two-item combos from across different restaurants. In a large-scale evaluation involving 200 million candidate combos, we show that FoodNet outperforms the Transformer based model by 1.3%, the Siamese network based model by 13.6%, and the traditional Apriori baseline by 18.8% in terms of NDCG, which are significant improvements at our scale. We also present qualitative results to show the importance of attention and lattice layers in the proposed architecture.
ACM Reference Format:
Rutvik Vijjali, Deepesh Bhageria, Ashay Tamhane, Mithun T M, and Jairaj Sathyanarayana. 2022. FoodNet: Simplifying Online Food Ordering with Contextual Food Combos. In 5th Joint International Conference on Data Science & Management of Data (9th ACM IKDD CODS and 27th COMAD) (CODS-COMAD 2022), January 8–10, 2022, Bangalore, India. ACM, New York, NY, USA 8 Pages. https://doi.org/10.1145/3493700.3493728
1 INTRODUCTION
Online food ordering platforms are commonplace globally. The diversity of customers makes personalization on such platforms a challenge. For instance, the food flavors and preparation styles vary over relatively short distances. Similarly, customers’ taste, dietary and affordability preferences also vary widely. For a given individual, the dietary preferences may be occasion-specific. Health-conscious individuals may stick to a low-calorie diet over weekdays and yet indulge in ice creams or pizzas over the weekends. Amidst such diverse individual preferences, it is challenging yet important to personalize customer experience on our platform that offers thousands of restaurants with millions of dishes. For example, in a 60-day A/B experiment on our platform, we observed a 3% drop in orders per device and a 2% increase in searches in the non-personalized, popularity variant vs. the personalized variant. Despite food ordering being a high-intent activity, personalization can still make a significant difference at our scale.
Customers typically first select a restaurant and then find complementary dishes on the menu to create a meal (for example, Curry and Rice) on our platform. Further, it may take multiple restaurant menu visits to lock in on a meal (henceforth referred to as a combo). Given this non-linear customer journey, simply personalizing the restaurant listings is not enough. Traditional cross-selling approaches cannot work either, because most of them require the customer to explicitly provide context by first finding a relevant restaurant and then selecting at least one dish. Recommending bundles (combos of dishes in our case) can simplify the ordering journey [4][8][9][10][17]. Pre-existing combos form <10% of all dishes on our platform. These combos are typically hand curated by restaurants based on popular dishes and personalising them to customer tastes is not scalable. For example, while Curry and Rice are popular and frequently ordered together, a customer may prefer a Garlic Naan and Curry from a given restaurant.
In this paper, we propose FoodNet, an attention-based deep learning architecture to recommend personalized two-item combos from different restaurants. While we infer customer context from their recent order history, we also show that capturing the diversity of orders (hence encoding exploratory behavior) is important. For instance, a customer who explores new dishes in every order cannot be shown combos only based on their order history. To solve this, we add a monotonically decreasing constraint of diversity to the user history, while also using dish and restaurant features in conjunction. To train this model, we use the set of combos from millions of past orders (we use carts and orders interchangeably). For inference, the candidate list is a set of a) pre-curated and other two-item combos historically ordered by the customers, and b) two-item combos created by arbitrarily combining dishes from larger carts. Our main task therefore is to rank this extended candidate list personalized to the customer context. Note that for the scope of this paper, we only consider repeat customers since the scope for and ROI from personalization is the highest in this group.
As an illustrative output from FoodNet, Figure 1 shows the top combo (Pizza and Garlic Bread) recommended to a customer given the recent sequence of their orders (timestep t-1 being the most recent). Since FoodNet has an attention unit, we can explain which parts of the user history the model gave higher weights to. The thickness of the solid lines indicates attention weights for the various orders in user history. We observe that the user had ordered Pizza and Garlic Bread individually before, and the same dish families (or dish categories) also happen to be the top-selling ones for the given restaurant. Note that the suggested combo was never actually built or ordered by the user before, but was chosen from several candidate combos ranked across different restaurants.
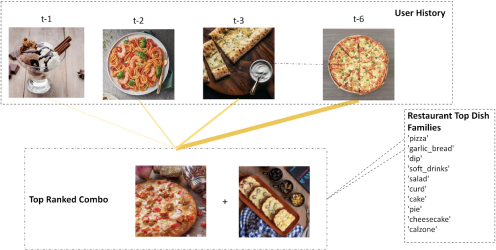
Our contributions are as follows. First, we show that FoodNet not only significantly beats the traditional Apriori baseline but also improves upon Siamese network and Transformer based approaches. Second, we present an ablative study where we show the impact of adding various feature heads, attention unit and monotonic constraints on the NDCG of the ranked list of combos. Third, we show qualitative inferences from analyzing the recommended combos by inspecting historical orders and visualizing the attention scores.
2 RELATED WORK
A related task within recommendation systems [1][7][14] is to infer relationships between different products so that the recommendations are in line with the customer context [1][2][3][6]. For instance, if a customer is looking at Rice Bowls, then showing other Rice Bowls similar to what the customer is looking at makes sense. Such a relationship is referred to as substitutability of products. On the other hand, if a customer has already added a Rice Bowl to the cart, cross-selling a Coke makes more sense than recommending similar Rice Bowls. For such recommendations, inferring a complementary relationship is more important than substitutability. Several approaches have been proposed to infer such product relationships, including topic models [1][2], embeddings [3][5][6], graph-based methods [1][16] and deep learning [17][18].
While such approaches help recommend either substitutes or complementary products through the learned relationships, another body of work is to recommend bundles (referred to as combos in this paper) of products together [4][8][9][10]. The goal here is to not only sell multiple products together but also to simplify the customer journey by packaging products into combos [9]. This is synonymous with a fast-food chain selling combos having Burgers, Fries, and Coke. We focus on combos comprising complementary products since the goal here is to recommend combos that reflect a pre-curated meal customized for the customer. Several approaches have been explored in the past for creating such combos, including the well-known Apriori algorithm [11] and its variants that essentially mine products that are frequently purchased together. Though such approaches are simple and scalable, they miss the critical aspect of personalization.
More recent approaches have focused on generating personalized combos using deep learning architectures [8][10]. Unlike these approaches, we train our models using mined combos from past carts created on our platform and personalize the ranking. As described in Section 3, such a formulation helps us to rigorously evaluate our approach on large-scale historical data using relevance metrics like Normalized Discounted Cumulative Gain (NDCG) and Mean Reciprocal Rank (MRR). Mining from previously available combos has been explored in the past [4][15], however, the authors do not employ a constraint based deep learning architecture for scoring the combos. To the best of our knowledge, the proposed approach of adding a monotonic constraint of user history diversity to an attention based architecture is novel for food combo recommendation, as well as for the general task of bundle recommendation.
3 TRAINING AND EVALUATION DATA
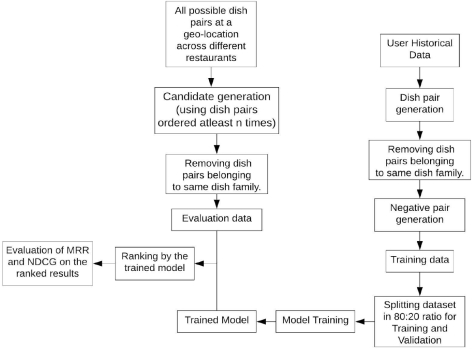
Customers on our platform generate millions of carts, where a given cart represents a list of dishes. Before we can explain the pre-processing steps, we briefly explain a few nuances around our data. In this paper, we are mainly concerned with ranking combos consisting of exactly two dishes, since two-dish combos are the most popular on our platform. However, a significant percentage of historical carts in our dataset do contain more than two dishes. Since our model scores dishes in a pairwise fashion, we generate training data by creating multiple combinations of two-dish pairs from the original carts. Secondly, multiple dishes may belong to the same dish category. For example, a single restaurant may offer different kinds of pasta. However, the exact dish name may vary. We rely on our in-house food taxonomy to provide a way to categorize the dishes. We call such a category the ‘Dish family’. For instance, both white-sauce pasta and red-sauce pasta will map to a dish family ‘Pasta’. Similarly, the carts typically also contain dishes from multiple dish families. Since we are explicitly solving for meal combos, we prune carts based on the dish family. That is, we explicitly filter out carts where both the dishes map to the same dish family. The remainder of the two-dish carts acts as positive samples (labeled 1). We obtain negative samples by replacing any one dish in the cart with a random dish belonging to the same restaurant (labeled 0) for a given customer. Using randomly sampled carts from other users as negative samples, was another approach we tried and discarded. Our intuition is that this approach introduces more noise and does not help learning. After pruning and negative sampling, we further sample about 2 million data points for training.
We use multiple features across customers, restaurants, and dishes as input to our model. For each training sample, we collect names and dish families of each of the dishes added to the cart. We also collect the user's history (history before the specific training sample to avoid data leakage) as an array of previously created carts. Each historical cart in itself corresponds to an array of dish family categories. All the dish families belonging to a cart are encoded as 1, and the rest as 0. Such a feature encoding allows our model to take into account the sequence in which the carts have been created by the user, and also encode each created cart in the sequence as a fixed length embedding. Each restaurant has its specialty of dishes, and capturing this information is vital to learning about the restaurant. Hence, we add the top 10 most popular dish families ordered from the restaurant over a 2 month period, as features.
We use the carts created and dishes ordered from a dense geographical area within a large city in India as our evaluation dataset. We then generate a set of all possible two-dish combos using the same pruning strategy used to construct the training set. Our total evaluation set consists of about 200 million <dish pairs, user history, restaurant features> triplets. For each sample in this set, there is a target label (0/1) that indicates whether the given dish pair was added to cart by the user.
4 FOODNET
In this section, we discuss multiple baseline approaches and compare them with the proposed FoodNet architecture.
4.1 Baselines and Feature Heads
4.1.1 Straw-man Approach. Apriori [11] is an algorithm for frequent item-set mining and association rule learning over transactions. Confidence score is one way to measure association. We pre-calculated the confidence score for different item pairs using our training dataset. During evaluation, for each cart, we use this confidence score and rank the item pairs in decreasing order of their scores.
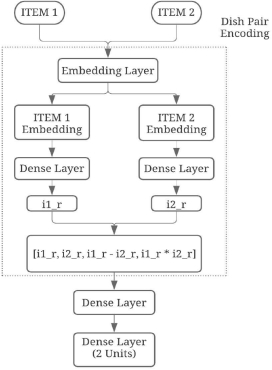
4.1.2 Siamese Dish Pair. Siamese networks are effective in identifying complementary items [18]. To embed dish pairs, we use a subword tokenizer [13] to convert dish names to unique numerical representations and feed this to a common embedding layer. That is, both dish names are embedded by shared weights. For each dish name item 1 and item 2, we take the average of the embeddings of all tokens of each dish to get final representations i1_r and i2_r respectively. We then concatenate the two embeddings while also augmenting by taking the absolute difference and element-wise product of the two. This combined representation helps the model converge faster as complementary behavior between embeddings can be captured more efficiently by pre-computing these operations[17]. We then pass this combined representation through a dense layer followed by a final output softmax layer as shown in Figure 2.
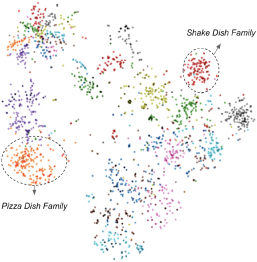
We visualize the embeddings of a few dishes, learned from the dish names alone, using a tSNE plot as shown in Figure 3. This plot is colored based on the dish family the dish belongs to. We can see that the learned representations are such that similar dishes are clustered together in this space. The Pizza cluster circled in orange consists of dishes like cheese-burst pizza and margarita pizza while the Shake cluster circled in red consists of dishes like chocolate thick shake, strawberry milkshake, etc. We can see that the dishes in these two clusters are closely spaced and the clusters are well separated. Complementary behavior is likely captured in the dense layers after concatenation of the dish embeddings. However, there are errors in some clusters, likely because dish names alone are not sufficient to discern their differences.
4.1.3 User History Head. Although the Siamese model is tuned to capture complementary behavior, it is not personalized. In order to add personalisation, we aim to capture user's ordering patterns by using their cart history. Bi-LSTMs are effective as they model sequences in both forward and backward directions. Our objective is to model user preferences through this encoding of sequences.
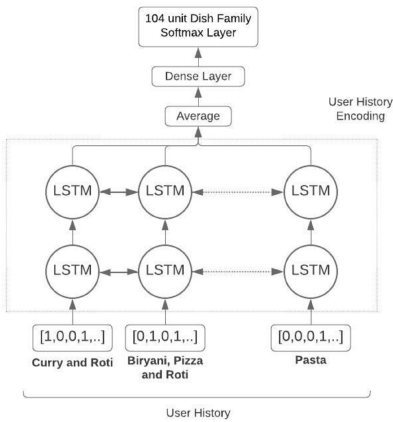
In order to validate the efficacy of this head, we experiment with training a sequence model with the user history in terms of the dish family added to the cart. We encode each user cart as a fixed length array where all dish families added to cart are ones and the rest are zeros. We also experiment with encoding each dish family as a separate embedding and take the mean of all to represent the cart. We train this head to predict the next dish family that the user will add to the cart given the user's historical record of the carts’ dish families. We trim this record to about 104 most frequently ordered dish families at the output node and train the model with the architecture as shown in figure 4. As shown in the figure, we finally use the one hot encoding of dish families instead of using an embedding layer and averaging, as the former approach gives us marginally better results with a lesser number of training parameters. We use a stacked two-layer Bi-Directional LSTM[12] with 256 hidden units, and a final output head with 104 neurons and softmax activation.
This model achieves nearly 60% improvement in accuracy on an unseen validation set when compared to the baseline of the user's “most preferred” dish family from historical sessions. This verifies our hypothesis that a sequential model such as this can understand the user's preferences for a certain dish family(s) given the user's history.
4.1.4 Restaurant Features Head. In our data, we also observe that users’ ordering patterns are also dependent on the restaurant's features, primarily, ‘what dishes does the restaurant serve well?’. Hence, the final user preferences are a combination of what the user likes and what the restaurant serves well. We capture this by using the restaurant's top 10 dish families by order volume as measured over a 2 month period. These features are encoded into a 128-dimension vector using a single dense layer with ReLu activation. From our experiments we verify that a single dense layer is sufficient because restaurant features are cross-sectional in nature and a shallow NN is easily able to encode this information.
4.2 Composite architectures
We propose a few composite architectures based on the feature heads described so far. First, we collect results using the Siamese architecture taking dish pairs as input. As shown previously, this Siamese Dish Pair model learns representations that encode complementarity of dishes. Second, we use the user history features as encoded using Bi-LSTMs in Figure 4, along with the Siamese Dish Pair model to add personalization. We refer to this architecture as Siamese Dish Pair+UH(Bi-LSTM). Finally, we add the restaurant features and use all features together to create the Siamese Dish Pair+UH+RF model. In addition to this, we also experiment with an attention based transformer instead of Bi-LSTM to encode user sequences, we refer to this model as Siamese Dish Pair+UH(Transformer). We show in Section 5 that this transformer based user history encoding performed poorly in comparison to Bi-LSTM in terms of NDCG and MRR. We hypothesise that Bi-LSTM works well for our use-case as the length of user's history is at most 20 while the transformer based networks are shown to work better than LSTMs primarily for longer range interactions[19]. Hence, for our final model architecture (FoodNet) we evaluate and show results with Bi-LSTMs for encoding user history.
4.3 FoodNet
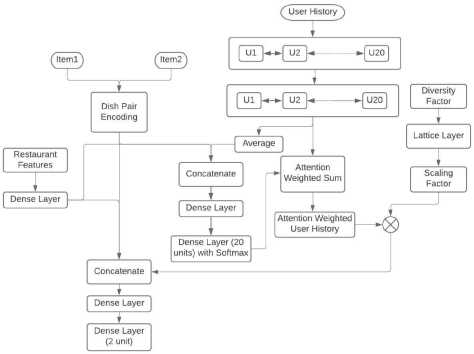
We propose two key additions to the Siamese Dish pair+UH+RF. We note that in the Siamese Dish pair+UH+RF model, the user history representation would give equal weightage to the hidden states of each timestep in user history, since it takes a simple average over all hidden states. However, if the user history representation was cognizant of dish pairs and restaurant features, it could potentially have assigned different weights to individual timesteps. To model this, we add an attention unit to the Siamese Dish pair+UH+RF model model.
Here, a concatenated representation of unweighted user history, dish pair representation, and restaurant feature embeddings are used to generate attention scores that are then multiplied element-wise with the user history to weigh each timestep. The updated user history representation is now a weighted average of each timestep. These attention values can be visualized and add a layer of explainability to our model.
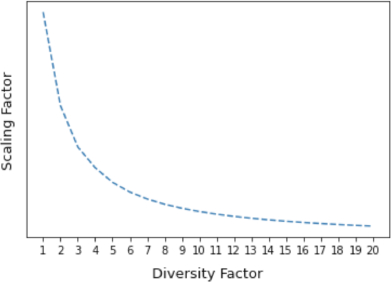
While the attention scores capture the differential importance of time steps in user's history, they don't quite capture the aspect of diversity (or entropy) in user behavior. That is, a section of users predominantly explore instead of mostly repeating what they have ordered before. Essentially, this means that the user's historical order behavior carries less information when the user's order diversity is high. To model this, we add ‘diversity factor’ as a feature. Diversity factor is defined as the ratio of the number of unique dish families ordered and the total number of orders. Higher diversity factor indicates that the model must pay lesser attention to the user's history and vice versa. We add this feature as input to the Tensorflow Lattice layer[20] and set the constraint to be monotonically decreasing. This ensures that an appropriate decreasing function is learned, as shown in Figure 5, instead of manually defining a suboptimal scaling factor. We call this final architecture FoodNet, as shown in Figure 6.
4.4 Training and Inference
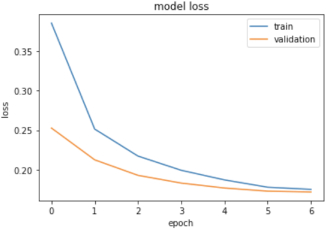
Our dataset of 2M samples is split in a 80-20 ratio for training and validation. All the architectures were trained and optimized for offline metrics of AUC and PR-AUC and experimented with various regularization techniques and parameters. A dropout rate of 0.5 was added to all the dense layers. All weight matrices were randomly initialized using Xavier initialization and an Adam optimizer with a learning rate of 2e-4 was used to train the model with softmax cross-entropy loss. The loss convergence plots are as shown in Figure 7.
For inference, as mentioned earlier, we create the candidate set of dish pairs from a dense geographical area. In order to control the cardinality of possible combos, we apply pruning based on the rules discussed in section 3. We also further filter on combos that have been ordered at least n times in the last 1 month's time, for final candidate generation. These candidate samples are ranked by the proposed models and this ranked list of combos is then used for evaluating the models as discussed in Section 5. Training and inference flow is as summarized in Figure 8.
5 EVALUATION AND RESULTS
We rank the candidate combos based on the probability scores as inferred by the various architectures described. Popularity-based ranking is our naive baseline while the Apriori is a more credible baseline. The goal is to compare the ranked lists generated by each of these architectures in terms of relevance to the user. We evaluate the rankings at a session-level since the user history changes over time. For every session, we know the actual cart created by the user. We mark possible combos from all such carts as relevant for the corresponding sessions, for the given customer. Correspondingly, we calculate the position of these relevant carts in each of the ranked lists to obtain the MRR and NDCG metrics.
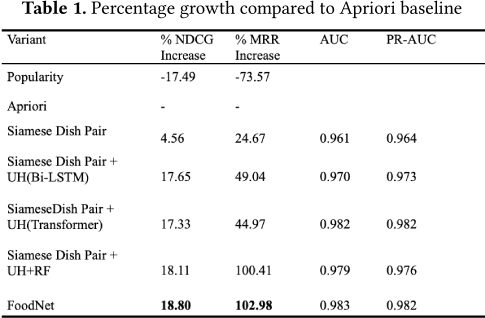
Table 1 shows results when the model was trained from scratch (randomly initialized) across the different architectures described in Section 4. We note that the additional context information of user history and restaurant features improve the performance of the model, reaffirming that personalization helps in the overall ranking for combo suggestions. We also note that FoodNet is the best performing model overall in terms of both NDCG and MRR. It also has the highest AUC and PR-AUC. We can also see that the attention unit and diversity scaling in FoodNet has not only helped us add explainability to the model but also in improving NDCG over the Siamese Dish pair+UH+RF model. In comparison to the Siamese Dish Pair baseline model, FoodNet achieves a lift of 13.6% in NDCG.
For high-diversity users, (i.e., diversity factor >=4), we see a 1.1% lift in NDCG with FoodNet vs. the Siamese Dish Pair+UH+RF model. This is likely due to the constraints enforced by the diversity scaling. We show some qualitative samples in the next section.
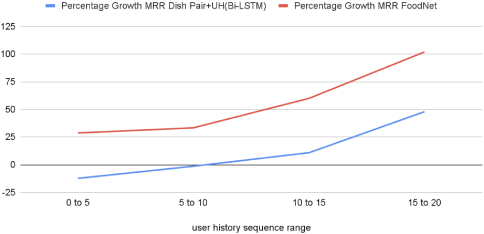
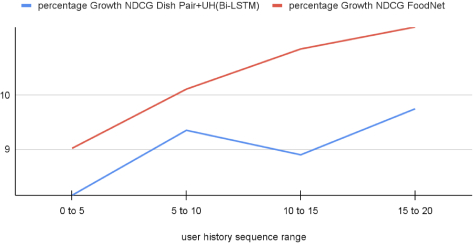
We also observe that the length of the available user history impacts the model performance. Figure 9 and Figure 10 show percentage growth in MRR and NDCG compared to the Siamese Dish Pair model as a function of bucketed user history sequence length. Both NDCG and MRR improve as the number of orders in the user history increases. At the highest point (15-20), we see over 11% lift in NDCG and nearly 100% lift in MRR as compared to the Siamese Dish Pair model that doesn't take any user history as input.
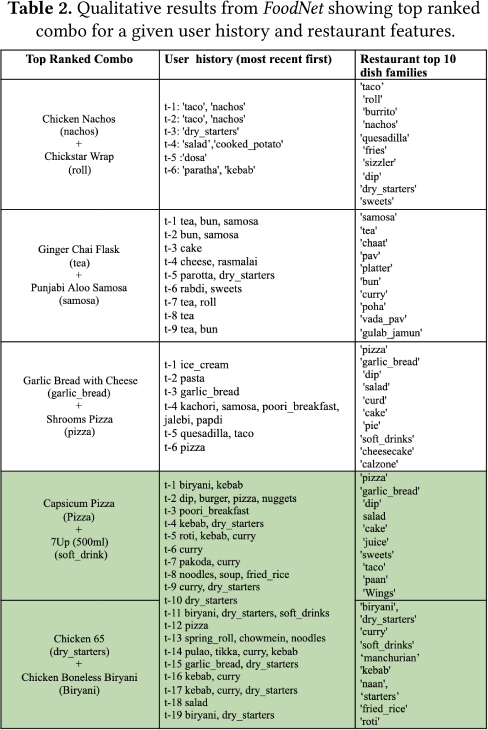
5.1 Qualitative Analysis
We look at a few top-ranked combos from FoodNet and qualitatively analyze them. As can be observed from Table 2, the top-ranked combos intuitively make sense given the user history as well as the restaurant's top 10 dish families. The last two highlighted combos show up as top recommendations for the same user. For this user, FoodNet highly ranked two widely different combos. One of them is a Pizza and 7Up combo, which likely stems from the fact that pizza is popular for that restaurant and it was ordered by the user recently (t-2). The second combo is a Biryani and an apt chicken starter for this dish, Chicken 65. This is likely due to the fact that the user's recent history contains Biryani and the restaurant's top dish families are Biryani and dry starters.
As discussed in Section 1, we can visualize the user history weights using the attention score to understand which parts of the user history the model pays more attention to. In Figure 11, we show the attention weights from the last two examples in Table 2 and visualize how the attention scores vary for the same user depending on context. The red bar represents the attention scores for each historical timestamp for the pizza-softdrink combo and the green bar represents the same for the biryani-starter combo. We can see that for the biryani-starter combo, the model paid high attention to orders that contained biryani and other starter items. Correspondingly, for the pizza-softdrink combo, the model had high attention weights for pizza. This confirms our hypothesis that the model weighs user history based on the combo it's scoring for. We can also see that there are relatively high peaks for history consisting of curry in red and salad in green, even though these dish families don't exist in the combo. This is likely because these dish families are top dish families for the restaurants of their corresponding sessions. This shows that both the user history and restaurant features are weighed while computing attention values.
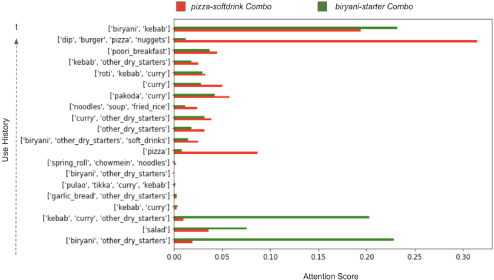
We also show some contrasting ranking samples from FoodNet vs. the Siamese Dish Pair+UH+RF model for users with high diversity.
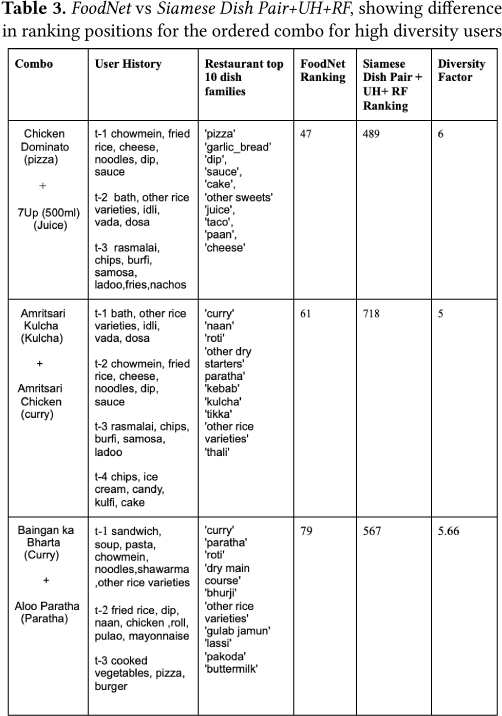
As shown in Table 3, for all these users, order history was widely diverse. FoodNet ranks the valid sample (which was actually ordered) much higher compared to the Siamese Dish Pair+UH+RF model because the contribution of user history was scaled down owing to the high diversity in them.
6 CONCLUSION
In this work, we discussed the problem of personalized food combo recommendation. We introduced FoodNet, a deep learning model that recommends two-item combos from across different restaurants. To the best of our knowledge, our approach of coupling attention with a monotonic constraint of diversity to encode exploratory behaviour is novel for food combo recommendation, as well as for the general task of bundle recommendation. We experimented with several architectures and showed that FoodNet outperforms Siamese and Transformer baselines, apart from the traditional Apriori approach. We discussed how the proposed approach not only performs better, but also adds a layer of explainability using attention. Finally, we show a few qualitative examples to drive home the effectiveness of FoodNet for ranking personalized combos.
In future, we plan to extend FoodNet to more than two dish combos. This would involve generating positive and negative three dish combos from user carts and adding a third input layer. This new architecture could essentially supersede the current FoodNet model when the third input is padded for two dish samples and trained with an approach similar to the one described in this paper. We also plan to compare the current discriminative architecture with a generative approach using architectures like GANs. Further, we plan to leverage FoodNet for recommending complementary dishes when an explicit context has been provided by the customer. Since the current architecture supports scoring pairs of dishes, use cases like cross-sell can easily employ the same architecture.
REFERENCES
- Julian McAuley, Rahul Pandey, & Jure Leskovec. (2015). Inferring Networks of Substitutable and Complementary Products.
- Huasha Zhao, Luo Si, Xiaogang Li, & Qiong Zhang. (2017). Recommending Complementary Products in E-Commerce Push Notifications with a Mixture Model Approach.
- Zhang, S., Yin, H., Wang, Q., Chen, T., Chen, H., & Nguyen, Q. (2019). Inferring Substitutable Products with Deep Network Embedding. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19 (pp. 4306–4312). International Joint Conferences on Artificial Intelligence Organization.
- Pathak, A., Gupta, K., & McAuley, J. (2017). Generating and Personalizing Bundle Recommendations on Steam. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 1073–1076). Association for Computing Machinery.
- Aditya Mantha and Yokila Arora and Shubham Gupta and Praveenkumar Kanumala and Zhiwei Liu and Stephen Guo and Kannan Achan (2019). A Large-Scale Deep Architecture for Personalized Grocery Basket Recommendations. CoRR, abs/1910.12757.
- Wan, M., Wang, D., Liu, J., Bennett, P., & McAuley, J. (2018). Representing and Recommending Shopping Baskets with Complementarity, Compatibility and Loyalty. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (pp. 1133–1142). Association for Computing Machinery.
- Park D, Kim K, Kim S, Spranger M, Kang J. FlavorGraph: a large-scale food-chemical graph for generating food representations and recommending food pairings. Sci Rep. 2021 Jan 13;11(1):931. doi: 10.1038/s41598-020-79422-8. PMID: 33441585; PMCID: PMC7806805.
- Ashutosh Kumar and Arijit Biswas and Subhajit Sanyal (2018). eCommerceGAN : A Generative Adversarial Network for E-commerce. CoRR, abs/1801.03244.
- Elaine M. Bettaney, Stephen R. Hardwick, Odysseas Zisimopoulos, & Benjamin Paul Chamberlain. (2019). Fashion Outfit Generation for E-commerce.
- Bai, J., Zhou, C., Song, J., Qu, X., An, W., Li, Z., & Gao, J. (2019). Personalized Bundle List Recommendation. In The World Wide Web Conference (pp. 60–71). Association for Computing Machinery.
- Agrawal, R., & Srikant, R. (1994). Fast Algorithms for Mining Association Rules in Large Databases. In Proceedings of the 20th International Conference on Very Large Data Bases (pp. 487–499). Morgan Kaufmann Publishers Inc.
- Alex Graves, & Jürgen Schmidhuber (2005). Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks, 18(5), 602-610.
- Taku Kudo, & John Richardson. (2018). SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing.
- W. Min, S. Jiang and R. Jain, ”Food Recommendation: Framework, Existing Solutions, and Challenges,” in IEEE Transactions on Multimedia, vol. 22, no. 10, pp. 2659-2671, Oct. 2020, doi: 10.1109/TMM.2019.2958761.
- Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2009. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI ’09). AUAI Press, Arlington, Virginia, USA, 452–461.
- Ayala, V.A., Cheng, T., Alzogbi, A., & Lausen, G. (2017). Learning to Identify Complementary Products from DBpedia. LDOW@WWW.
- Yen-Liang Lin and Son Dinh Tran and Larry S. Davis (2019). Fashion Outfit Complementary Item Retrieval. CoRR, abs/1912.08967.
- Angelovska, A. (2021). Siamese Neural Networks for Detecting Complementary Products. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop. Association for Computational Linguistics.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, & Illia Polosukhin. (2017). Attention Is All You Need.
- Seungil You, David Ding, Kevin Canini, Jan Pfeifer, & Maya Gupta (2017). Deep Lattice Networks and Partial Monotonic Functions. In NIPS.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from permissions@acm.org.
CODS-COMAD 2022, January 08–10, 2022, Bangalore, India
© 2022 Association for Computing Machinery.
ACM ISBN 978-1-4503-8582-4/22/01…$15.00.
DOI: https://doi.org/10.1145/3493700.3493728