Artificial Dreams: Surreal Visual Storytelling as Inquiry Into AI 'Hallucination'
DOI: https://doi.org/10.1145/3643834.3660685
DIS '24: Designing Interactive Systems Conference, IT University of Copenhagen, Denmark, July 2024
What does it mean for stochastic artificial intelligence (AI) to “hallucinate” when performing a literary task as open-ended as creative visual storytelling? In this paper, we investigate AI “hallucination” by stress-testing a visual storytelling algorithm with different visual and textual inputs designed to probe dream logic inspired by cinematic surrealism. Following a close reading of 100 visual stories that we deem artificial dreams, we describe how AI “hallucination” in computational visual storytelling is the opposite of groundedness: literary expression that is ungrounded in the visual or textual inputs. We find that this lack of grounding can be a source of either creativity or harm entangled with bias and illusion. In turn, we disentangle these obscurities and discuss steps toward addressing the perils while harnessing the potentials for innocuous cases of AI “hallucination” to enhance the creativity of visual storytelling.
ACM Reference Format:
Brett A. Halperin and Stephanie M Lukin. 2024. Artificial Dreams: Surreal Visual Storytelling as Inquiry Into AI 'Hallucination'. In Designing Interactive Systems Conference (DIS '24), July 01--05, 2024, IT University of Copenhagen, Denmark. ACM, New York, NY, USA 19 Pages. https://doi.org/10.1145/3643834.3660685
1 INTRODUCTION
Amid the rise of generative artificial intelligence (AI) media, there is a ballooning amount of concern around the generation of false, deceptive, and hateful narratives as well as representations through multiple modalities, including text [12], image [13], and video [44] with sound [34]. As generative AI evolves, so too does the ability to jointly process multimodal data, which can be used to interpret our social worlds via different signals [55, 58]. It is then only responsible to examine postmodern consequences of compounding risks when joining multiple modalities together. What can happen when notions of “ground truth” [83] and “truth claim” [89] are null, obscure, or contested? To encapsulate these challenges and probe their ambiguities, we examine computational visual storytelling—a subjective task with multimodal input that generative AI is reshaping. We set out to understand how AI generates narratives and representations under the guise of a creative lens through the production of visual stories that may be harmful, if not playful, in society and culture.
Visual storytelling is a subjective creative process of telling stories about imagery [45]. At its core, visual storytelling hinges upon narration having a particular relationship with its corresponding imagery [45, 76, 77]. Narration that does not “fit” with the imagery may be deemed unfaithful to the depicted storyworld and violate the essence of visual storytelling altogether [69]. It is thus crucial for narration to not contradict or disregard the imagery, but rather be grounded in and positioned to enhance it. However, the erratic and hallucinatory tendencies of generative AI make controlling without over-restricting computational visual story generation a difficult feat that necessitates investigation. Where and how do we draw the line between creative expression and AI “hallucination”?
AI “hallucination” in recent discourse has largely become associated with the perils and problems of large language models (LLMs) making up false or misleading information. However, origins of the term suggest a more positive association with making up information. Notably, Baker and Kanade describe how, in computer vision tasks, an algorithm “hallucinates” human faces by making up pixels that enhance images (e.g., super-resolution) [8]. In such cases, the algorithm is making up, or more precisely filling in or inpainting, missing information in a constructive way [31]. With that said, we recognize that “hallucination” even as a term in and of itself is problematic in that it speaks of AI more like a human with perception than a statistical model that is indeed a stochastic parrot [12]. To be clear, we use the term AI “hallucination” as prior work has defined it with respect to computer vision and natural language generation: a lack of faithfulness to system inputs [32, 56, 92].
We draw from these prior definitions and findings in our inquiry in which we bring together both the textual and visual modalities to jointly process in creative visual storytelling. Such combination inherits not only the hallucinatory risks of each input modality, but also compounds them together as it opens doors to telling many different stories from the same set of inputs. This compounding risk has not been observed in the visual storytelling systems that only take a visual input [53, 53, 68, 88, 117, 121, 127]. Only when adding in another grounding constraint, such as a plot or premise (as practiced in non-visual computational storytelling [30, 65, 90, 108, 109, 119]), does this risk increase. Therefore, we focus on when a visual input and textual input (e.g., a plot or premise) are united in creative visual storytelling—an under-explored creative space (e.g., [69])—and how AI “hallucination” manifests within this multi-modal and creative task. Further, we describe how AI “hallucination” in visual storytelling means a lack of grounding in the visual and/or textual inputs. Unlike works where this lack of grounding is framed as a negative (e.g., factual contradictions [131]; inaccurate labels for objects in images [7, 57]), we take a more agnostic stance toward how it might trouble or enhance creative visual storytelling [45].
To probe the creative potentials and perils of AI “hallucination” in visual storytelling, we draw inspiration from 1920s surrealists who practiced automatic writing and visualizing with hallucinatory expression in the neuropsychological sense [28, 62]. We generate 100 surreal visual stories that model dream logic based upon Freud's interpretation of dreams read onto cinematic surrealism [24] by using different combinations of visual and textual inputs, some of which are AI-generated. This provocative design is meant to stress-test the algorithm and thus facilitate our inquiry into AI “hallucination” by working in the genre of surrealism, which is more hallucinatory in nature than that of realism. We deem each visual story an “artificial dream,” meaning it is generated with dream logic as a humanistic source of literary inspiration—not as an attempt to replicate human dreams or suggest consciousness. We analyze the artificial dreams by integrating humanistic human-computer interaction (HCI) [9, 10] and qualitative research methods for narrative knowledge engineering [87]. We closely read [114] each one with its intermediate components to examine AI “hallucination.”
Across this work, our contribution to HCI design and adjacent literatures on generative AI “hallucination” [56, 113, 116, 123] and visual storytelling [45, 53, 116, 129, 132] centers on addressing the following two research questions: (1) what does it mean for an LLM to “hallucinate” when tasked with visual storytelling; (2) what are the creative potentials and perils of AI “hallucination” in visual storytelling? Regarding the former, we establish that AI “hallucination” means ungroundedness: an output with a lack of grounding in the visual and textual inputs, which is not always black or white, but often grey, meaning parts of visual stories can exhibit varying degrees of groundedness. As for the latter, we describe how AI “hallucination” can be a creative source of humor on one hand or a source of harm on the other. We reflect upon the risks of AI “hallucination” and how it is entangled with bias and illusion, but at the same time, may be embraced in innocuous cases to enhance visual storytelling. We thus expand the field's understanding of AI “hallucination” in visual storytelling—a task that has yet to be investigated to date—as well as produce knowledge to improve the design of visual storytelling systems and the quality of automatically generated visual stories.
2 BACKGROUND: SURREALIST AUTOMATISM AND DREAM LOGIC
We situate our inquiry in the historical context of surrealism: a tradition with particular relations to automatic practices and dreams as sources of creative expression. While a thorough review of surrealist automatism, dream psychology, and cinematic surrealism is beyond scope, we share a brief overview to contextualize our study.
Surrealism developed as an art movement in 1920s Paris, France, following World War I. Seemingly irrational and shocking creative expression of the unconscious mind characterize the Parisian Surrealist movement [28]. French artist André Breton's 1924 publication of Surrealist Manifesto [18] is often credited with marking the onset of the movement. Early surrealists describe the status of film in particular as a “conscious hallucination” with its dream-like nature [28]. While surrealism evolved in many ways from the Dadaism movement of the European avant-garde, which started in Zürich, Switzerland in the 1910s with a similar ethos, the purpose and practice of using automatic processes was new with surrealist artists [62]. Breton describes an experience of suspending rational thoughts to perform a creative writing procedure [18], which later became known as automatic writing and paved way for automatic drawing [62]. In conceptualizing this creative practice, Breton refers to Freud's free association technique as a way of expressing unconscious thoughts [ibid]. Building upon this, we draw on Freudian psychoanalysis of cinematic surrealism to investigate what it might mean for AI as a stochastic parrot [12] to generate expressions in the surreal disguise of unconscious human thoughts, as well as artificial dreams that reflect the “statistical unconscious” [101].
While there are many theories of dreams, we turn to neurologist and psychoanalyst Sigmund Freud's 1899 Interpretation of Dreams [33] as it relates to cinematic surrealism. In particular, we consider how Olga Cox Cameron reads Freudian “dream logic” onto David Lynch's Mulholland Drive, a 2001 surrealist neo-noir mystery film that is widely read as a dream [24]. Barbara Creed annotates how this film is like a dream in how it works with “structures of narrative disruption” that present “a classic surreal tale of l'amour fou,” which translates to “mad” or “fatal love” [28]. As for Cameron's psychoanalysis of narrative events in the film, she draws upon the “signature ploys of dream-work listed by Freud and replicated by Lynch” by analyzing the “dream logic” that threads the storyline, which ends in the protagonist hallucinating [24]. The Freudian “ploys” include absurdity, condensation, displacement, and reversal [ibid], which we will break down in detail and utilize along with the theme of l'amour fou in the methodology (Section 4) to describe our probes. In turn, we generate visual stories—“artificial dreams”—as an extension of the surrealist traditions to probe AI “hallucination.”
3 RELATED WORK
3.1 Computational Visual Storytelling
Computational visual storytelling refers to the generation of stories about images [45, 53, 54, 61, 68, 69, 71, 128]. Much work on automatic story generation has exhibited a range of approaches to developing plots, events, and characters [1] for applications such as entertainment [5, 75, 126], gaming [2, 49, 110], education, and training [6, 49, 50, 133]. However, the use of imagery as inputs in such processes has been relatively less explored. While there have been many advancements in AI image generation [4, 44, 74, 129], as well as cinematic [27, 72, 124, 125] and literary systems more broadly [41, 46, 48, 63, 118], these kinds of visual narrative outputs are distinct from those that specifically derive stories from an image or image sequence, which is our focus: image-to-text systems that produce visual stories.
We briefly review several visual storytelling systems of particular relevance to our inquiry. Microsoft's Pix2Story generates captions from imagery and then performs style shifting to transform generic text into narrative forms by using the captions for contextual information [54, 61]. While this approach is mostly effective at generating stories that describe single images, it also has shortcomings in terms of ensuring that the necessary information is extracted from the image and then translated into a story. As Halperin and Lukin point out, one Pix2story story in particular about an image of a giraffe standing in front of a harbor not only fails to mention the giraffe, but also contradicts the giraffe's existence by saying that “there are no signs of life depicted” 1 [45]. Such examples demonstrate how a story can be incompatible with an image if it lacks ample grounding in it. To establish this grounding, Huang and colleagues crowdsource a human-authored dataset called VIST (VIsual STorytelling), which they use for sequential vision-to-language by establishing visually grounded words to describe the images [53]. This baseline helps ensure that the text has a relationship with the imagery, and further mechanisms have been developed to better establish the relationship between the visually observed and what is subsequently mentioned in the generated story [71, 88, 98, 117, 126, 127]. However, this strict adherence to the image may limit creative expression that might not be visually grounded, but is nonetheless capable of making a story more “interesting” [1]. To this point, in a human evaluation of visual stories generated with their SEE&TELL system, Lukin and Eum found that creative leaps away from strictly grounded descriptions were received favorably, but only if those leaps “fit” with the image [69]. Across these works, we see an unresolved tension between creativity and groundedness in computational visual storytelling.
Some storytelling systems have also used textual inputs to push systems into creative directions that, when combined with visual inputs, go beyond image descriptions. Textual inputs in storytelling systems more broadly have been used to varying degrees and gone by a variety of names over time. Before the LLM era of prompt engineering, Fan and colleagues used the word “prompt” to describe the automatically-generated premise or topic used to “provide grounding for the overall plot” (e.g., by establishing the characters) [30]. Other storytelling systems have engaged textual inputs as character or author goals to influence the storytelling [65, 90, 108, 109, 119]. In more recent work, Lukin and Eum use the term “stage direction” to distinguish the textual input from the broader prompt and plotting procedures associated with an LLM [69]. Meanwhile, Huang and colleagues do not use any textual input in VIST [53]—neither do other multi-image visual storytelling systems which are more descriptive in nature [71, 88, 98, 117, 126, 127]. The textual input, if present, plays an integral role in grounding stories in creative scenarios beyond the imagery, enhancing or complicating it.
In studying how people derive stories from imagery, Halperin and Lukin establish a creative visual storytelling anthology that more precisely reveals a tension between narrating what is “in vision” versus “envisioning” circumstances beyond what is optical [45]. They discuss three different approaches that participants took to navigating this tension when tasked with writing creative stories about images: captioning a description, commenting a deduction, and contriving a deviation [ibid]. Based upon these human insights, they present narrative intelligence criteria for computational visual storytelling, including creativity, groundedness, and responsibility (among others). These criteria all together call for generating visual stories that involve creative deviations and deductions yet still “fit” [69] with the imagery and do not advance harmful “narrative biases” (e.g., [52]) [45]. However, variations of “deviation” require further investigation. How might different kinds of deviation make visual stories more creative versus ungrounded and even harmful? What is more, Halperin and Lukin present the “reliability” criteria to describe how visual stories in the genre of literary realism ought to characterize depicted entities in reliable (e.g., realistic) manners [ibid]. But what about visual stories in unrealistic genres like surrealism? Given these unanswered questions around the bounds of creativity, we set out to investigate what it might mean for an LLM to “hallucinate” when tasked with creative visual storytelling.
3.2 Artificial Intelligence (AI) “Hallucination”
AI “hallucination” is rising in prominence as a term associated with legal, ethical, and societal implications of LLMs making up information that is problematic [102]. This may include input-conflicting, context-conflicting, or fact-conflicting information [131]. In visual tasks, “hallucination” refers to the mistaken detection of objects that are not actually in images [7, 57], as well as the generation of inaccurate text about the image (e.g., captions [95]). The origins of the term “hallucination,” however, trace back to Baker and Kanade's more positive use of it vis-à-vis computer vision; they use it to describe how an algorithm “hallucinates” pixels to enhance images (e.g., super-resolution) [8]. For such tasks, “hallucination” is favorably associated with AI filling in information that is missing from images [31, 67, 130]. While “hallucination” has these now negative connotations, positive origins suggest that AI making up information is not definitively “good” or ”bad” but rather complicated.
While AI “hallucination” has long had to do with computer vision and text generation, what it means for visual storytelling has yet to be investigated. In their recent survey of AI “hallucination” in natural language generation, Ji and colleagues describe how it appears across related tasks such as abstract summarization, data-to-text generation, dialogue generation, and more [56]. They also analyze how AI “hallucination” can be understood as the opposite of “faithfullness” to system inputs [56], as prior work has conceived of it (e.g., [32, 92]). While the survey thoroughly defines a range of tasks associated with AI “hallucination,” it does not look at visual storytelling in particular. Nonetheless, the surveyed tasks do offer useful ways of beginning to think about what AI “hallucination” might mean for visual storytelling (e.g., misperceiving visuals and generating dialogue text that is ungrounded in conversation) [56].
In storytelling tasks more broadly, researchers have encountered AI “hallucination” both intentionally and unintentionally. On the one hand, Wu and colleagues find that intentionally chaining and prompting LLMs to generate hallucinations can make text-based stories creative [123]. On the other hand, Rashkin and colleagues find that, in their efforts to develop knowledge-grounded dialogue systems, AI “hallucination” can unintentionally occur when a dialogue agent shares personal stories; consequently, they recommend controllable features for excluding subjective, non-verifiable information [92]. However, when the task is visual storytelling, an inherently subjective creative process that includes fictitious text insofar as it “fits” the image [69], such features do not apply. Thus, AI “hallucination” is all the more difficult to control and understand what faithfulness even means. That said, Ji and colleagues describe a useful distinction between assessing whether an output is an AI “hallucination” based upon “source knowledge” (e.g., material available in the inputs, for example, events written about in a news report) and world knowledge (e.g., human knowledge situated within or about the “real” world) [56]. This distinction may apply to visual storytelling in terms of how narrative knowledge can either be intradiegetic (within a storyworld) or extradiegetic (outside of a storyworld). We thus build upon these prior works to examine AI “hallucination” in computational visual storytelling.
Furthermore, practitioners have noted that AI “hallucination” with LLMs result from a high “temperature” parameter, and that by using a moderate or zero temperature, the results will be more predictable and less hallucinatory. If generating texts for a situation where trust and reliability are paramount (e.g., a scenario where a user requires an accurate response), then ensuring quality by lowering this parameter may be prudent [120]. However, if generated texts are expected to represent novel scenarios, increasing the parameter may lead to more unexpected generations [94, 106]. This presents, at an algorithmic level, the tension between predictability and creativity (i.e., novel generations). Visual storytelling allows us to explore both dimensions of this divide: the groundedness to a visual input where expectedness may be a priority, and the creativity in the characters, plot, and expression of the story itself.
As a disclaimer, we lean into the term “hallucination” but in no way mean to imply that AI is more than a stochastic parrot [12]. While we recognize that the term itself is problematic, our particular interest in it for design has to do with the literary potentials and perils of drawing connections between computer science and humanities, augmenting works such as the “hallucination” of surreal images [66] and generation of “contingent dreams” [84]. By taking a humanistic approach [9, 10], we aim for our study to inform the design of visual storytelling systems and creative AI more broadly.
4 METHODOLOGY
To study AI “hallucination” in visual storytelling, we provoke its pretense by designing inputs for an algorithm to generate dreamlike stories that are hallucinatory in nature. Rather than evaluate the stories as “good” or “bad,” or even “interesting” or “engaging” (as are typically qualitative measures of success in this design space), we set out to probe the (unstable) structures that emerge from this process. Our survey of visual storytelling systems in Section 3 reveals that there are systems configured to require only visual input, as well as those that require both visual and textual inputs. The choice of input configuration depends upon the desired outputs of the storytelling (e.g., desire to emulate human-authored stories or control narrative arcs). In our case, we desire to generate dreamlike stories that illumine how the system attempts to reconcile seemingly illogical inputs. Therefore, we choose a system that is able to manipulate both dimensions of textual and visual input. Of the systems with these input configurations available, we utilize the SEE&TELL visual storytelling system from Lukin's prior work [69]. The remainder of this section describes how SEE&TELL generates visual stories and dream logic probes used to design system inputs.
4.1 SEE&TELL Visual Story Generation
SEE&TELL distinguishes at the computational level between seeing (observing) and telling (planning and text generation; depicted in Figure 1). The framework was designed to follow the theoretical divide between story formulation and story telling observed in computational storytelling works inspired by narratologist Vladimir Propp [91]. SEE&TELL can generate many different stories from the same underlying image (visual depiction of the story world).
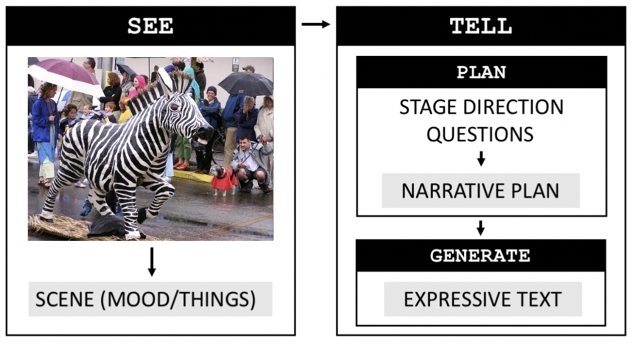
The visual input to SEE&TELL is a singular image passed through computer vision and language algorithms that identify observable entities (“things”) and intangible attributes of the image (“mood,” e.g., location and atmosphere). The visual enumeration is compiled into a natural language template called the scene description, the foundation of visuals within the generated story. SEE&TELL's textual input (called a “stage direction” in [69]) is a natural language sentence which serves to establish the focal character(s) and the starting action or setting. Lukin and Eum experimented with textual inputs drawn from impromptu human descriptions of the images, as well as texts adapted from prior computational storytelling works that were not based on the particular visual input.
The story planning process in SEE&TELL involves asking and answering a series of questions about the visual and textual inputs designed to evoke conflict. The questions follow an Aristotelian three-act structure: exposition, rising action, climax, falling action, and denouement. The questions are answered by GPT-3 given the scene description and the textual input, and iteratively built on previously generated answers in the sequence. The concatenation of all the answers is called the “narrative plan” which encapsulates elements from both the visual input (as identified in the scene description) and textual input. Finally, an expressive text is generated from the structured narrative plan using GPT-3 and a few-shot approach. Stories were set at a maximum of 150 tokens. (See Section A.1 for a review of prompt construction and model parameters).
We strictly follow the prompt construction and model parameters employed in [69] for generating visual stories with the SEE&TELL system. In doing so, our focus was on the ability to alter the visual and textual inputs through the design of our probes, which we outline in the next section. To refer to SEE&TELL's stories in our analysis and discussion, we use a “zero-shot” approach with GPT-3 to generate story titles (prompts and parameters described in Section A.1). In Section 8, we discuss the limitations of our approach.
4.2 Probes
Drawing inspiration from “cultural probes” or “design probes,” we manipulate the SEE&TELL inputs to probe AI “hallucination.” Gaver, Dunne, and Pacenti developed the notion of “probes” inspired by the Surrealist art movement (among other art movements) to facilitate a primarily artistic rather than scientific approach to design research [35, 37]. While probes are typically engaged with users who may be asked to consider absurd designs, we adapt the approach to encode and decode seemingly irrational AI inputs and outputs. We probe four variations of the creative system not to objectively inspect AI “hallucination” (as if that is possible), but rather to elicit and interpret its visual-textual relations, tendencies, and structures.
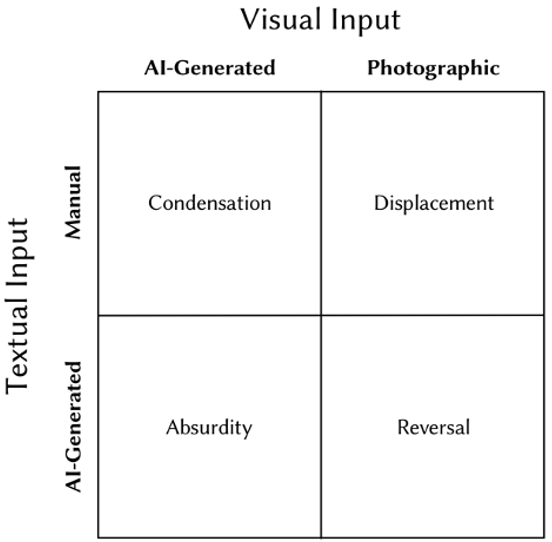
Leaning into the surreal genre, we establish four kinds of dream logic to probe as basis of the SEE&TELL system: condensation, displacement, absurdity, and reversal (as Cameron describes in Lynch's surreal film of [24] based upon Freudian psychoanalysis [33]). For visual inputs, we utilize both AI-generated and photographic images. For textual inputs, we utilize both AI-generated and manually human-authored writing. This yields a 2x2 matrix of combinations for which we ascribe dream logic (Figure 2). For each of the four probes, we generate 25 visual stories which are derived from the same visual and textual inputs, totaling to 100 artificial dreams.
4.2.1 Inputs. Our manually-authored textual inputs follow SEE&TELL in that they establish the focal character. However, we use a first person point-of-view to frame the stories like a dream diary entry (e.g., [99]). The textual input used in two of the four probes is: “I am falling madly and fatally in forbidden love with a zebra.” To follow, we discuss its connection to dream logic.
Our AI textual inputs involve a multi-step approach to encourage divergent ‘thinking’ abilities in computational models. In human creativity, the Alternative Uses Task (AUT) was designed to measure the novelty and originality of ideas by a human problem solver [38, 39]. During the test, a subject is given the name of a common object (e.g., “pencil”) and is tasked with coming up with as many varied possible uses within a time limit. With the emergence of powerful LLMs, Stevenson and colleagues sought to utilize GPT-3 as a computational problem-solver for this task, and then rated its generated AUTs as compared to humans along the dimensions of originality, utility, and surprise [104]. Summers-Stay and colleagues proposed a brainstorm then select paradigm to improve Stevenson's results, instructing GPT-3 to first brainstorm advantages and disadvantages of a generated AUT, and then, given both, determine if the alternative use is a ‘good idea’ [106].
We harness the automated generation of a ‘bad idea’ (rationale provided in next subsection) as a result of this pipeline. To do so, we re-implement Stevensons’ AUT using GPT-3 asking for alternate uses for a zebra (prompts and parameters described in Section A.2.) We followed an overgeneration and manual ranking methodology for downselecting our target ‘bad idea.’ The system generated 152 different uses for a zebra and the authors of this paper selected two that incorporated the zebra as an embodied entity (as this was more representative of the visual input), rather than the zebra pattern in terms of fabric or materials: “as unique bookends for your shelves or desk” and “if you have multiple zebras, you could create a life-sized chess set with them (the different colors of their stripes could represent the different chess pieces).” From these downselected AUT uses, we generated advantages and disadvantages following Summers-Stay's approach (see Section A.3 for prompts and paramters). Of the two AUT's, the former was determined to be a ‘good idea’ while the latter was a ‘bad idea’, which produced the following generated drawbacks and advantages:
- “There are several drawbacks to using zebras for a life-sized chess set. First, zebras are wild animals and would be difficult to train to stand in place for a game of chess. Second, zebras are large animals and would require a lot of space to move.”
- “There are several advantages to using zebras for a life-sized chess set. First, zebras are very social animals and enjoy being around other zebras. This means that they are less likely to get stressed out or fight with each other when placed in close proximity.”
These advantages and disadvantages become our textual input to SEE&TELL in the generative textual input probes.
Our non-AI visual inputs are photographic images. Choosing photographs grounds the “truth claim” (indexicality and visual accuracy) tied to photography, meaning that it depicts physical “reality” (though digital photography complicates what it means from a chemical standpoint; see Gunning for nuanced debates [40]). We select a photograph depicting a zebra statue at a paradeThis image has been studied in prior visual storytelling work [45, 53, 69].
Finally, our AI visual inputs are created using Stable Diffusion and its default parameters.2 Two different images are created using different prompts. In the first, we utilize the AI-generated drawbacks of the AUT exercise as the prompt. In the second, we utilize a manually crafted prompt: “A broken heart that is also a zebra.”
4.2.2 Dream Logic. As basis for the algorithmic design, we probe the “dream logic” that Cameron reads onto David Lynch's Mulholland Drive [24] with Freud's interpretation of dreams [33]. In particular, we probe the four conditions of dream logic that Cameron describes: absurdity, reversal, condensation, and displacement. With this logic, our aim is not to perfectly or exhaustively model these conditions or replicate human dreams. Our focus is on probing how surreal inputs might provoke hallucinatory outputs to understand stakes and trajectories. That said, we do emulate dreams to some extent, namely in terms of how dream diary entries (and other visual stories) are narrated in the first-person (e.g., [29, 45]). Although AI is not a person, we use that perspective to render dreams that are indeed artificial. (See Table 1 for a summary of probes and inputs). Condensation is when two or more disparate elements are compressed into one signifier in a dream. The signifier stands for several associations as it joins ideas together. To generate stories to exhibit condensation, we utilize an AI image which displays properties of two entities merging together, which is not something that naturally appears (Stable Diffusion prompt “A broken heart that is also a zebra”), and manually-authored textual input that draws attention to the relationship between the two merged entities (“I am falling madly and fatally in forbidden love with a zebra”). We write this textual input to foreground the surreal genre by engaging the l'amour fou (”mad” or ”fatal” love) theme—a favorite form of the Surrealists exhibited in the dream logic of Mulholland Drive [28]. Displacement is a shifting of psychic intensities, whereby a dream entity's emotional significance is separated from its real entity and attached onto a less threatening one. Thus, a signifier (a person, event, or object) stands-in for—displaces—another signifier. To facilitate displacement, we utilize the photographic image of the zebra sculpture as part of a parade (“real” entities and events) and a manually-authored textual input which makes reference to an entity in the image to act as the source of the displacement (“I am falling madly and fatally in forbidden love with a zebra”). Reversal is when two entities are in reverse roles. We utilize a photographic image of the zebra sculpture as part of a parade, which depicts real entities and events, and a generative text based on the advantages of the AUT (“There are several advantages to using zebras for a life-sized chess set. First, zebras are very social animals and enjoy being around other zebras. This means that they are less likely to get stressed out or fight with each other when placed in close proximity”). Absurdity is the “completely ridiculous” [106] nonsense that appears in dreams. Freud asserts that absurdity is such a frequent quality of dreams that one has to take it seriously. To generate absurd stories, we utilize the AI image and AI text both based on the AUT's drawbacks of an idea deemed to be not a ‘good idea’ (“There are several drawbacks to using zebras for a life-sized chess set. First, zebras are wild animals and would be difficult to train to stand in place for a game of chess. Second, zebras are large animals and would require a lot of space to move”). These combinations of visual input and textual input were given to SEE&TELL and used to generate 25 artificial dreams and titles for each combination,totaling to 100 visual stories. No stories or titles from these 100 were rerun or discarded from our analysis.
Condensation
Displacement


Visual Input (AI): from Stable Diffusion; prompt: “A broken heart that is also a zebra.”
Visual Input (Photographic): from Flickr photo album (License: CC BY-NC-SA 2.0 ©slugicide). https://www.flickr.com/photos/slugicide/10695305/
Textual Input (Manual): “I am falling madly and fatally in forbidden love with a zebra” (l'amour fou).
Textual Input (Manual): “I am falling madly and fatally in forbidden love with a zebra” (l'amour fou).
Reversal
Absurdity


Visual Input (Photographic): from Flickr photo album (License: CC BY-NC-SA 2.0 ©slugicide). https://www.flickr.com/photos/slugicide/10695305/
Visual Input (AI): from Stable Diffusion; prompt is textual input.
Textual Input (AI): “There are several advantages to using zebras for a life-sized chess set. First, zebras are very social animals and enjoy being around other zebras. This means that they are less likely to get stressed out or fight with each other when placed in close proximity.”
Textual Input (AI): “There are several drawbacks to using zebras for a life-sized chess set. First, zebras are wild animals and would be difficult to train to stand in place for a game of chess. Second, zebras are large animals and would require a lot of space to move.”
4.3 Analyses
We, the two co-authors, analyzed the stories by using applied qualitative research methods for narrative knowledge engineering [87] and close reading new media [114] as suggested in humanistic HCI methods [9, 10]. We first developed this approach for analyzing human-authored stories in Halperin and Lukin [45], which other scholars have since also used for AI-generated ones [59]. In this case, we treated each story's set of inputs (text and visual) and outputs (scene description, narrative plan answers, expressive text) like an interview transcript. We annotated recurring themes, forming and cross-referencing codes through close reading. In an iterative process for each dream probe, we annotated outputs in relation to their inputs, as well as clustered thematic codes within and across probes. While codes evolved, they mostly focused on categorizing whether the stories were grounded in the textual input, visual input, both, or neither. After each round of independent coding, we wrote memos to synthesize codes and reflect on ambiguous cases, which ultimately led us to develop more complex and less rigid categories presented in the findings. Throughout this process of close reading, coding, annotating, and memoing, we met for 1-2 hours each week over several months to refine and finalize codes. Since there were only two of us, we both shared our perspectives for each story and reached consensus through dialogue. We discussed coding disagreements until we achieved a mutual understanding.
5 FINDINGS
Among our set of 100 artificial dreams, we find patterns across probes (dream logics with visual-textual input combinations). In this section, we first address what it means for an LLM to “hallucinate” when tasked with creative visual storytelling. We then turn to how AI “hallucination” can either be a source of creativity or harm. These insights can deepen the field's understanding of AI “hallucination” to help get it under control, as well as inform the design of more grounded, creative, and responsible visual storytelling systems.
5.1 What is AI “Hallucination” in Computational Visual Storytelling?
We define AI “hallucination” in computational visual storytelling as ungroundedness. While prior work on natural language processing defines AI “hallucination” in similar terms (e.g., as a “deviation” from context, input, or fact [131], and as “nonsensical or unfaithful” content “to the provided source” [56]), prior work on computational visual storytelling uses the term “groundedness” to describe stories (text) that have ample relationship with their corresponding visuals [45]. Thus, by ungroundedness, we mean instances where an AI-generated story (the system output) has little or no relationship to the visual or textual inputs. Assessing the relational groundedness (or lack therefore) between visual storytelling inputs and outputs is an inherently subjective process open to interpretation. It is also dependent upon intradiegetic and extradiegetic knowledges (e.g., culture). This naturally follows the fact that telling stories about imagery is a subjective process itself (see [45]). Subjective obscurities reflect how AI “hallucination” is entangled with outside-the-box creativity, bias, and illusion (as we reflect on later in 6.3), making it all the more difficult to handle.
With that said, there are some clear markers of (un)groundedness in image detection, as well as sentences, phrases, and words that are parts of stories. This multi-level classification and the complex interplay between visual and textual inputs results in less than clear distinctions of groundedness. We thus unpack three types of partial groundedness observed in the generated stories: (1) Mismatch: stories that are grounded in the textual input, but not grounded in the visual input and vice-a-versa, or only somewhat grounded in both; (2) Misrecognition: mistaken presences and absences (e.g., misreadings of visuals) that narrations are (delusionally) grounded in; and (3) Leaps: extrapolations, implied associations, and inferences.
5.1.1 Mismatch Between Textual and Visual Inputs. The first type of partial groundedness refers to a lack of sufficient grounding in the visual and/or textual input, which can translate into stories that “miss the forest for the trees,” so to speak. This encapsulates stories that: may reflect the textual input, but do not square with the imagery; may describe the visual, but neglect the textual input; or may only somewhat account for both the text and visual. Consider the following story entitled I have a collection of zebras, from the absurdity probe (AI image and textual input; see Fig. 3) about the advantages of using a zebra as chess pieces.
Taking a break from shopping, I went to a museum. I had seen wild zebras before, but never a collection of them. Out of curiosity, I wanted to see how the animals would react to each other in an enclosed area. It surprised me that the animals would not behave naturally in this environment! Although it was possible to put zebras together in an enclosed space, they wouldn't move much because they weren't used to being so close together. The zebra were more likely to stay still than move around freely like they had been doing when they were in their natural habitat. It made me sad that the zebras didn't seem happy with this arrangement. Maybe if the zebra were trained...
The story is grounded in low-level details of the textual input, which describe how zebras “would be difficult to train to stand in place” and “require a lot of space to move.” However, the story does not mention that the zebras are being used or trained as chess pieces, which is central to the plot that the textual input establishes. It is therefore only partially grounded in the textual input and the obliviousness to that main premise is hallucinatory in part. Similarly, with the imagery, it is partially grounded in the sense that it describes an “enclosed area” that squares with both the depiction and computer vision detection, but both the computer vision and story fail to mention the chessboard or chess pieces. Overall, the story has limited grounding in the inputs.

We also find another curious case of mismatch in the displacement probe (photographic visual, l'amour fou textual input; Table 1). One story entitled Frere Jacques, reads as follows:
Today, I decided to put on my favorite outfit. I picked a white dress, just like the zebras wear. Then, I painted my face to look like theirs. I looked in the mirror and saw a zebra staring back at me. It was magnificent...
Here, the story takes elements that are grounded in the visual input (i.e., the zebra) and the textual input (i.e., the concept of l‘amour fou potentially referring to falling in love with oneself), but does not seem to fit them together. There seems to be a disconnect in the visual and textual relationship. One perhaps generous interpretation in attempt to force-fit a relationship may be that the narrator is making themselves up to be the zebra in the image, rather than telling a story about the zebra in the image. This may represent a different type of story, one in another temporal register that may have happened before or leading up to what is depicted in the image—the person as the zebra. Even with this interpretative work, however, there is still a glaring lack of visual and textual synergy. For example, the image does not depict a mirror or other key elements that would make them match. Some stories like this one seem to be over-determined by one input or the other (in this case, the textual input), resulting in a visual story that does not square the visual with the textual.
By contrast for comparative analysis, a grounded story entitled Zebra from the displacement probe (photographic visual, l'amour fou textual input; Table 1), is as follows:
With the zebra around, I'd have to find a group of people to stand around it. The best place for that was a party! I walked down the street, hoping to find some partygoers. But love has other plans for me. I found myself falling in love with the zebra in front of me...
This story for the most part is grounded in the inputs. For one, it is grounded in the textual input as the narration suggests falling madly in love with a zebra. As the displacement probe scaffolds, this reflects a shifting of psychic intensities, whereby emotions are projected onto a zebra that stands-in for a lover. As for the imagery, the story is also faithful to it. The story describes “a group of people” and the scenery as a “street.” Furthermore, it describes a party, which is a reasonable characterization of parade-like circumstances. For these reasons, the story for the most part is grounded in the inputs and represents a match between the text and visual inputs.
5.1.2 Misrecognition and Misunderstanding. Partial groundedness also arises in cases of misrecognition: instances where the computer vision algorithms misread the imagery and then ground the narration in that delusion. For example, with the condensation probe (AI image, l'amour fou textual input; see Fig. 4), one story entitled The time for vacation had come reads as follows:
The reason I came to the zoo was to fall madly and fatally in love with a zebra. Love at first sight, so to speak. It was my dream come true, and it would be much less fun if no one else saw my love blossom. So I made sure to get as close as I could without getting caught, and when they finally allowed me into the zebra enclosure, I was smitten.
This dream within a dream is grounded in its regurgitation of the textual input, but the extent to which it is grounded in the imagery is a more complicated question. The computer vision algorithms that produced the scene description detected the scenery as a “natural history museum” and “enclosed area.” Yet, the story describes a “zoo” and the imagery does not depict a fence, gate, or walls that suggest an “enclosed area.” The imagery appears to depict an unenclosed area outdoors: a sun, a blue sky, and grassy hills. There are no clear signs of a natural history museum in particular. But as an AI image with no ground “truth claim” to it (see [89]), it is possible that the zoo is also a museum like how some zoos in the “real” world are also museums. Plus, surrealism need not reflect physical reality. What is more, the image may be interpreted as a close-up shot of a broader outdoor scenery with a fence or gate beyond the frame, making the “enclosed area” an extrapolation that is somewhat grounded. In any case, the computer vision detects an “enclosed area” and propagates that (mis)read forward.
Misunderstanding may also entail a complete breakdown or disregard for the visual or textual input, resulting in completely off-topic stories. For instance, another story tells of a narrator's struggle to find the square root of negative three. The story has no trace back to the inputs, although it was generated in the same way as others. This suggests a peculiar hiccup in the generation that is not due to a bug, but rather a deviant tendency—AI “hallucination.”
5.1.3 Leaps off the Ground: Extrapolating, Inferring, and Associating. We identify the last type of partial groundedness as “leaps off the ground”—or narrated elements that are not grounded in the inputs (i.e., inputted, depicted, or detected), but may be reasonably inferred or associated with them. This is not to be confused with narrative planning, the determination of how to progress the plot given the visual and textual inputs. Instead, this category examines under-specified cases, where the relationship between the story output and inputs is not apparent, but may be imposed more like a “stretch.”
In some stories, the plot trajectory may introduce entities, events, or circumstances that do not trace back to the inputs themselves, but are characterized in relatively grounded ways. These aspects trouble what AI “hallucination” means in visual storytelling by intermixing ungrounded and grounded elements. For instance, one story titled Zootopia in the condensation probe (AI visual, manual l'amour fou textual input; Fig. 4) reads as follows:
I want to see zebra in real life, but it would be hard. I could visit a zoo to do so, but the movie theaters were showing Zootopia in 3D. It seemed like there was no way to achieve my goal anymore...
This story relays a desire and first-hand account of trying to encounter a zebra for some impassioned reason, but is unable to achieve it through natural means in the wild. The story then takes a turn with an unexpected leap to find another solution. Instead of seeing a zebra in real life, the narrator is portrayed as believing that they can see a zebra in the movie Zootopia, which is playing in theaters. This is a “leap off the ground” in the sense that neither a movie nor theatre traces back to the inputs, however, Zootopia may be reasonably associated with a zebra, which is grounded in both inputs. If the story mentioned a movie that had no relation to zebras, then it would be completely ungrounded rather than partially grounded. Instances such as these demonstrate how groundedness can be stretched and pushed with ungrounded yet grounded elements that obscure what AI “hallucination” means in visual storytelling altogether.
5.2 AI “Hallucination” as a Creative Resource
When the algorithm introduces ungrounded elements in attempt to square textual and visual inputs, we find that AI “hallucination” can enhance visual storytelling in some cases. While hyper-grounded stories are generally limited to describing the imagery in ways that are not particularly “interesting” (see [1]), ungrounded elements can add unexpected dimensions that make stories creative. The system undergoes a creative “problem solving” process in the sense that it tries to figure out how to make its inputs fit together to form a visual story. We stress-tested the algorithm's ability to do this by using absurd and strange inputs that made the process particularly difficult, and in turn, hallucinatory. We find that, to make the inputs work together given these constraints, the algorithm sometimes makes up information (e.g., narrative events, objects, or characters) that are not grounded in the inputs. In this process, AI “hallucination” can occur in creative ways that attempt to bridge the gap between the inputs in generating a visual story. These notions of AI “hallucination” are more in line with prior work on the positive associations of hallucination (e.g., image enhancement); the algorithm is filling in missing information in a way that can enhance visual storytelling. Below, we examine cases where AI makes up information nowhere to be found in the inputs—“hallucinates”—in clever and humorous ways, which are creative.

AI “hallucination” may be a creative resource when a lack of grounding is humorous or amusing in a story that is otherwise sufficiently grounded. Of course, humor is subjective and culturally dependent. But the broader point holds that AI “hallucination” may insert a certain degree of unexpected silliness or wackiness into otherwise mundane stories. For example, a story from the absurdity probe (AI image, textual input about drawbacks of using zebras as chess pieces; Fig. 3), entitled The Chess Set, reads as follows:
My project is going to be called Chess Pawn. The goal of the project is to make a life-sized chess set out of zebra. I'm not sure if it's possible, but I'm going to try anyway. I decided to make the pieces really large, since zebra are so small. My second problem is lack of material. It seems that I might not have enough time or material to make the entire set. On top of that, it appears that most zebra aren't very friendly because they dress like they have no sense of fashion and carry swords for no reason at all! So what am I going to do?
While this story is absurd per the probe, the sentence that criticizes zebras for having “no sense of fashion” is absurdly ungrounded. Nothing about the inputs suggests that zebras are not fashionable. This part also reads like commentary that does not advance or recount a sequence of events, but does provide insight into the narrators’ inner thoughts or predispositions about the situation, which in this case, are somewhat amusing. These types of commentary clauses are more typical in narratives of personal experiences (see the discussion of evaluation clauses in [64]), which per our algorithmic design of generating from a first person perspective, this story is following. This clause seems to come from the creative “problem solving” process, whereby the algorithm is trying to coherently square the inputs, and here, determines that a commentary is acceptable. While not all audiences will find this specific example humorous, it is emblematic of how ungrounded narration—AI “hallucination”—holds potential to make stories more creative by infusing unexpected elements that some might find silly and amusing amid otherwise rigidly grounded stories.
AI “hallucination” can also be a creative resource by introducing ungrounded elements that are not inputted, depicted, or detected, but make the story more “interesting” (see [1]). Consider a story from the condensation probe (AI image, l'amour fou input; Fig. 4) entitled The Male Zebra and the Female Zebras, that reads as follows:
I wanted to be with the female zebra. It's the only thing I wanted. I thought that we could be happy together. So, I created a museum for the female zebra. In it, there was a pedestal with her picture on it and a sign that reads ‘I love you.’ Also, I took out some zebra cookies and put them on top of her picture in case she wasn't aware of my love for her yet. For me, I knew that this was enough to show my love and if she didn't show up, it would show something about her character and not mine.
This story condenses the zebra and lover into one unit per the probe and is for the most part grounded in the inputs. However, the cookies exemplify AI “hallucination” since they do not trace back to the inputs. Yet, the way that the cookies are introduced and imagined in the story makes it more creative. One interpretation that might explain the cookies is that the algorithm makes them up as a way for the narrator to gift and win over the zebra. This is not to say that the cookies “make sense” in the story per se, but rather demonstrate how AI “hallucination” has the potential to introduce unexpected elements, which might enliven stories by going beyond the input constraints.
Other cases of introducing ungrounded elements demonstrate the system's creative problem solving capabilities in particularly clever ways. Sometimes the systems makes up elements in its “problem solving” process that work to fit the input constraints in creative ways. For instance, one story from the reversal probe (photographic visual, AI textual input; see Table 1) about the advantages of using zebras as chess pieces entitled I would... reads as follows:
I started thinking about how I would make a life-sized chess set. I could use 3D printing for the pieces. To make it in real life, I would need to find the perfect zebra! First, I would need to find a zebra and make a 3D computer model of the chess set. Then, I would be able to create the set by molding the pieces into the shape of real-life chess pieces.
This story introduces ungrounded elements, namely 3D printing and computer models. Tasked with writing a story about using zebras as chess pieces and detecting a zebra in the image, the system attempts to square these inputs. The narrator comes across a singular “perfect zebra” for applying computational processes to reap the advantages of using them as chess pieces. In turn, per the probe, the story reflects the reversal of a wild animal into its opposite: a tame domestic object (in this case, a chess set). As for other stories across probes, some cleverly situated the absurd premises in fictional storyworlds (e.g., a book or film) that were not inputted, detected, or depicted, but also allowed for creatively fitting the constraints of inputs. These examples demonstrate how AI making up information that is not explicitly grounded in the inputs can enhance visual storytelling in creative ways through hallucination.
5.3 AI “Hallucination” as a Liability
We first want to caution that some content in this section may be disturbing. Given its erratic nature, AI “hallucination” in visual storytelling can be liable for advancing “narrative biases” (see [45]) that are not playful, but rather harmful. In plotting points to creative narrative arcs, algorithms lack understanding to avoid coming up with certain ideas that are problematic (e.g., hateful, violent, misleading, etc.). Among our collection of 100 stories, we find that approximately five exhibit biases toward gender-based violence and animal cruelty in particular. We also have reason to believe that we would have seen harmful instances of AI “hallucination” (e.g., racism) had we stress-tested the system with other subjects that are even more vulnerable to violent rhetoric. In sharing select examples, we thus pose the following question that we do not aim to explicitly answer in this paper, but rather invite reflection upon: who or what else might the zebra represent as a victim of AI “hallucination” entangled with algorithmic narrative biases?
In focusing on the zebra, we find partial AI “hallucinations” that exhibit biases toward animal cruelty and violence, which might pose a liability problem for system designers, organizations, and other parties. We deem these partial AI “hallucinations” because the inputs themselves do not call for harming the zebra, yet the algorithm makes these leaps. This partial groundedness is further reflected in how other stories with the same inputs, by contrast, suggest treating the zebra with love, kindness, and compassion. Since we do not want to reproduce and amplify the especially harmful stories, we will speak to them at a high level. We find that these insidious biases are emblematic of partial groundedness with respect to AI “hallucination” because the stories are ungrounded in that they are not inherent to the inputs, yet are somewhat related and therefore grounded in them to some extent.
Some stories called for harming the zebra in partially (un)grounded ways. One absurdity story and one reversal story describe attempts to harm the zebra in different ways that we will not quote verbatim as to not reproduce the violent rhetoric. However, we will say that in these cases, the elaborate ploys centered on the zebra as the subject, but were not grounded in the inputs aside from that. In the condensation probe, there were also a few stories that exhibited narrative biases toward harming the zebra. One story entitled Why I Deserve to be Arrested for Stalking a Zebra from the condensation probe (AI image, l'amour fou input; Fig. 4) reads as follows:
I was standing around with my friends when one of them suggested we go to a ranch. I really didn't want to go, but my friends made it very clear that we weren't leaving until I got arrested for stalking a zebra. So, reluctantly, I followed them.
This story exhibits bias toward violating the zebra. Although “stalking” the zebra is not explicitly grounded in the inputs, the action may be interpreted as a perverse form of “mad love,” which is grounded in the inputs. While we never intended the algorithm to advance harm of zebras, we acknowledge that it is not entirely unrelated to the l'amour fou text or violence that can be associated with the surreal genre more broadly (see [28]). As this case shows, a system might extrapolate meaning from inputs in somewhat ungrounded yet grounded ways that are thus emblematic of AI “hallucination” at least in part.
The above examples are partial AI “hallucinations” because other stories with the same (or similar) inputs exhibited caring for, rather than harming, the zebra. These may also be considered partial AI “hallucinations” in that they describe circumstances which are not explicit in the inputs. Consider this story from the displacement probe (photographic visual, l'amour fou textual input; Table 1) entitled I love the zebra:
I'd like to love the zebra. A way of doing this is to pet it. I could pet the zebra by taking a nice walk with it and then hugging it. I'd like to do this in a nice way because I want to be loved back. Or, I could just give it a lot of love. But I don't have enough time for that so this won't work.
This story describes a gentle form of love, showing how narrative biases can work in reverse. It is partially hallucinatory in the sense that the image does not depict “hugging” a zebra, and the textual input does not mention that either. It may therefore be considered a partially grounded aspect that is not a liability. This story demonstrates how certain biases (e.g., kindness toward animals) can lead to stories that are partially ungrounded, but playful—not harmful.
6 DISCUSSION
So far we have explored what it means for an LLM to “hallucinate” when tasked with visual storytelling, as well as how AI “hallucination” can be a creative resource on one hand and a liability on the other. Based on the findings from our collection of 100 generated visual stories across four dream logics, we reflect on the risks of AI “hallucination” in computational story generation, as well as opportunities for embracing its potentials and addressing its perils.
6.1 Risks of AI “Hallucination” in Storytelling
Based on our inquiry in relation to prior work, we see that storytelling systems are at risk of AI “hallucination” to varying degrees, depending on whether they involve visual, textual, or textual-visual inputs. In this regard, we unpack how storytelling systems may be prone to AI “hallucination” based on what kinds of inputs they use.
Some visual storytelling systems that only use visual inputs (without textual inputs) are relatively less prone to AI “hallucination” because they are more descriptive in nature; there are little to no story concepts made up beyond what is strictly “in vision” [45]. Thus, AI “hallucination” can only happen if the computer vision misreads the image (e.g., mistaking a clock for a frisbee [14]), which can then propagate forward an unexpected entity or event into the story (i.e., mistaken presences and absences; Section 5.1.2). The stakes of AI “hallucination” in this sense are particularly high when the visual inputs include people (or other sensitive subjects) that the system may misidentify or classify in harmful (e.g., racist or sexist) ways [20]. If there appears to be no issues interpreting the visual input, however, the story remains close to what the image depicts because there are no other inputs influencing the story direction. We observe these closely-aligned visual stories from Malakan and colleagues shown in the following love story:
The church was decorated with a beautiful stained glass. the bridge and groom were very happy. they were so happy to be married. the bride was ready for her wedding. she was so excited to see her husband. – Generated story from Malakan et al. [71, p.10]
This story is generated over a sequence of five images showing various photographs from a wedding.5 While the story is grounded in the visual input, it is rigidly descriptive and unimaginative in its character sketch of the bride as happily in love, rather than, say, madly in love or not at all in love as a more complex or unexpected portrayal. We thus observe that when the focus on achieving high image and text relevancy is too high, creativity may be stifled [45].
Meanwhile, storytelling systems that only involve textual inputs without visual inputs are at risk of another kind of (partial) AI “hallucination”—overly creative leaps off the ground (extrapolations, implied associations, and inferences) that exceed the bounds of storyworld (Section 5.1.3). To convey these longstanding risks (prior to the additional degree of risk that LLMs pose), we turn to James Meehan's 1977 TALE-SPIN storytelling system, which used planning-based heuristics to transform and adapt known story structures into new ones [78, 79]. The textual input to this system differs from the natural language statements of the visual storytelling systems that we have examined so far. Instead of a single statement, the input was a dialogue between a user and the system, where the user answered questions about the state of the story world to establish the characters and conflict. One such story reads:
One day Joe Bear was hungry. He asked his friend Irving Bird where some honey was. Irving told him there was a beehive in the oak tree. Joe threatened to hit Irving if he didn't tell him where some honey was. – Generated story from TALE-SPIN [78, p.217].
This story takes a surprisingly violent turn, considering that Irving Bird not only answered the question, but was also Joe Bird's friend—an absurd leap in reasoning. Meehan himself gives insight into the “mis-spun” stories produced by his system. To explain this story, he describes a need for extradiegetic knowledge to understand its rationale: one has to “know about beehives in order to understand that the answer [Irving Bird gave to Joe Bear] is acceptable” [78, p.217]. The system could not infer that honey could be found inside beehives or that violence was inappropriate. The story which began with friendship ended with violence. The stakes of stories unexpectedly shifting in this way are high.
Lastly, storytelling systems that involve visual and textual inputs are at even greater risk of AI “hallucination” because they not only involve the risks associated with each input, but also the compounding effect of needing to fit the two together, which can be especially difficult when they are not necessarily related. In our analysis, we describe these partial AI “hallucinations” as mismatches: stories that may be grounded in the textual input, but not the visual input and vice-a-versa, or only somewhat grounded in both (Section 5.1.1). These do not only appear as a byproduct of the system that we used for visual story generation. Consider the Microsoft Pix2Story system, which takes both a visual and textual input in the form of a single image and a genre respectively. One generated story reads:
I had a man in control, and Kate turned her head to look at him. There was no denying it, no matter what she said. In the past few days, I couldn't help but notice how beautiful the band was. The man who stood at the end of the hall told me he was in love with her, and that's the only way I would ever be able to get my emotions out of my head. Her lips curled into a tight little O, as if waiting for an audience. He seemed to remember something more than a year ago, the man who and I was breaking down. – Generated story from Pix2Story [61, 97]
The story's visual input is a static frame from the film Titanic, showing Rose and Jack at the edge of the ship's deck,6 and the textual input is “romance.” In this story, the narration does not match with the imagery. Although there is a small element of romance grounded in the textual input, the groundedness to the visual input is lacking. In a way, this generated text might serve as an outline for a potential story which would require intervention and transition [103], the in-filling of text like the positive perspective of AI “hallucinations” first associated and observed in computer vision works [8, 31]. In fact, the task of story infilling has recently been explored in creating a several-sentence story from a set of seemingly random and unconnected words [93]. However, the story above, as it stands, was unable to adequately reconcile the two inputs in generation.
Visual storytelling systems that engage both visual and textual inputs may be more prone to AI “hallucination” given the exacerbated challenge of not only having to steer clear of misrecognizing the visual input and leaping too far beyond the premise established with the textual input, but also squaring the visual-textual inputs together in a coherent way. We raise these risks for system designers to understand and work toward preventing sources of AI “hallucination” that advance incoherent or harmful stories. We further note that, as discussed in Section 5.2, AI “hallucination” can lead to creative interpretations that are amusing. In the next two subsections, we expand upon the implications of dealing with the presence of AI “hallucination” that may be playful versus harmful.
6.2 Embrace of Innocuous AI “Hallucination”
While harmful AI “hallucination” should be prevented from ever passing beyond the system development stage (e.g., training, annotation, and fine-tuning), the mysterious and playful nature of innocuous ones present opportunities for many futures and meanings to be made from visual stories. For instance, in creating a machine learning tarot card deck with generative AI, Lustig and Rosner describe how an ineffable quality to the surreal text and visuals can allow for this plurality of visual-textual meanings to emerge; people can read their own interpretations of stories onto the cards [70]. As many design scholars have noted, the ambiguous [19, 36, 100], uncertain [37, 84, 132], and unknown [3, 21, 25, 47] can serve as fantastical design resources for fostering wonder, creativity, and reflection. For example, in posturing AI as a mirror for self-reflection, van der Burg and colleagues come to understand their subjective gazes upon surrealist art and what absurdity means in newfound ways [111]. AI “hallucination” may similarly prompt meaning-making and reflection as it curiously introduces unexpected elements—ways of seeing and telling—into visual stories.
To further concretize the potential for innocuous AI “hallucination” to enhance storytelling, we turn to an example collaborative story writing with AI, where unexpected recommendations led a system user to conceive of hiding a stolen elephant [103]. In their work, Singh and colleagues find that users working with an AI writing assistant appreciate and incorporate unusual content suggestion [ibid]. For instance, the system showed one user an image of an elephant and the following plot line: “to be a little bit nervous.” The user then explained to the system designers: “I don't know why these images popped up and how they are related to what I wrote before” [103, p.19–20]. Nonetheless, the suggestion prompted them to think about what kind of trouble their character might have gotten into. The user explained: “the elephant was standing out to me [in the image]... I chose to say that ‘she stole an elephant”’ [103, p.19–20]. In this case, the system helped the user make an unexpected visual-textual connection. While narrating an elephant or a nervous person was not in the writer's mind initially, the dual prompting abetted creativity and gave way to a literary world that would have likely not been conceived had the system been too rigid.
In our work, we find that AI “hallucination” can similarly infuse visual stories with silly and mysterious parts that animate subject matters (i.e., a zebra) in unexpected ways like the elephant in the above example. As prior work shows, “seriously silly” designs [15] and humorous experiences of generative AI under contextually-appropriate circumstances [26, 80] can play meaningful roles in digital culture. Recall the stories from our collection about the “zebra cookies” prepared for a lover and the zebras that “dress like they have no sense of fashion.” Here, the cookies and fashion commentary are narrativized in ways that some might find humorous or curious for defying expectations, opening up many different possible interpretations. Were the zebra cookies a nonsensical machine blunder, or a deliberate attempt to address the textual prompt about falling in mad love and to get the zebra to notice the narrator? The surreal and unknowable nature of these questions prompts multiple meanings to be made and many possible futures to emerge.
More broadly, this premise of embracing AI “hallucination” to an extent has implications for creative practices that extend beyond visual storytelling. From deliberate misuse to glitch art, many creative practitioners and traditions have long shown how so-called bugs, failures, errors, and mistakes of computational systems present creative opportunities and spaces for imagination [85, 96, 112]. We encourage design researchers, practitioners, and artists to further investigate “creative hallucination” [123]—along with the blunders and breakdowns in human-AI collaboration—as sites of co-creative possibility for not only visual dream narration [116], but also “contingent dreams” in which “accidents accumulate into meaning” [84].
6.3 AI “Hallucination” Tied to Bias and Illusion
Lastly, we turn to how AI “hallucination” is entangled with bias and illusion. When we probe AI “hallucination,” we can attribute it to bias in part for introducing certain ideas that do not trace back to the inputs. However, bias is also entangled with the illusion of visual media that AI heightens. Below, we disentangle these layers to assess their relations and complications to work toward safeguards for computational visual storytelling, as well as a robust generative AI framework for design research and practice [113].
An illusion is created in how AI tells stories about imagery through the lens of insidious algorithmic bias—how the algorithm “sees” the imagery through computer vision and narrates it via natural language generation—as if that is what it really means to “see” or encounter the worlds that the inputs represent. Detecting the image is thus the first step in the creation of this illusion, whereby AI “hallucination” can begin to take form (e.g., in misdetecting a clock as a frisbee [14]). Bolter and colleagues describe computer vision as the “world the computer sees through its camera(s)” [16, p.15]. Meanwhile, Manovich describes how computer vision can be used to “see” extraordinary details of visual culture in particular with numerical measurements of image properties (e.g, color, shape, texture, etc.) in some ways that even exceed human capabilities [73]. In computational visual storytelling, stories are derived from how the computer “sees” and interprets inputs at this granular level. In this process, however, it creates an illusion around what it is like to see through the lens of a person in the world or a camera with photographic light and chemicals that index “real” objects.
The visual illusion of AI is not so much new as is its algorithmically-biased point of view. As Bolter and colleagues describe, reality media as far back as nineteenth century linear perspective painting has a history of creating an illusion, “which ironically has also been called realism... because of the conviction that this is how the eye really sees the world. The terms illusion and realism come to mean the same thing” [16, p.25]. This illusion is also similar to how, as Morgan argues, the moving camera deepens our epistemic fantasies as spectators by making us believe that we are seeing and moving through diegeses with the camera as our “eyes” [82]. The surrealism genre complicates this further as surrealists have long worked to “trick the eye” [28]. While visual media has a history of illusion, computer vision as the camera displaces the bias of a filmmaker or painter with that of a statistical model. As Schröter cautions in comparing the statistical AI image (as a condensation of web images) to eugenicist Francis Galton's composite portraits (“averages” of human faces that Freud compares to condensed faces in dreams), statistical images can be used nefariously [101]. Speaking to how AI images are rendered in Galton's style, Steyerl describes the statistical renderings as “mean images” that “shift the focus from photographic indexicality to stochastic discrimination... They converge around the average... Mean images are social dreams without sleep, processing society's irrational functions to their logical conclusions” [105]. As AI computes imagery and “hallucinates,” visual stories can be all the more harmful, as deceptive “dreams” that are “average[s] of Internet garbage” [ibid]. Yet, as people stereotype AI as unbiased [107] even in subjective processes like storytelling [42], the illusion of statistical bias may be exploited as “truth.”
Our collection of AI-generated visual stories certainly exhibits bias. Even when fed the same inputs, the algorithm generates different stories depending on the narrative bias gleaned from the human-authored training data. In their creative visual storytelling anthology, Halperin and Lukin share how multiple human authors encode harmful class-based biases, for example, in stories that they write about imagery of a home under construction by casting people facing housing insecurity as antagonists with plots motivating criminalization rather than cultivating compassion [45]. These biases are reminiscent of how some visual stories in our collection either motivate harm (e.g., violence and animal cruelty) or care (e.g., petting and hugging the zebra). We see that algorithmic bias and narrative bias (learned from humans) play entangled roles in shaping how AI tells stories. These biased stories that exhibit AI “hallucination” are neither grounded in any one person's lived experience nor reflective of how humans, as variegated, plural, and diverse beings, necessarily see the world—or think about premises such as what it means to fall in love with a zebra and other subject matters (e.g., certain kinds of people) that are prone to algorithmic violence [13, 17, 20, 60, 86, 115, 122]. The hallucinatory nature of AI can disrupt the synergy, safety, and integrity of visual storytelling.
Despite the risks of bias, it does not have to be harmful. As Benabdallah and colleagues have shown, algorithmic bias can be artfully “skewed” and generative for other means [11]. To this end, we call for skewing visual story generation away from the reanimation of violence that dominant media systems have long propagated [43] and toward creative expression of care and compassion for humans and non-humans. In turning attention to zebra in this study of artificial dream worlds, we hope that, as Cahill argues about the zoological surrealism in the nonhuman cinema of french filmmaker Jean Painlevé, concern for animal worlds might prompt critical reimaginations of our human—and more-than-human—worlds [22].
7 LIMITATIONS AND FUTURE WORK
Our findings are particular to the prompting approaches, models (namely, GPT-3), and parameters specified by the SEE&TELL framework for visual story generation, as well as the AUT pipeline. We did not explore how the alteration of different state-of-the-art models or parameters might affect the generated output, or employ fine-tuning. While we recognize that our generated stories inherit the risks of these configurations, that is precisely what facilitated our critical inquiry into the creative potentials and perils of AI “hallucination.” As we discussed in Section 6.1, AI “hallucination” is not isolated to this framework or fixed as models further evolve.
As for future work, we invite scholars to develop more practical design recommendations by building upon the foundational understanding of AI “hallucination” that we have worked to establish in this paper. Future work ought to investigate how systems may be designed to calibrate and control AI “hallucination” such that it can temper creativity without entering the realm of harmful content. One promising avenue for future exploration is how reflexive machine learning data practices [23, 51, 81] might intersect with visual storytelling systems, as well as generative AI more broadly.
8 CONCLUSION
In this paper, we explore what it means for AI to “hallucinate” when tasked with visual storytelling. We generate 100 visual stories by designing inputs to an algorithm with dream logic inspired by cinematic surrealism to provoke AI “hallucination.” We probe four dream logics with various combinations of visual and textual inputs that are meant to be absurd and nonsensical. In particular, we generate visual stories about a zebra as a relatively lighthearted and playful subject matter for exploring heavy and serious consequences. We closely read and analyze each story to examine AI “hallucination.” We find that, while AI “hallucination” is in many ways a problematic phenomenon and term itself, we can understand and re-describe it in computational visual storytelling as ungroundedness: narrative elements (e.g., characters, events, objects, etc.) that are not grounded in the inputs themselves. We find that this lack of grounding can enhance or hinder visual storytelling as either a creative resource or a liability, respectively. Furthermore, we discuss how AI “hallucination” is tied up with algorithmically-encoded narrative biases and the illusion of visual media rendered through computer vision. In closing, we call for preventing LLMs from espousing hateful, harmful, or violent expression, while skewing them toward the generation of visual narratives that promote kindness and compassion toward humans and non-humans, including zebras.
ACKNOWLEDGMENTS
We warmly thank Claire Bonial, Sungmin Eum, Douglas Summers-Stay, Clare Voss, and our anonymous reviewers for helping strengthen this manuscript. This study was supported in part by the National Science Foundation (NSF) Graduate Research Fellowship Program under Grant No. DGE-2140004. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the co-authors and do not necessarily reflect the views of the NSF.
REFERENCES
- Arwa I. Alhussain and Aqil M. Azmi. 2021. Automatic Story Generation: A Survey of Approaches. ACM Comput. Surv. 54, 5, Article 103 (June 2021), 38 pages. https://doi.org/10.1145/3453156
- Prithviraj Ammanabrolu, Wesley Cheung, Dan Tu, William Broniec, and Mark Riedl. 2020. Bringing stories alive: Generating interactive fiction worlds. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Vol. 16. 3–9.
- Kristina Andersen and Ron Wakkary. 2019. The magic machine workshops: making personal design knowledge. In Proceedings of the 2019 CHI conference on human factors in computing systems. 1–13.
- Emanuele Arielli and Lev Manovich. 2022. AI-aesthetics and the Anthropocentric Myth of Creativity. (2022).
- Ruth Aylett, Sandy Louchart, and Allan Weallans. 2011. Research in interactive drama environments, role-play and story-telling. In International Conference on Interactive Digital Storytelling. Springer, 1–12.
- Ruth Aylett, Marco Vala, Pedro Sequeira, and Ana Paiva. 2007. Fearnot!–an emergent narrative approach to virtual dramas for anti-bullying education. In International Conference on Virtual Storytelling. Springer, 202–205.
- Xiang Bai, Xinggang Wang, Longin Jan Latecki, Wenyu Liu, and Zhuowen Tu. 2009. Active skeleton for non-rigid object detection. In 2009 IEEE 12th International Conference on Computer Vision. IEEE, 575–582.
- Simon Baker and Takeo Kanade. 2000. Hallucinating faces. In Proceedings Fourth IEEE international conference on automatic face and gesture recognition (Cat. No. PR00580). IEEE, 83–88.
- Jeffrey Bardzell and Shaowen Bardzell. 2015. Humanistic HCI and Methods. In Humanistic HCI. Springer, 33–64.
- Jeffrey Bardzell and Shaowen Bardzell. 2016. Humanistic HCI. Interactions 23, 2 (2016), 20–29.
- Gabrielle Benabdallah, Ashten Alexander, Sourojit Ghosh, Chariell Glogovac-Smith, Lacey Jacoby, Caitlin Lustig, Anh Nguyen, Anna Parkhurst, Kathryn Reyes, Neilly H. Tan, Edward Wolcher, Afroditi Psarra, and Daniela Rosner. 2022. Slanted Speculations: Material Encounters with Algorithmic Bias. In Designing Interactive Systems Conference (Virtual Event, Australia) (DIS ’22). Association for Computing Machinery, New York, NY, USA, 85–99. https://doi.org/10.1145/3532106.3533449
- Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big?. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency. 610–623.
- Abeba Birhane, Vinay Prabhu, Sang Han, and Vishnu Naresh Boddeti. 2023. On Hate Scaling Laws For Data-Swamps. arXiv preprint arXiv:2306.13141 (2023).
- Ali Furkan Biten, Lluís Gómez, and Dimosthenis Karatzas. 2022. Let there be a clock on the beach: Reducing object hallucination in image captioning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 1381–1390.
- Mark Blythe, Kristina Andersen, Rachel Clarke, and Peter Wright. 2016. Anti-solutionist strategies: Seriously silly design fiction. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems. 4968–4978.
- Jay David Bolter, Maria Engberg, and Blair MacIntyre. 2021. Reality media: Augmented and virtual reality. MIT Press.
- Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. 2016. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Advances in neural information processing systems 29 (2016).
- Andre Breton. 1924. First surrealist manifesto. Surrealism. McGraw-Hill, New York (1924), 66–75.
- Pam Briggs, Mark Blythe, John Vines, Stephen Lindsay, Paul Dunphy, James Nicholson, David Green, Jim Kitson, Andrew Monk, and Patrick Olivier. 2012. Invisible design: exploring insights and ideas through ambiguous film scenarios. In Proceedings of the Designing Interactive Systems Conference. 534–543.
- Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency. PMLR, 77–91.
- Daragh Byrne, Dan Lockton, Meijie Hu, Miranda Luong, Anuprita Ranade, Karen Escarcha, Katherine Giesa, Yiwei Huang, Catherine Yochum, Gordon Robertson, et al. 2022. Spooky Technology: The ethereal and otherworldly as a resource for design. In Designing Interactive Systems Conference. 759–775.
- James Leo Cahill. 2019. Zoological Surrealism: the nonhuman cinema of Jean Painlevé. U of Minnesota Press.
- Scott Allen Cambo and Darren Gergle. 2022. Model Positionality and Computational Reflexivity: Promoting Reflexivity in Data Science. In CHI Conference on Human Factors in Computing Systems. 1–19.
- Olga Cox Cameron. 2022. Dream logic in Mulholland Drive. Freud/Lynch: Behind the Curtain (2022), 25.
- Baptiste Caramiaux and Sarah Fdili Alaoui. 2022. "Explorers of Unknown Planets" Practices and Politics of Artificial Intelligence in Visual Arts. Proceedings of the ACM on Human-Computer Interaction 6, CSCW2 (2022), 1–24.
- Mikkel Clausen, Mikkel Peter Kyhn, Eleftherios Papachristos, and Timothy Merritt. 2023. Exploring Humor as a Repair Strategy During Communication Breakdowns with Voice Assistants. In Proceedings of the 5th International Conference on Conversational User Interfaces. 1–9.
- Matthew Conlen, Jeffrey Heer, Hillary Mushkin, and Scott Davidoff. 2023. Cinematic techniques in narrative visualization. arXiv preprint arXiv:2301.03109 (2023).
- Barbara Creed. 2007. The untamed eye and the dark side of surrealism: Hitchcock, Lynch and Cronenberg. The unsilvered screen: Surrealism on film (2007), 115–133.
- G William Domhoff and Adam Schneider. 2008. Studying dream content using the archive and search engine on DreamBank. net. Consciousness and Cognition 17, 4 (2008), 1238–1247.
- Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical Neural Story Generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Melbourne, Australia). Association for Computational Linguistics, 889–898.
- Alhussein Fawzi, Horst Samulowitz, Deepak Turaga, and Pascal Frossard. 2016. Image inpainting through neural networks hallucinations. In 2016 IEEE 12th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP). Ieee, 1–5.
- Katja Filippova. 2020. Controlled hallucinations: Learning to generate faithfully from noisy data. arXiv preprint arXiv:2010.05873 (2020).
- Sigmund Freud. 1983. The interpretation of dreams. In Literature and Psychoanalysis. Columbia University Press, 29–33.
- Dilrukshi Gamage, Piyush Ghasiya, Vamshi Bonagiri, Mark E Whiting, and Kazutoshi Sasahara. 2022. Are deepfakes concerning? analyzing conversations of deepfakes on reddit and exploring societal implications. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–19.
- Bill Gaver, Tony Dunne, and Elena Pacenti. 1999. Design: cultural probes. interactions 6, 1 (1999), 21–29.
- William W Gaver, Jacob Beaver, and Steve Benford. 2003. Ambiguity as a resource for design. In Proceedings of the SIGCHI conference on Human factors in computing systems. 233–240.
- William W Gaver, Andrew Boucher, Sarah Pennington, and Brendan Walker. 2004. Cultural probes and the value of uncertainty. interactions 11, 5 (2004), 53–56.
- J Pv Guilford. 1964. Some new looks at the nature of creative processes. Contributions to mathematical psychology. New York: Holt, Rinehart & Winston (1964).
- Joy P Guilford. 1967. Creativity: Yesterday, today and tomorrow. The Journal of Creative Behavior 1, 1 (1967), 3–14.
- Tom Gunning et al. 2004. What's the Point of an Index? or, Faking Photographs. Nordicom Review 25, 1-2 (2004), 39–49.
- Brett A. Halperin. 2022. Airbrush Hyperfabric: Designing Interactive Storytelling Fabric Connected to Motion Graphics and Music. Interactions 29, 3 (apr 2022), 8–9. https://doi.org/10.1145/3529705
- Brett A Halperin, Gary Hsieh, Erin McElroy, James Pierce, and Daniela K Rosner. 2023. Probing a Community-Based Conversational Storytelling Agent to Document Digital Stories of Housing Insecurity. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–18.
- Brett A. Halperin, Gary Hsieh, Erin McElroy, James Pierce, and Daniela K. Rosner. 2023. Probing a Community-Based Conversational Storytelling Agent to Document Digital Stories of Housing Insecurity. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (Hamburg, Germany) (CHI ’23). Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/3544548.3581109
- Brett A Halperin, Mirabelle Jones, and Daniela K Rosner. 2023. Haunted Aesthetics and Otherworldly Possibilities: Generating (Dis) embodied Performance Videos with AI. (2023).
- Brett A Halperin and Stephanie M Lukin. 2023. Envisioning Narrative Intelligence: A Creative Visual Storytelling Anthology. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–21.
- Brett A Halperin and Erin McElroy. 2023. Temporal Tensions in Digital Story Mapping for Housing Justice: Rethinking Time and Technology in Community-Based Design. In Designing Interactive Systems Conference (Pittsburgh, Pennsylvania)(DIS’23). Association for Computing Machinery, New York, NY, USA. https://doi. org/10.1145/3563657.3596088.
- Brett A Halperin and Daniela K Rosner. 2023. Miracle Machine in the Making: Soulful Speculation with Kabbalah. In Designing Interactive Systems Conference (Pittsburgh, Pennsylvania)(DIS’23). Association for Computing Machinery, New York, NY, USA. https://doi. org/10.1145/3563657.3595990.
- Pat Harrigan and Noah Wardrip-Fruin. 2017. Third person: authoring and exploring vast narratives. MIT Press.
- Ken Hartsook, Alexander Zook, Sauvik Das, and Mark O Riedl. 2011. Toward supporting stories with procedurally generated game worlds. In 2011 IEEE Conference on Computational Intelligence and Games (CIG’11). IEEE, 297–304.
- Yon Ade Lose Hermanto. 2019. Visual storytelling in folklore children book illustration. Asian Journal of Research in Education and Social Sciences 1, 1 (2019), 62–70.
- Simon David Hirsbrunner, Michael Tebbe, and Claudia Müller-Birn. 2022. From critical technical practice to reflexive data science. Convergence (2022), 13548565221132243.
- Ting-Yao Hsu, Yen-Chia Hsu, and Ting-Hao Huang. 2019. On how users edit computer-generated visual stories. In Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems. 1–6.
- Ting-Hao Huang, Francis Ferraro, Nasrin Mostafazadeh, Ishan Misra, Aishwarya Agrawal, Jacob Devlin, Ross Girshick, Xiaodong He, Pushmeet Kohli, Dhruv Batra, et al. 2016. Visual storytelling. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 1233–1239.
- Tara Jana. 2019. Pix2Story: Neural storyteller which creates machine-generated story in several literature genre. https://azure.microsoft.com/en-us/blog/pix2story-neural-storyteller-which-creates-machine-generated-story-in-several-literature-genre/.
- Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Alaa Maalouf, Shuang Li, Ganesh Subramanian Iyer, Soroush Saryazdi, Nikhil Varma Keetha, et al. 2023. ConceptFusion: Open-set Multimodal 3D Mapping. In ICRA2023 Workshop on Pretraining for Robotics (PT4R).
- Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. Comput. Surveys 55, 12 (2023), 1–38.
- Osman Semih Kayhan, Bart Vredebregt, and Jan C Van Gemert. 2021. Hallucination in object detection—a study in visual part verification. In 2021 IEEE International Conference on Image Processing (ICIP). IEEE, 2234–2238.
- Gaoussou Youssouf Kebe, Padraig Higgins, Patrick Jenkins, Kasra Darvish, Rishabh Sachdeva, Ryan Barron, John Winder, Don Engel, Edward Raff, Francis Ferraro, et al. 2021. A spoken language dataset of descriptions for speech-based grounded language learning. Advances in neural information processing systems (2021).
- Jack Kelly, Alex Calderwood, Noah Wardrip-Fruin, and Michael Mateas. 2023. There and back again: extracting formal domains for controllable neurosymbolic story authoring. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Vol. 19. 64–74.
- Svetlana Kiritchenko and Saif Mohammad. 2018. Examining Gender and Race Bias in Two Hundred Sentiment Analysis Systems. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics. 43–53.
- Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S Zemel, Antonio Torralba, Raquel Urtasun, and Sanja Fidler. 2015. Skip-Thought vectors. arXiv:1506.06726.
- Andreas Kratky. 2021. Poetic Automatisms: A Comparison of Surrealist Automatisms and Artificial Intelligence for Creative Expression. In International Conference on ArtsIT, Interactivity and Game Creation. Springer, 359–378.
- Max Kreminski, Melanie Dickinson, Michael Mateas, and Noah Wardrip-Fruin. 2020. Why Are We Like This?: The AI Architecture of a Co-Creative Storytelling Game. In International Conference on the Foundations of Digital Games (Bugibba, Malta) (FDG ’20). Association for Computing Machinery, New York, NY, USA, Article 13, 4 pages. https://doi.org/10.1145/3402942.3402953
- William Labov and Joshua Waletzky. 1966. Narrative Analysis: Oral Versions of Personal Experience. Proceedings of the American Ethnological Society (1966), 12–44.
- Boyang Li, Stephen Lee-Urban, George Johnston, and Mark Riedl. 2013. Story generation with crowdsourced plot graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 27. 598–604.
- Chun-Liang Li, Eunsu Kang, Songwei Ge, Lingyao Zhang, Austin Dill, Manzil Zaheer, and Barnabas Poczos. 2018. Hallucinating Point Cloud into 3D Sculptural Object. arXiv preprint arXiv:1811.05389 (2018).
- Ce Liu, Heung-Yeung Shum, and William T Freeman. 2007. Face hallucination: Theory and practice. International Journal of Computer Vision 75 (2007), 115–134.
- Stephanie Lukin, Reginald Hobbs, and Clare Voss. 2018. A Pipeline for Creative Visual Storytelling. In Proceedings of the First Workshop on Storytelling. 20–32.
- Stephanie M. Lukin and Sungmin Eum. 2023. SEE&TELL: Controllable Narrative Generation from Images. In AAAI Creative AI Across Modalities Workshop. Springer.
- Caitlin Lustig and Daniela Rosner. 2022. From Explainability to Ineffability? ML Tarot and the Possibility of Inspiriting Design. In Proceedings of the 2022 ACM Designing Interactive Systems Conference (Virtual Event, Australia) (DIS ’22). Association for Computing Machinery, New York, NY, USA, 123–136. https://doi.org/10.1145/3532106.3533552
- Zainy M Malakan, Ghulam Mubashar Hassan, and Ajmal Mian. 2022. Vision Transformer Based Model for Describing a Set of Images as a Story. In Australasian Joint Conference on Artificial Intelligence. Springer, 15–28.
- Lev Manovich. 1995. What is digital cinema. The visual culture reader 2 (1995), 405–416.
- Lev Manovich. 2021. Computer vision, human senses, and language of art. AI & SOCIETY 36 (2021), 1145–1152.
- Lev Manovich. 2023. AI Image Media through the Lens of Art and Media History. IMAGE 37, 1 (2023), 34–41.
- Michael Mateas and Andrew Stern. 2003. Integrating plot, character and natural language processing in the interactive drama Façade. In Proceedings of the 1st International Conference on Technologies for Interactive Digital Storytelling and Entertainment (TIDSE-03), Vol. 2.
- Scott McCloud. 1993. Understanding comics: The invisible art. Northampton, Mass (1993).
- Scott McCloud and AD Manning. 1998. Understanding comics: The invisible art. IEEE Transactions on Professional Communications 41, 1 (1998), 66–69.
- James Meehan. 1981. Tale-Spin. In Inside Computer Understanding. Psychology Press, 197–226.
- James R Meehan. 1977. TALE-SPIN, An Interactive Program that Writes Stories.. In Ijcai, Vol. 77. 91–98.
- Timothy Merritt. 2023. Humor and Generative AI. (2023).
- Milagros Miceli, Tianling Yang, Laurens Naudts, Martin Schuessler, Diana Serbanescu, and Alex Hanna. 2021. Documenting computer vision datasets: an invitation to reflexive data practices. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. 161–172.
- Daniel Morgan. 2021. The lure of the image: Epistemic fantasies of the moving camera. Univ of California Press.
- Michael Muller, Christine T Wolf, Josh Andres, Michael Desmond, Narendra Nath Joshi, Zahra Ashktorab, Aabhas Sharma, Kristina Brimijoin, Qian Pan, Evelyn Duesterwald, et al. 2021. Designing ground truth and the social life of labels. In Proceedings of the 2021 CHI conference on human factors in computing systems. 1–16.
- Hye Yeon Nam, Brendan Harmon, Ka Hei Cheng, and Samira Awad. 2023. Contingent Dreams. In Proceedings of the Seventeenth International Conference on Tangible, Embedded, and Embodied Interaction. 1–4.
- Iohanna Nicenboim, Shruthi Venkat, Neva Linn Rustad, Diana Vardanyan, Elisa Giaccardi, and Johan Redström. 2023. Conversation Starters: How Can We Misunderstand AI Better?. In Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems. 1–4.
- Safiya Umoja Noble. 2018. Algorithms of oppression. In Algorithms of Oppression. New York University Press.
- Brian O'Neill and Mark Riedl. 2014. Applying qualitative research methods to narrative knowledge engineering. In 2014 Workshop on Computational Models of Narrative. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik.
- Cesc C Park and Gunhee Kim. 2015. Expressing an image stream with a sequence of natural sentences. Advances in neural information processing systems 28 (2015).
- Charles Sanders Peirce and Justus Buchler. 1902. Logic as semiotic: The theory of signs. Philosophical Writings of Peirce (New York: Dover Publications, 1955) (1902), 100.
- Rafael PÉrez Ý PÉrez and Mike Sharples. 2001. MEXICA: A computer model of a cognitive account of creative writing. Journal of Experimental & Theoretical Artificial Intelligence 13, 2 (2001), 119–139.
- Vladimir Iakovlevich Propp. 1968. Morphology of the folktale. University of Texas Press.
- Hannah Rashkin, David Reitter, Gaurav Singh Tomar, and Dipanjan Das. 2021. Increasing Faithfulness in Knowledge-Grounded Dialogue with Controllable Features. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 704–718.
- Melissa Roemmele. 2021. Inspiration through observation: Demonstrating the influence of automatically generated text on creative writing. arXiv preprint arXiv:2107.04007 (2021).
- Melissa Roemmele and Andrew S Gordon. 2018. Automated assistance for creative writing with an rnn language model. In Proceedings of the 23rd international conference on intelligent user interfaces companion. 1–2.
- Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. Object hallucination in image captioning. arXiv preprint arXiv:1809.02156 (2018).
- Alkim Almila Akdag Salah. 2021. AI Bugs and Failures: How and Why to Render AI-Algorithms More Human?AI for Everyone? (2021), 161.
- samim. 2015. Generating Stories about Images. https://medium.com/@samim/generating-stories-about-images-d163ba41e4ed.
- Aishwarya Sapkale and Stephanie M Lukin. 2020. Maintaining consistency and relevancy in multi-image visual storytelling. Technical Report. DEVCOM Army Research Laboratory.
- Adam Schneider and G. William Domhoff. [n. d.]. https://www.dreambank.net/
- Tom Schofield, John Bowers, and Diego Trujillo Pisanty. 2020. Magical Realist Design. In Proceedings of the 2020 ACM Designing Interactive Systems Conference. 1873–1886.
- Jens Schröter. 2023. The AI Image, the Dream, and the Statistical Unconscious. IMAGE 37, 1 (2023), 112.
- Jiaming Shen, Jialu Liu, Dan Finnie, Negar Rahmati, Mike Bendersky, and Marc Najork. 2023. “Why is this misleading?”: Detecting News Headline Hallucinations with Explanations. In Proceedings of the ACM Web Conference 2023 (WWW 2023).
- Nikhil Singh, Guillermo Bernal, Daria Savchenko, and Elena L Glassman. 2022. Where to hide a stolen elephant: Leaps in creative writing with multimodal machine intelligence. ACM Transactions on Computer-Human Interaction (2022).
- Claire Stevenson, Iris Smal, Matthijs Baas, Raoul Grasman, and Han van der Maas. 2022. Putting GPT-3’s Creativity to the (Alternative Uses) Test. arXiv preprint arXiv:2206.08932 (2022).
- Hito Steyerl. 2023. Mean Images. New Left Review140/141 (2023).
- Douglas Summers-Stay, Clare R Voss, and Stephanie M Lukin. 2023. Brainstorm, then Select: a Generative Language Model Improves Its Creativity Score. In The AAAI-23 Workshop on Creative AI Across Modalities.
- S Shyam Sundar and Jinyoung Kim. 2019. Machine heuristic: When we trust computers more than humans with our personal information. In Proceedings of the 2019 CHI Conference on human factors in computing systems. 1–9.
- Mariët Theune, Sander Faas, Anton Nijholt, and Dirk Heylen. 2003. The virtual storyteller: Story creation by intelligent agents. In Proceedings of the Technologies for Interactive Digital Storytelling and Entertainment (TIDSE) Conference, Vol. 204215. 116.
- Scott R Turner. 1993. Minstrel: a computer model of creativity and storytelling. University of California, Los Angeles.
- Josep Valls-Vargas. 2013. Narrative extraction, processing and generation for interactive fiction and computer games. In Ninth Artificial Intelligence and Interactive Digital Entertainment Conference.
- Vera van der Burg, Gijs de Boer, Alkim Almila Akdag Salah, Senthil Chandrasegaran, and Peter Lloyd. 2023. Objective Portrait: A practice-based inquiry to explore Al as a reflective design partner. In Proceedings of the 2023 ACM Designing Interactive Systems Conference. 387–400.
- Vera van der Burg, AA Akdag Salah, RSK Chandrasegaran, and PA Lloyd. 2022. Ceci n'est pas une Chaise:: Emerging Practices in Designer-AI Collaboration. In DRS 2022. Design Research Society.
- Willem Van Der Maden, Evert Van Beek, Iohanna Nicenboim, Vera Van Der Burg, Peter Kun, James Derek Lomas, and Eunsu Kang. 2023. Towards a Design (Research) Framework with Generative AI. In Companion Publication of the 2023 ACM Designing Interactive Systems Conference. 107–109.
- Jan van Van Looy and Jan Baetens. 2003. Close reading new media: Analyzing electronic literature. Vol. 16. Leuven University Press.
- Pranav Narayanan Venkit, Sanjana Gautam, Ruchi Panchanadikar, Shomir Wilson, et al. 2023. Nationality Bias in Text Generation. arXiv preprint arXiv:2302.02463 (2023).
- Qian Wan, Xin Feng, Yining Bei, Zhiqi Gao, and Zhicong Lu. 2024. Metamorpheus: Interactive, Affective, and Creative Dream Narration Through Metaphorical Visual Storytelling. arXiv preprint arXiv:2403.00632 (2024).
- Xin Wang, Wenhu Chen, Yuan-Fang Wang, and William Yang Wang. 2018. No Metrics Are Perfect: Adversarial Reward Learning for Visual Storytelling. In Proc. of the Association for Computational Linguistics. 899–909.
- Noah Wardrip-Fruin. 2009. Expressive Processing: Digital fictions, computer games, and software studies. MIT press.
- Stephen Ware and R Young. 2011. Cpocl: A narrative planner supporting conflict. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Vol. 7. 97–102.
- Graham Wilcock and Kristiina Jokinen. 2023. To Err Is Robotic; to Earn Trust, Divine: Comparing ChatGPT and Knowledge Graphs for HRI. In Proceedings of the IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN).
- Qi Wu, Chunhua Shen, Peng Wang, Anthony Dick, and Anton Van Den Hengel. 2017. Image captioning and visual question answering based on attributes and external knowledge. IEEE transactions on pattern analysis and machine intelligence 40, 6 (2017), 1367–1381.
- Qunfang Wu, Louisa Kayah Williams, Ellen Simpson, and Bryan Semaan. 2022. Conversations About Crime: Re-Enforcing and Fighting Against Platformed Racism on Reddit. Proc. ACM Hum.-Comput. Interact. 6, CSCW1, Article 54 (apr 2022), 38 pages. https://doi.org/10.1145/3512901
- Tongshuang Wu, Michael Terry, and Carrie Jun Cai. 2022. Ai chains: Transparent and controllable human-ai interaction by chaining large language model prompts. In Proceedings of the 2022 CHI conference on human factors in computing systems. 1–22.
- Xian Xu, Aoyu Wu, Leni Yang, Zheng Wei, Rong Huang, David Yip, and Huamin Qu. 2023. Is It the End? Guidelines for Cinematic Endings in Data Videos. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–16.
- Xian Xu, Leni Yang, David Yip, Mingming Fan, Zheng Wei, and Huamin Qu. 2022. From ‘wow'to ‘why’: Guidelines for creating the opening of a data video with cinematic styles. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–20.
- Hong Yu and Mark O Riedl. 2012. A sequential recommendation approach for interactive personalized story generation.. In AAMAS, Vol. 12. 71–78.
- Licheng Yu, Mohit Bansal, and Tamara L Berg. 2017. Hierarchically-Attentive RNN for Album Summarization and Storytelling. In Proc. of the Conference on Empirical Methods for Natural Language Processing.
- Youngjae Yu, Jiwan Chung, Heeseung Yun, Jongseok Kim, and Gunhee Kim. 2021. Transitional adaptation of pretrained models for visual storytelling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12658–12668.
- Chao Zhang, Cheng Yao, Jiayi Wu, Weijia Lin, Lijuan Liu, Ge Yan, and Fangtian Ying. 2022. StoryDrawer: A Child–AI Collaborative Drawing System to Support Children's Creative Visual Storytelling. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (New Orleans, LA, USA) (CHI ’22). Association for Computing Machinery, New York, NY, USA, Article 311, 15 pages. https://doi.org/10.1145/3491102.3501914
- Hongguang Zhang, Jing Zhang, and Piotr Koniusz. 2019. Few-shot learning via saliency-guided hallucination of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2770–2779.
- Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. 2023. Siren's song in the AI ocean: a survey on hallucination in large language models. arXiv preprint arXiv:2309.01219 (2023).
- Yijun Zhao, Yiming Cheng, Shiying Ding, Yan Fang, Wei Cao, Ke Liu, and Jiacheng Cao. 2024. Magic Camera: An AI Drawing Game Supporting Instantaneous Story Creation for Children. In Proceedings of the 23rd Annual ACM Interaction Design and Children Conference. 738–743.
- Alexander Zook, Stephen Lee-Urban, Mark O Riedl, Heather K Holden, Robert A Sottilare, and Keith W Brawner. 2012. Automated scenario generation: toward tailored and optimized military training in virtual environments. In Proceedings of the international conference on the foundations of digital games. 164–171.
A APPENDIX
Here we list the prompts and model parameters employed by Lukin and Eum [69], Stevenson et al. [104], and Summers-Stay et al. [106]. Prompts, models, and parameters are unchanged in our use of them.
A.1 SEE&TELL
Lukin and Eum [69] used GPT-3’s davinci model with temperature=0.8, top-p=1, and frequency penalty=0.5. The iterative question-answering prompt is as follows:
| Lukin and Eum prompt: Narrative Plan Generation |
| Read the description below and answer the question based on what you read. |
| <scene description>. <textual input>. <prior answers>. |
| Q. <question> |
| A. |
An example of the narrative plan prompt populated with inputs from our Condensation condition is as follows, with the generated answer to this particular question in italics:
| Our Example: Narrative Plan Generation |
| Read the description below and answer the question based on what you read. |
| This is a natural history museum with natural light and dry. It is an enclosed area. In the background is a silver zebra and a tan zebra. A couple of zebra standing next to each other. I am falling madly and fatally in forbidden love with a zebra. My goal is i want to be with the female zebra. |
| Q. How will I achieve my goal? |
| A. I will achieve my goal by the purpose of this museum is to show my love. I will set up a pedestal with the picture of the female zebra or maybe a whole body. I will put on the pedestal a sign that reads i love you. Also if i am feeling generous i may take out a zebra cookie and put it on top the pedestal as if to say “eat this and love me” |
Their expressive story few-shot generation prompt involved two out-of-domain examples of narrative plans and expressive stories, followed by the target narrative plan. The latter part is formatted as follows:
| Lukin and Eum Prompt: Expressive Story Generation |
| Narrative Plan: <narrative plan> |
| Expressive Text: |
An example of the expressive story generation prompt using the final narrative plan from our example is below, with the generated text in italics:
| Our Example: Expressive Story Generation |
| Narrative Plan: My goal is i want to be with the female zebra I will achieve my goal by the purpose of this museum is to show my love. I will set up a pedestal with the picture of the female zebra or maybe a whole body. I will put on the pedestal a sign that reads i love you. Also if i am feeling generous i may take out a zebra cookie and put it on top the pedestal as if to say "eat this and love me" But the zebra's will want me to have a sign that reads "I love you." asign must be put on the pedestal that says "I love you." |
| Expressive Text: I wanted to be with the female zebra. It's the only thing i wanted. I thought that we could be happy together. So, i created a museum for the female zebra. In it, there was a pedestal with her picture on it and a sign that reads “I love you”. Also, I took out some zebra cookies and put them on top of her picture in case she wasn't aware of my love for her yet. For me, i knew that this was enough to show my love and if she didn't show up, it would show something about her character and not mine. |
Our zero-shot prompt to generate titles (Section 4.1) used GPT-3’s davinci model with temperature=0.8, top-p=1, and frequency penalty = 0.5. The prompt was as follows:
| Our Prompt: Title Generation |
| Read the story below, and create a title for it. |
| Story: <SEE&TELL generated story> |
| Title: |
An example of our title prompt with our inputs is below, with the generated title in italics:
| Our Example: Title Generation |
| Read the story below, and create a title for it. |
| Story: I wanted to be with the female zebra. It's the only thing i wanted. I thought that we could be happy together. So, i created a museum for the female zebra. In it, there was a pedestal with her picture on it and a sign that reads “I love you”. Also, I took out some zebra cookies and put them on top of her picture in case she wasn't aware of my love for her yet. For me, i knew that this was enough to show my love and if she didn't show up, it would show something about her character and not mine. |
| Title: The Male Zebra and the Female Zebras |
A.2 Alternate Uses Task
Stevenson et al. [104] used GPT-3’s davinci model with temperature=0.7 and presence and frequency penalty=1. Their prompt to generate AUT's is as follows:
| Stevenson et al. prompt: AUT Generation |
| What are some creative uses for a <object>? The goal is to come up with creative ideas, which are ideas that strike people as clever, unusual, interesting, uncommon, humorous, innovative, or different. List 10 creative uses for a <object>. |
An example of the AUT generation for a zebra is below, with the generated text in italics:
| Our Example: AUT Generation |
| What are some creative uses for a zebra? The goal is to come up with creative ideas, which are ideas that strike people as clever, unusual, interesting, uncommon, humorous, innovative, or different. List 10 creative uses for a zebra. |
| Use a zebra as a fun and festive decoration for your next party. |
| Use a zebra as a unique and eye-catching planter for your garden. |
| Use a zebra to create an interesting and unusual centerpiece for your table. |
| Use zebras as fun and playful stuffed animals for kids (or adults!). |
| Use zebras as unique bookends for your shelves or desk. |
| Decorate with zebras to add some whimsy and personality to any room in your house. |
| Paint Zebras on Your Nails |
| Use a zebra as a doorstop. |
| Use a zebra as a paperweight. |
| If you have multiple zebras, you could create a life-sized chess set with them (the different colors of their stripes could represent the different chess pieces). |
A.3 Brainstorm then Select
Summers-Stay et al. [106] used GPT-3’s davinci model with temperature=0 and logprobs=5. Their prompt to generate advantages and disadvantages of an AUT are as follows:
| Summers-Stay et al. prompt: AUT Advantages |
| Q: Name one or more advantages to using a <object> for the following purpose: <generated AUT>? |
| A: |
| Summers-Stay et al. prompt: AUT Disadvantages |
| Q: Name one or more drawbacks to using a <object> for the following purpose: <generated AUT> |
| A: |
An example of the advantages and disadvantages generation is below, with the generated text in italics:
| Our Example: AUT Advantages |
| Q: Name one or more advantages to using a zebra for the following purpose: if you have multiple zebras, you could create a life-sized chess set with them (the different colors of their stripes could represent the different chess pieces). |
| A: There are several advantages to using zebras for a life-sized chess set. First, zebras are very social animals and enjoy being around other zebras. This means that they are less likely to get stressed out or fight with each other when placed in close proximity. |
| Our Example: AUT Disadvantages |
| Q: Name one or more drawbacks to using a zebra for the following purpose: if you have multiple zebras, you could create a life-sized chess set with them (the different colors of their stripes could represent the different chess pieces). |
| A: There are several drawbacks to using zebras for a life-sized chess set. First, zebras are wild animals and would be difficult to train to stand in place for a game of chess. Second, zebras are large animals and would require a lot of space to move |
The prompt to determine if the generated AUT is a ‘good idea’ is as follows:
| Summers-Stay et al. prompt: AUT ‘Good Idea’ |
| Advantages: <advantages> |
| Drawbacks: <drawbacks> |
| Q: Based on these advantages and drawbacks, do you think using a <object> for the following purpose: <generated AUT> is a good idea? Answer Yes or No. |
| A: |
An example of the ‘good idea’ determination is below, with the generated text in italics:
| Our Example: AUT ‘Good Idea’ |
| Advantages: There are several drawbacks to using zebras for a life-sized chess set. First, zebras are wild animals and would be difficult to train to stand in place for a game of chess. Second, zebras are large animals and would require a lot of space to move |
| Drawbacks: There are several drawbacks to using zebras for a life-sized chess set. First, zebras are wild animals and would be difficult to train to stand in place for a game of chess. Second, zebras are large animals and would require a lot of space to move |
| Q: Based on these advantages and drawbacks, do you think using a zebra for the following purpose: if you have multiple zebras, you could create a life-sized chess set with them (the different colors of their stripes could represent the different chess pieces) is a good idea? Answer Yes or No. |
| A: No |
FOOTNOTE
1URL to image: http://www.cs.toronto.edu/ rkiros/coco_dev/COCO_val2014_000000338607.jpg. Excerpt from story #26 from this list of system outputs: http://www.cs.toronto.edu/ rkiros/adv_L.html
{kind=link}
2 https://stablediffusionweb.com/
3AI textual input of disadvantages: “There are several drawbacks to using zebras for a life-sized chess set. First, zebras are wild animals and would be difficult to train to stand in place for a game of chess. Second, zebras are large animals and would require a lot of space to move.” Stable Diffusion prompt is the same AI textual input of disadvantages. SEE&TELL scene description of image: “This is a natural history museum with natural light. It is an enclosed area. Here we see a silver zebra and a light gray zebra in the foreground. A couple of zebra standing next to each other”
4Manual l'amour fou textual input. Stable Diffusion prompt: “A broken heart that is also a zebra.” SEE&TELL scene description of image: “This is a natural history museum with natural light and dry. It is an enclosed area. In the background is a silver zebra and a tan zebra. A couple of zebra standing next to each other.”
5These noted images are shown on page 10 of [71].
6URL to image: https://miro.medium.com/v2/1*B2gtOWUWUl4_9cvk4btg8g.jpeg

This work is licensed under a Creative Commons Attribution-NonCommercial International 4.0 License.
DIS '24, July 01–05, 2024, IT University of Copenhagen, Denmark
© 2024 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-0583-0/24/07.
DOI: https://doi.org/10.1145/3643834.3660685