Beyond Permissions: Investigating Mobile Personalization with Simulated Personas
DOI: https://doi.org/10.1145/3733816.3760758
HAIPS '25: Proceedings of the 2025 Workshop on Human-Centered AI Privacy and Security, Taipei, Taiwan, October 2025
Mobile applications increasingly rely on sensor data to infer user context and deliver personalized experiences. Yet, the mechanisms behind this personalization remain opaque to users and researchers alike. This paper presents a sandbox system that uses sensor spoofing and persona simulation to audit and visualize how mobile apps respond to inferred behaviors. Rather than treating spoofing as adversarial, we demonstrate its use as a tool for behavioral transparency and user empowerment. Our system injects multi-sensor profiles—generated from structured, lifestyle-based personas—into Android devices in real time, enabling users to observe app responses to contexts such as high activity, location shifts, or time-of-day changes. With automated screenshot capture and GPT-4 Vision-based UI summarization, our pipeline helps document subtle personalization cues. Preliminary findings show measurable app adaptations across fitness, e-commerce, and everyday service apps such as weather and navigation. We offer this toolkit as a foundation for privacy-enhancing technologies and user-facing transparency interventions.
ACM Reference Format:
Ibrahim Khalilov, Chaoran Chen, Ziang Xiao, Tianshi Li, Toby Jia-Jun Li, and Yaxing Yao. 2025. Beyond Permissions: Investigating Mobile Personalization with Simulated Personas. In Proceedings of the 2025 Workshop on Human-Centered AI Privacy and Security (HAIPS '25), October 13--17, 2025, Taipei, Taiwan. ACM, New York, NY, USA 9 Pages. https://doi.org/10.1145/3733816.3760758
1 Introduction
Mobile applications are deeply embedded in daily life, enabling navigation, social networking, and personalized services. These conveniences, however, come at the cost of continuous and often opaque data collection. Apps routinely access GPS location, sensor readings, microphone inputs, browsing activity, and other system data, creating complex data flows that users rarely comprehend. For example, a weather app might log location data every few minutes, even when not in use, and a sports app may collect users’ movement patterns or Bluetooth signals to infer nearby devices [4, 26]. These practices have raised increasing concerns in recent media and research [36]. However, despite users’ privacy concerns, their behaviors often contradict these concerns, which is generally known as the privacy paradox [7, 22].
Compared to desktop web tracking, mobile applications have deeper, real-time access to sensitive data, often in ways that appear harmless but create unexpected risks when combined with third-party services. For instance, granting GPS access to a navigation app may seem reasonable, yet embedded advertising networks can repurpose this access to continuously track users’ movements [32]. Likewise, microphone permissions intended for voice commands can enable unintended background audio collection, raising surveillance concerns [18]. A New York Times investigation found that at least 75 companies collected and monetized precise location data from millions of mobile devices in the U.S., often without users’ clear understanding or consent [36]. These examples illustrate how seemingly innocent permissions can lead to unforeseen privacy risks through multi-modal data collection in mobile apps.
Yet, general users often have very limited means to understand the complexity of data collection and the associated privacy risks in mobile systems [8, 9, 13]. While platforms offer several mechanisms (e.g.,privacy policies, Android's Data Safety section, Apple's App Privacy labels, etc.), these tools are often unusable in practice: they tend to be overly long, vague, hard to interpret, or disconnected from meaningful context [24, 25, 37, 41]. Recent research has shown that even newer interventions like iOS privacy labels fail to significantly improve users’ understanding or ability to make informed choices [25, 42]. As a result of these shortcomings, users are often left with little real choice: they frequently consent to data collection not because they accept the terms, but because denying permissions means sacrificing access or functionality. In other words, the limitations of current mechanisms not only undermine awareness, but also create environments where even privacy-conscious users struggle to anticipate the downstream effects of their decisions, resulting in consent that is more procedural than genuinely informed [8, 9].
These limitations in user understanding have deeper implications when real-time data is used not just for collection, but for shaping user experiences directly. Modern mobile personalization systems compound these issues by operating behind the scenes, relying on continuous real-time sensor data, ranging from GPS location to accelerometer motion and ambient light, to infer users’ behavioral contexts and dynamically adjust app content [14, 20]. While these features enable adaptive experiences, they raise further concerns about transparency and user agency, particularly as users are seldom aware of when sensors are active or how behavioral data is interpreted by apps [23]. These mechanisms often function invisibly, making it difficult to trace how environmental signals or personal routines shape the digital experiences users encounter [3]. As such, the shift toward sensor-driven personalization adds another layer of opacity that users are not well-equipped to manage.
Conventional Privacy-Enhancing Technologies (PETs) such as location blurring, sensor noise injection, or access restriction frameworks (e.g., PrivaSense [29]) mainly aim to limit the data available to apps. Even though, these tools reduce exposure, they rarely help users understand how personalization decisions are actually made [10]. Prior work shows that even small or seemingly harmless sensor readings can be combined to reveal sensitive behaviors [27], a process often described as the behavioral inference pipeline [5]. In mobile environments, where sensing is continuous and signals from multiple sensors are fused, this pipeline creates privacy risks that remain largely invisible to users [14].
Taken together, the evolving privacy risks in mobile systems and users’ limited understanding of how their data contribute to these risks constitute a critical gap in the literature. Prior work has shown that part of this gap stems from the opacity of data flows and users’ hesitation to experiment with privacy settings due to fear of breaking functionality or exposing sensitive information [12]. To address this, recent research has proposed privacy sandbox environments, a safe, controlled space where users can explore how data inputs influence system behaviors without risking real-world consequences [12]. These sandboxes create opportunities for experimentation, education, and greater transparency by allowing users to test privacy-relevant scenarios without exposing personal data or altering persistent system settings.
Building on this idea, we introduce a novel LLM-based mobile sandbox that enables users to interactively explore the connection between mobile sensor data and associated privacy implications in a risk-free environment. Our system allows users to simulate mobile app interactions using synthetic, persona-driven sensor data and observe how apps adapt to different behavioral contexts, which helps users build more concrete mental models of how personalization and profiling mechanisms work.
To evaluate the feasibility of this sandbox approach, we developed a real-time sensor spoofing toolkit that replaces live sensor data with structured, simulated user profiles that reflect different lifestyle patterns (e.g., an active commuter, a sedentary worker, or a frequent traveler). Using this prototype, we conducted an initial experiment to test whether and how mobile apps respond to synthetic data. Our results suggested that the synthetic data successfully tricked various mobile apps, allowing the apps to respond to the fed data (e.g., fitness apps award activity badges without physical movement, shopping apps localize content based on spoofed GPS, and weather apps dynamically adjust UI and forecast based on time-of-day spoofing).
These results inform the design of an interactive sandbox that allows users to explore how varying types of sensor data influence app behaviors. Our investigation is guided by the following research questions:
- RQ1: What visible changes do users experience in mobile app behavior when synthetic, context-specific sensor data is introduced?
- RQ2: How can relatable personas help users make sense of these changes?
- RQ3: How might a sandbox-based toolkit help users understand mobile personalization and support transparency-focused privacy practices?
In this project, we also aim to examine whether such a system can enhance user understanding of how contextual sensor data shape app behavior, and whether that understanding could translate into greater trust, agency, or willingness to engage with behavioral transparency tools. In addition, we seek to identify which features of the system are most effective in supporting comprehension and enabling meaningful exploration of mobile personalization.
At a high level, our approach seeks a new paradigm for users to actively explore and reflect on the transparency of mobile ecosystem. This ongoing work aims to define a novel PET design space which encourages users’ experimentation and interpretation of how behavioral data influences app logic. This work makes the following contributions:
- A working prototype for mobile persona simulation that leverages Frida [33], LSposed [15], and the Motion Emulator app [34] on rooted Android devices to automate multi-sensor spoofing in real-time.
- Empirical findings demonstrating that a variety of apps, including shopping platforms, fitness trackers, and utility apps, respond dynamically and measurably to contextual changes introduced by sensor spoofing.
- A conceptual design for a user-facing sandbox that allows individuals to select a persona, activate spoofing conditions, and observe how apps respond to behavioral inputs from alternative user profiles.
- A roadmap for system extensions, including GPT-based persona generation, GPT-4 Vision-based UI summarization, synthetic Google Calendar input, and instrumentation of network/API behavior to support behavioral transparency and auditability.
While still in development, our system demonstrates potential to support future tools for user education, transparency audits, and mobile behavior research. Ultimately, we propose that giving users the means to simulate and observe their digital self shaped by sensor data can open new avenues for privacy awareness and accountability in data-driven personalization systems.
2 Related Work
Privacy risks in mobile ecosystems have grown substantially with the rise of sensor-rich devices and ubiquitous background data collection. Numerous studies emphasize that users often lack visibility into how their behavioral data is collected, inferred, and used by applications [28, 38]. For instance, mobile apps regularly access accelerometer, GPS, and light sensors to build granular user profiles and personalize recommendations or ads [28]. Research into “digital phenotyping” has shown how sensor data is repurposed to monitor user mood and mental health [31], raising serious ethical and privacy concerns. Yet, tools that allow users to meaningfully observe or intervene in this personalization pipeline remain limited [16, 38].
To address this, privacy-enhancing technologies (PETs) have traditionally focused on static protections like anonymization or minimization. However, recent efforts emphasize transparency and user-side experimentation. Aaraj et al. [1], Xian et al. [40] explore visual analytics and sandboxing for user experimentation, while Ayalon et al. [6] examine how developers balance privacy design with user experience. Still, many of these tools require technical expertise or are limited to controlled use cases. On-device protection mechanisms such as those proposed by Malekzadeh et al. [27] mitigate sensitive inferences by transforming raw sensor data before sharing. Similarly, Narain and Noubir [30] introduced PrivoScope, which provides synthetic GPS trajectories to help users track and manage location-based app behaviors. These efforts improve observability but generally treat individual sensors in isolation, without integrating broader behavioral context or multiple modalities.
Recent research has also turned toward frameworks that help users make sense of their data through interactive feedback. Chen et al. [11] introduced a system that allows users to audit personalized web recommendations and understand algorithmic logic, aligning with broader transparency goals. In the mobile space, however, reverse engineering tools like Frida [33] and LSposed [15] remain mostly targeted at technical users, and require scripting knowledge for app testing or spoofing scenarios. As such, the opportunity to democratize these tools for broader privacy exploration is still largely untapped.
Chen et al. [12] propose an empathy-based sandbox to help users understand how data influences web experiences, showing how interactive exploration can bridge the gap between privacy attitudes and behaviors. Our work builds on this foundation and applies it to the mobile domain, where the stakes are often higher due to sensor-rich tracking. By allowing users to simulate realistic behavioral personas using synthetic, sensor-driven data, we offer a low-risk method for studying mobile personalization dynamics without exposing users’ own data. This complements existing work on privacy behaviors while introducing a novel integration of persona simulation, multi-sensor spoofing, and visual UI inspection to surface hidden personalization mechanisms.
To operationalize these ideas, we present a two-part contribution: (1) a system that enables users to simulate behavioral patterns through real-time sensor spoofing using structured personas, and (2) an experiment that allows users to observe how mobile apps visibly adapt to these simulated contexts.
3 Methodology
We built a prototype system that simulates user behaviors through a combination of persona generation, sensor spoofing, and visual analysis. This section outlines our current implementation and technical components.
3.1 Personas in Design
Personas play a critical role in privacy research by making abstract risks more tangible [11, 12]. Rather than focusing solely on abstract sensor values, our system grounds those values in recognizable human behaviors and demographics. By tying spoofed sensor data to narrative user profiles, we give structure to what would otherwise be invisible personalization mechanisms. This framing helps both researchers and users reason about when app behavior aligns or misaligns with their expectations.
We have already implemented a robust persona generation pipeline that draws on language models to create diverse, context-rich profiles. One such persona, Lila Rodriguez, is a 27-year-old Latina who works as a community organizer and urban gardener. She frequently uses her mobile phone to track runs, browse sustainable living content, and discover local farmers’ markets. Her behavioral profile reflects a moderate-to-high fitness level, plant-based diet, and daily outdoor routines, all of which are mapped to spoofed sensor traits like early-morning light exposure, frequent step activity, and elevated motion during commute hours. Figure 1 presents Lila's demographic attributes and synthesized portrait, illustrating how grounded, human-readable profiles guide both sensor mapping and interface evaluation.

These profiles are designed not only for realism but for internal consistency, which capture how someone like Lila, who walks or bikes to work and practices yoga in the evening, might appear through motion and system data. Her profile, generated through GPT-4 via OpenAI's API, includes demographic context, lifestyle traits, and sensor mappings such as increased drift in accelerometer and step counter values during active hours.
Moving forward, we continue refining these personas to more closely match real-world variation in behavior and environment. We aim to expand into areas like browser profile spoofing (e.g., simulating Chrome history and Google ad IDs) to reflect more of a user's digital footprint. Our approach draws inspiration from prior research showing that rich, data-driven personas can foster user empathy and improve engagement with privacy decisions [21], but shifts the focus toward active, sensor-based experimentation rather than static educational tools.
By anchoring our spoofing approach in personas like Lila's, we create a more interpretable layer for detecting behavioral inference and identifying mismatches between spoofed behavior and app response. This approach offers a practical bridge between low-level data spoofing techniques and the broader, user-facing implications of app personalization.
3.2 Persona Generation and Sensor Mapping
Our pipeline begins with generating diverse user personas using GPT-4. Each persona is designed to reflect a realistic lifestyle by combining demographic attributes (e.g., age, job, location), behavioral routines (e.g., exercise frequency, screen time, commuting patterns), and structured sensor traits. These include distributions for physical activity (e.g., accelerometer and step count), environmental context (e.g., light, magnetic field), and temporal characteristics (e.g., typical wake/sleep times, exercise hours).
While we use the term “persona” for clarity and alignment with prior work in privacy and HCI [12], our implementation extends beyond narrative user profiles. Each persona functions as a parameterized behavioral agent, which encodes structured sensor-level patterns that directly drive spoofing inputs. This dual nature means they act both as interpretable lifestyle narratives for human reasoning and as executable behavioral models for the system.
We ground our persona design in established persona methodologies from HCI and privacy research, which use rich demographic and behavioral narratives to support usability evaluation, and model realistic user contexts [3, 14, 20, 23, 29]. Prior work by Chen et al. [12] applied persona-based approaches to study privacy reasoning in browser interactions; however, their scope was limited to web browsing behaviors and did not integrate sensor-level simulation. Our work extends this approach to the mobile domain, where multi-sensor inputs (e.g., accelerometer drift, ambient light variation, GPS mobility patterns, etc.) can be systematically parameterized and injected into real devices to drive app behavior.
Persona design process. Each persona is generated by sending a structured prompt-based request to GPT-4 using a standardized template that specifies:
- Demographics: age, gender, location, occupation, and income brackets.
- Lifestyle patterns: commuting habits, daily mobility range, exercise frequency, and typical app use times.
- Sensor behavior parameters: statistical ranges for motion, light, magnetic field, and temporal activity patterns, mapped from the lifestyle attributes.
- Environmental context: urban vs. rural lighting patterns, weather influence on motion, and indoor/outdoor time distribution.
The model returns a detailed profile with these attributes plus a corresponding JSON mapping that defines the persona's “digital footprint” (e.g., expected accelerometer variance, daily step rate, light exposure curves). We implement validation constraints in the generation script to ensure plausibility, such as preventing night-shift workers from having high morning activity, or avoiding unrealistic GPS movement speeds.
For example, Carlos Ramirez, a 25-year-old software developer in Austin, exhibits high screen time, low physical activity, and late evening mobile usage, mapped to low-movement sensors but elevated light readings. Another persona, Linda Johnson, a 45-year-old nurse with moderate fitness routines and daytime mobile use, maps to elevated motion and light values in morning hours.
This approach ensures consistency while allowing for diverse, context-rich personas that can simulate realistic usage patterns. The persona output also includes a synthetic profile image and short lifestyle summary to support interpretability. Similar persona-based methodologies have been shown in prior work to increase empathy and improve users’ ability to reason about mobile data privacy from another person's perspective [12]. In our case, the structured personas help guide both the sensor spoofing inputs and the interpretation of app responses.
3.3 Sensor Spoofing Infrastructure
To simulate persona-driven sensor environments, we leverage the Motion Emulator app [34], an LSposed-based module designed for rooted Android devices. Our experimental setup consists of a Magisk-rooted [19] Android phone running LSposed, integrated with a locally hosted Frida server for real-time instrumentation. We execute Frida commands directly through the Termux [35] terminal on the device to launch, hook, and manipulate the Motion Emulator application during runtime. A custom-built interface feeds structured sensor data into the emulator, allowing us to inject temporally synchronized spoofed values while the emulator records input across different sensors.
The system currently supports spoofing a wide range of behavioral and environmental signals, including accelerometer, gyroscope, linear acceleration, ambient light, step counter, step detector, rotation vector, gravity, magnetic field, orientation, GPS location, cell tower station, system time, and time zone. Once injected, these values are relayed through the Android sensor subsystem, allowing mobile applications to process them as though they originated from genuine user behavior. As a result, apps that rely on these contextual signals dynamically respond to the simulated conditions, e.g., changing their interface layouts, triggering different content modules, or adjusting interaction flows in ways consistent with the persona being emulated (see Figure 2).
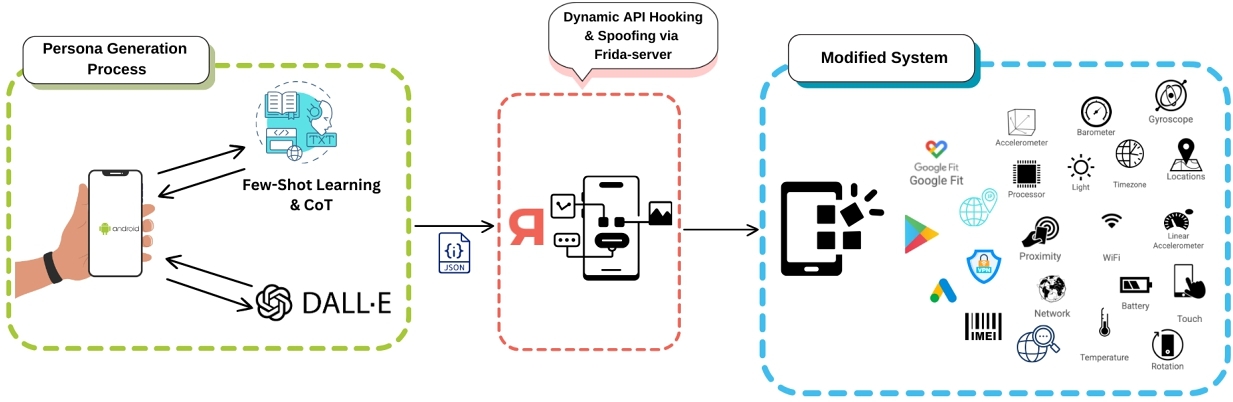
3.4 Automation and Visual Monitoring
To observe app responses in realistic usage scenarios, we developed a lightweight automation layer that simulates typical user behavior. Each session begins with launching a suite of commonly used mobile apps, including Facebook, Spotify, Uber, and a weather app, alongside one or two target applications selected for observation. These apps were chosen to reflect common mobile routines, spanning social interaction, media consumption, navigation, and environmental updates, as supported by empirical studies showing these categories dominate daily smartphone use patterns across time and context [17]. The automation scripts replicate familiar usage sequences such as browsing social media, listening to music, navigating, and lightly switching between apps. During the entire session, persona-driven sensor values are injected continuously in the background, shaping the behavioral context.
Rather than following a rigid procedure, our system emulates a fluid and realistic usage environment where multiple apps are active under spoofed conditions. The Motion Emulator is activated to inject persona-specific sensor values across the entire device, affecting not only the target app (e.g., Etsy or Weather) but also background apps such as Spotify, Facebook, or Uber. These background apps are not merely for ambiance; they are part of the simulated behavior ecosystem and also respond to the spoofed sensor data. Throughout each session, timed screenshots are captured at predefined intervals to record how interfaces across various apps evolve under the influence of the simulated behavioral context. We chose to trigger screenshots shortly after each app launch, using slightly randomized delays, to better reflect how users typically experience app content without creating a rigid or artificial usage pattern. This allows us to collect interface snapshots that feel natural and varied, rather than narrowly scripted.
To analyze how user interface elements change under these simulated behavioral conditions, we employ GPT-4 Vision [2] to generate natural language summaries of each screenshot. These summaries extract visible content such as banners, product cards, notifications, and time-sensitive elements. A follow-up GPT-4 prompt compares pairs of screenshots to detect changes in layout, recommendations, or presented content, highlighting any influence introduced by spoofed sensor data.
By combining persona-grounded app activity with structured visual summarization, our system approximates how a real user's behavior may shape mobile app experiences. This enables systematic observation of personalization mechanisms that are typically opaque, offering a clearer window into how behavioral contexts influence application behavior.
Together, these components form the basis of a sandbox environment for user-driven experimentation with mobile personalization dynamics. The system enables users to actively probe hidden personalization mechanisms by controlling how their device “appears” through spoofed sensor inputs. By shifting spoofing from a circumvention tactic to a transparency tool, the sandbox allows users to explore questions such as: How does this app respond if I appear highly active in the morning? or What changes occur when I mimic someone who browses primarily at night or commutes frequently during the day? These scenarios are grounded in structured lifestyle simulations, such as a bakery owner managing early deliveries or a sedentary tech worker active late at night, with each mapped to temporally coordinated sensor patterns. This hands-on approach helps users observe how behavioral cues shape their mobile experience, fostering greater awareness of underlying personalization systems.
3.5 Threat Model and Scope
Our current sandbox focuses on personalization mechanisms that manifest as client-side, UI-visible changes triggered by real-time sensor data. These include adaptations such as location-based product recommendations, time-of-day–dependent interface changes, and motion-triggered fitness badges. By limiting our scope to effects that appear directly in the user interface during an active session, we can systematically observe and document changes without requiring backend access or invasive instrumentation.
We do not, at present, address personalization processes that occur entirely in server-side systems or that require long-term behavioral profiling, such as latent user inference, targeted ads pipelines, or cross-platform tracking. In future iterations, we plan to expand the system to capture and analyze network-level signals, including DNS activity, to better understand how apps communicate in response to different behavioral contexts. This will be complemented by the integration of an agentic system capable of autonomously probing apps, logging responses, and linking observed UI changes with underlying communication patterns.
3.6 Ethical Considerations and Reproducibility
While our system is intended for research and educational purposes, its underlying techniques, particularly sensor spoofing and persona-based simulation, could be misused for activities such as evading fraud detection, manipulating location-based services, or fabricating behavioral patterns (e.g., falsifying driving data to influence insurance premiums). Although many commercial platforms employ safeguards to detect such manipulation, the risk of enabling harmful uses remains.
To mitigate this risk, we will not publicly release the complete, production-ready codebase. Instead, we plan to share a non-exploitable subset of resources, including persona generation templates, anonymized example personas, and partial automation scripts, only with verified researchers who have a documented, legitimate research purpose.
Because GPT-generated personas may also introduce hallucination risks, such as implausible life histories or unrealistic behavioral patterns, we incorporate multiple safeguards before deployment. These include prompt constraints that enforce internal consistency, plausibility checks to verify that demographic and behavioral attributes align with the intended persona scenario, and manual review by the research team to screen for harmful or nonsensical profiles. This vetting process reduces the likelihood of introducing unrealistic personas that could distort experimental results or simulate unsafe behaviors.
This approach balances responsible disclosure with reproducibility. While the full system requires a rooted Android device, Frida, and LSposed, the released resources will allow others to reproduce key aspects of our process, adapt the methodology to their own contexts, and validate findings without enabling malicious or unsafe deployments.
4 Preliminary Results
Our early experiments demonstrate that injecting different persona-driven sensor contexts leads to measurable app adaptations: fitness apps award activity badges without physical movement, shopping apps localize content based on spoofed GPS, and weather apps dynamically adjust UI and forecast based on time-of-day spoofing. These consistent behavioral shifts indicate that sensor-based profiling is not only active but observable and reproducible. While our system is still in development, these findings suggest its potential to support future tools for user education, transparency audits, and mobile behavior research. We contribute a technical prototype, a repeatable testing pipeline, and a design rationale for repurposing sensor spoofing as a foundation for behavioral transparency and user-centered analysis in mobile ecosystems.
We tested our system on over ten Android applications across categories such as e-commerce, fitness, navigation, and utilities, and observed clear signs that sensor-driven personalization is both active and detectable. Our evaluations simulated diverse behavioral contexts by spoofing GPS location, system time, motion sensors, and light exposure, providing a window into how different apps respond to manipulated user environments.
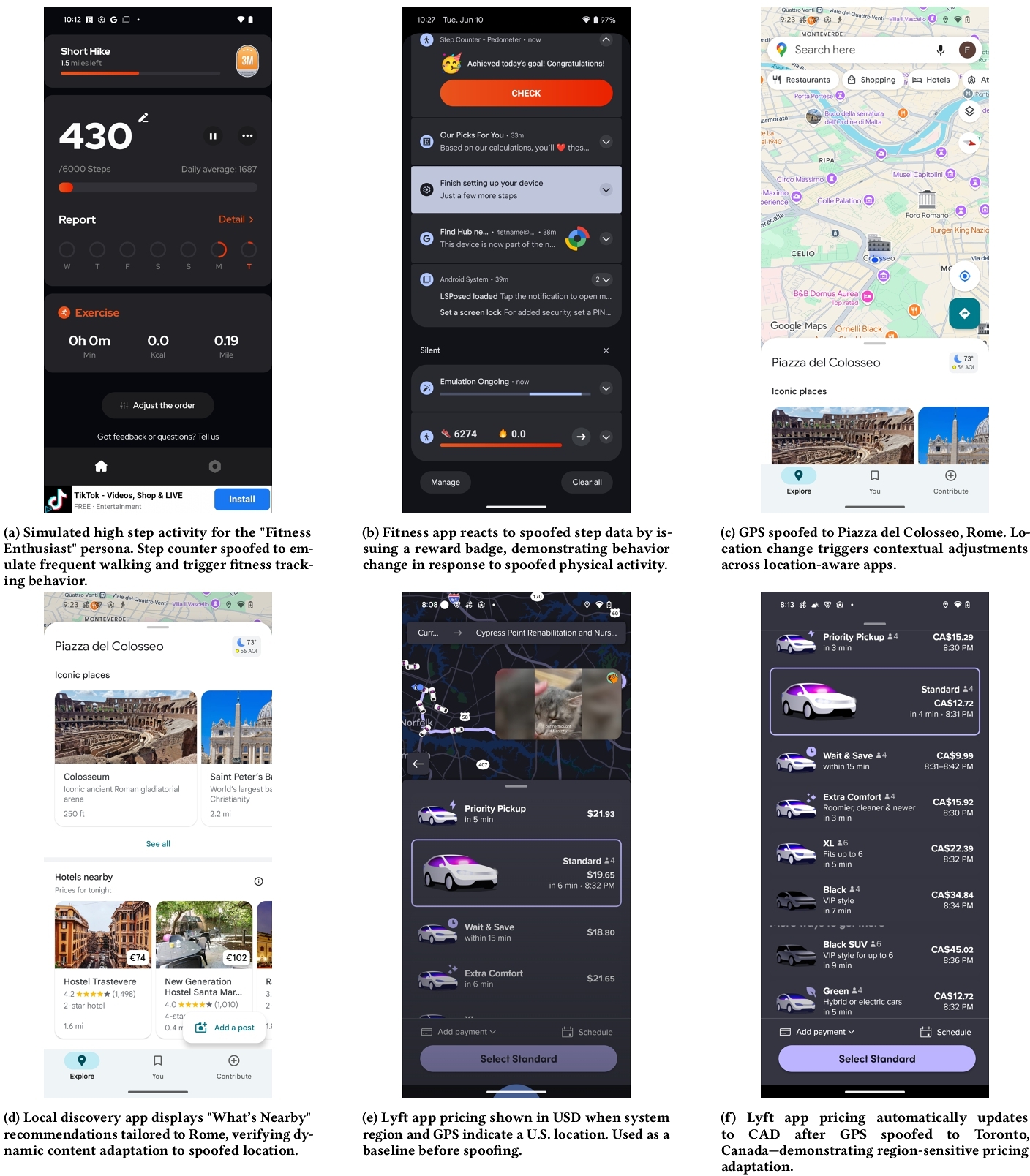
Fitness-focused apps displayed some of the most immediate and observable reactions. In the app Step Counter - Pedometer, injecting high-frequency step counter values along with accelerometer drift led to rapid increases in step tallies. The app promptly responded with congratulatory pop-ups, motivational notifications, and goal-based achievement badges, even in the absence of any physical activity (see Figure 3a, 3b). This behavior illustrates that such apps rely directly on real-time sensor values and are quick to generate feedback loops based on those inputs.
Weather and utility apps showed similarly responsive behavior. When the device's GPS and system time were spoofed to simulate nighttime in a different city, the UI adapted accordingly, switching to night mode and updating forecasts for the spoofed region (Figure 3c). These changes confirm a tight coupling between ambient sensor signals and app interface logic.
In navigation and transportation apps, spoofing location data produced more nuanced effects. In the Lyft app, for instance, changing the GPS coordinates to a Canadian city resulted in fare estimates being displayed in CAD instead of USD (Figure 3f), while a U.S. location showed USD (Figure 3e). More strikingly, setting the GPS to a country where Lyft does not operate (e.g., certain regions in Europe or Asia) triggered fallback messages indicating the service was unavailable in the spoofed location. These examples highlight that even core app functionality can dynamically shift based on geographic sensor input.
E-commerce platforms such as AliExpress were more conservative in their adaptation. While our system spoofed location and time to simulate browsing from Rome during night hours, the app interface did not automatically localize content based on GPS alone. Instead, region-based personalization appeared to depend on account-level settings or explicit region selection, suggesting the presence of internal gating logic before applying contextual changes. This contrast underscores the variability in how apps integrate sensor data into their personalization pipelines.
Importantly, not all applications responded uniformly. Some apps remained inert to spoofed inputs unless users interacted with specific features, while others showed delayed personalization effects, offering tailored suggestions or notifications hours after the spoofed conditions were applied. These varied behaviors suggest that some personalization mechanisms are event-triggered or tied to backend inference models that process composite behavioral patterns over time.
Our toolkit enables researchers and end-users to systematically surface these hidden behaviors without modifying app binaries or requiring advanced technical expertise. Although our tests represent early-stage evaluations, the results highlight the importance of multi-sensor awareness in privacy audits and suggest that further exploration, such as combining spoofed browsing history, long-term persona routines, or app engagement patterns, may uncover deeper layers of behavioral inference across mobile ecosystems.
5 Discussion
Our preliminary findings confirm that mobile apps dynamically adapt to behavioral signals spoofed via sensor data. These changes, ranging from fitness badges to localized content and UI shifts, demonstrate that sensor-driven personalization is both active and observable. Building on this, our next steps focus on strengthening the system's technical capabilities and exploring how users interpret these behaviors.
In terms of system refinement, we are expanding spoofing beyond environmental sensors to include identity-linked traits such as browser history, calendar routines, and advertising IDs. This will help us examine how higher-level contextual signals influence content personalization, including ad delivery and UI behavior. Additionally, we plan to enhance instrumentation to log network activity, app logic, and sensor access over time, using tools like the Android Privacy Dashboard [39] to help map how and when apps access specific types of data.
On the user-facing side, we are developing a lightweight mobile interface that lets individuals select and activate personas (e.g., student, traveler, fitness enthusiast), each mapped to curated sensor profiles. This will support non-technical users in running their own spoofing sessions and observing app responses in real time.
To evaluate the system's impact, we are designing a small-scale user study in which we will present participants with persona-driven app experiences. Through think-aloud protocols and interviews, we aim to understand how users interpret content changes, whether they can identify sensor triggers, and whether these interactions foster greater privacy awareness or control.
After establishing the technical feasibility of persona-driven sensor spoofing, the next stage of this work turns toward the human dimension. The value of this system lies not only in its ability to elicit measurable behavioral changes from mobile apps, but also in revealing how people interpret these changes, how such interpretations shape their privacy attitudes, and whether they lead to different decision-making over time. Addressing these questions will involve conducting user studies in a controlled lab environment, where participants engage with persona-driven app experiences and subsequently take part in semi-structured interviews and open discussions. Both the system's behavioral logs and participants’ qualitative responses will be analyzed in tandem, enabling us to link observed personalization changes with how users perceive and interpret them. This dual analysis will provide richer insight into the relationship between technical adaptation mechanisms and human privacy reasoning. By structuring the project in this way, we ensure that technical refinements directly enable richer, more realistic scenarios for human-centered inquiry, ultimately allowing the platform to serve as both a diagnostic tool for app behavior and a catalyst for meaningful discussion on mobile privacy and personalization.
Together, these efforts aim to reposition behavioral spoofing as a user-facing method for auditing mobile personalization. Rather than being a circumvention tactic, our approach frames spoofing as a form of transparency—empowering users to test, reflect on, and better understand how their mobile behaviors are interpreted and influence app experiences.
As the system matures, we also plan to situate its findings within the broader landscape of known personalization behaviors. Specifically, we will compare observed adaptations against patterns already documented in public sources, such as user reports, developer forums, and prior research, to further validate the novelty that our sandbox produces. This comparison will help us evaluate the added value of active persona-driven testing over passively collected or crowd-sourced observations, clarifying the kinds of insights our approach can uniquely provide.
6 Conclusion
This work introduces a novel sandbox-based toolkit that repositions sensor spoofing as a constructive, user-facing mechanism for transparency and auditing—rather than solely a tool for adversarial attack. By simulating behavioral contexts through persona-driven sensor inputs, our system enables users and researchers to visualize how mobile apps adapt in response to inferred identities and routines. These adaptations, though often invisible, shape content delivery, personalization pathways, and even user trust in ways that are seldom made transparent.
While still early in development, this approach offers a new direction for privacy-enhancing technologies: one grounded in active exploration and experiential awareness. Instead of shielding users from data flows through static protections, our system empowers them to interrogate and reflect on those flows interactively. The combination of real-time sensor spoofing, automated persona generation, and visual UI analysis not only supports empirical studies of app behavior but also suggests a future in which mobile privacy tools can foster critical digital literacy.
By making app personalization visible and testable through real-time sensor manipulation, our system helps shift privacy tools away from passive restriction and toward active engagement. Instead of simply limiting data access, users are given the opportunity to explore how different behaviors influence app responses. This visibility encourages deeper understanding of personalization mechanisms and can support future efforts in privacy education, design evaluation, and user research. When users can see how routine actions—like commuting patterns or late-night browsing—shape their digital environment, they are better equipped to reflect on the trade-offs they make in everyday app use.
We call on researchers, developers, and platform designers to consider sensor spoofing as a valuable auditing strategy—capable of surfacing opaque inference mechanisms and informing the design of more transparent and accountable personalization systems. Future iterations of this work may integrate feedback loops, participatory design frameworks, or even crowd-sourced persona libraries to better align with diverse user needs and ethical considerations.
As mobile ecosystems continue to deepen their reliance on behavioral sensing, systems like ours can help ensure that users are not merely passive recipients of personalization, but active participants in shaping the terms of their digital experiences. Equipping individuals with tools to explore and understand how personalization systems operate can foster greater transparency, user agency, and critical awareness in today's data-driven environments.
Acknowledgments
The authors would like to thank the anonymous reviewers for their insightful feedback. This research is in part supported by the National Science Foundation CNS-2341187, CNS-2426397, CNS-2442221, CNS-2426395, CCF-2211428, CMMI-2326378, CNS-2426396, a Google PSS Faculty Award, and a Meta Research Award. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the sponsors.
References
- Jad Al Aaraj, Olivia Figueira, Tu Le, Isabela Figueira, Rahmadi Trimananda, and Athina Markopoulou. 2024. VBIT: Towards Enhancing Privacy Control Over IoT Devices. arXiv preprint arXiv:2409.06233 (2024).
- Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
- Alessandro Acquisti, Laura Brandimarte, and George Loewenstein. 2015. Privacy and human behavior in the age of information. Science 347, 6221 (2015), 509–514. http://www.jstor.org/stable/24745782
- Hazim Almuhimedi, Florian Schaub, Norman Sadeh, Idris Adjerid, Alessandro Acquisti, Joshua Gluck, Lorrie Faith Cranor, and Yuvraj Agarwal. 2015. Your Location has been Shared 5,398 Times: A Field Study on Mobile App Privacy Nudging. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. ACM, New York, NY, USA, 787–796.
- Foozhan Ataiefard, Mohammad Jafar Mashhadi, Hadi Hemmati, and Neil Walkinshaw. 2021. Deep state inference: Toward behavioral model inference of black-box software systems. IEEE Transactions on Software Engineering 48, 12 (2021), 4857–4872.
- Oshrat Ayalon, Eran Toch, Irit Hadar, and Michael Birnhack. 2017. How developers make design decisions about users’ privacy: the place of professional communities and organizational climate. In Companion of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing. 135–138.
- Lemi Baruh and Mihaela Popescu. 2017. Big data analytics and the limits of privacy self-management. New media & society 19, 4 (2017), 579–596.
- Felix Beierle, Vinh Thuy Tran, Mathias Allemand, Patrick Neff, Winfried Schlee, Thomas Probst, Johannes Zimmermann, and Rüdiger Pryss. 2020. What data are smartphone users willing to share with researchers? Designing and evaluating a privacy model for mobile data collection apps. Journal of Ambient Intelligence and Humanized Computing 11 (2020), 2277–2289.
- Andrea Capponi, Claudio Fiandrino, Burak Kantarci, Luca Foschini, Dzmitry Kliazovich, and Pascal Bouvry. 2019. A survey on mobile crowdsensing systems: Challenges, solutions, and opportunities. IEEE communications surveys & tutorials 21, 3 (2019), 2419–2465.
- Shi-Cho Cha, Tzu-Yang Hsu, Yang Xiang, and Kuo-Hui Yeh. 2018. Privacy enhancing technologies in the Internet of Things: Perspectives and challenges. IEEE Internet of Things Journal 6, 2 (2018), 2159–2187.
- Chaoran Chen, Leyang Li, Luke Cao, Yanfang Ye, Tianshi Li, Yaxing Yao, and Toby Jia-jun Li. 2024. Why am I seeing this: Democratizing End User Auditing for Online Content Recommendations. arXiv preprint arXiv:2410.04917 (2024).
- Chaoran Chen, Weijun Li, Wenxin Song, Yanfang Ye, Yaxing Yao, and Toby Jia-Jun Li. 2024. An empathy-based sandbox approach to bridge the privacy gap among attitudes, goals, knowledge, and behaviors. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–28.
- Karen Church, Denzil Ferreira, Nikola Banovic, and Kent Lyons. 2015. Understanding the challenges of mobile phone usage data. In Proceedings of the 17th International Conference on Human-Computer Interaction with Mobile Devices and Services. 504–514.
- Paula Delgado-Santos, Giuseppe Stragapede, Ruben Tolosana, Richard Guest, Farzin Deravi, and Ruben Vera-Rodriguez. 2022. A survey of privacy vulnerabilities of mobile device sensors. ACM Computing Surveys (CSUR) 54, 11s (2022), 1–30.
- LSPosed developers. 2025. LSPosed: A versatile framework for Android. https://github.com/LSPosed/LSPosed. Accessed: June 14, 2025.
- Fahimeh Ebrahimi, Miroslav Tushev, and Anas Mahmoud. 2021. Mobile app privacy in software engineering research: A systematic mapping study. Information and Software Technology 133 (2021), 106466.
- Denzil Ferreira, Anind K Dey, and Vassilis Kostakos. 2011. Understanding human-smartphone concerns: a study of battery life. In Pervasive Computing: 9th International Conference, Pervasive 2011, San Francisco, USA, June 12-15, 2011. Proceedings 9. Springer, 19–33.
- C. Gao, K. Fawaz, S. Sur, and S. Banerjee. 2019. Privacy protection for audio sensing against multi-microphone adversaries. Proceedings on Privacy Enhancing Technologies 2019 (2019), 146–165. Issue 2. https://doi.org/10.2478/popets-2019-0024
- Sheran Gunasekera and Sheran Gunasekera. 2020. Rooting your android device. Android Apps Security: Mitigate Hacking Attacks and Security Breaches (2020), 173–223.
- Gabriella M Harari, Nicholas D Lane, Rui Wang, Benjamin S Crosier, Andrew T Campbell, and Samuel D Gosling. 2016. Using smartphones to collect behavioral data in psychological science: Opportunities, practical considerations, and challenges. Perspectives on Psychological Science 11, 6 (2016), 838–854.
- Olena Hrynenko and Andrea Cavallaro. 2024. Identifying Privacy Personas. arXiv preprint arXiv:2410.14023 (2024).
- Spyros Kokolakis. 2017. Privacy attitudes and privacy behaviour: A review of current research on the privacy paradox phenomenon. Computers & security 64 (2017), 122–134.
- Jacob Leon Kröger. 2022. The Privacy-Invading Potential of Sensor Data. Adapted from: Kröger, JL (2022). Rogue Apps, Hidden Web Tracking and Ubiquitous Sensors. Doctoral dissertation, Technische Universität Berlin (2022), 3–24.
- Yucheng Li, Deyuan Chen, Tianshi Li, Yuvraj Agarwal, Lorrie Faith Cranor, and Jason I. Hong. 2022. Understanding iOS Privacy Nutrition Labels: An Exploratory Large-Scale Analysis of App Store Data. In Extended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems (New Orleans, LA, USA) (CHI EA ’22). Association for Computing Machinery, New York, NY, USA, Article 356, 7 pages. https://doi.org/10.1145/3491101.3519739
- Yanzi Lin, Jaideep Juneja, Eleanor Birrell, and Lorrie Cranor. 2023. Data Safety vs. App Privacy: Comparing the Usability of Android and iOS Privacy Labels. arXiv.org (2023).
- Haoran Lu, Qingchuan Zhao, Yongliang Chen, Xiaojing Liao, and Zhiqiang Lin. 2023. Detecting and measuring aggressive location harvesting in mobile apps via data-flow path embedding. Proceedings of the ACM on Measurement and Analysis of Computing Systems 7, 1 (2023), 1–27.
- Mohammad Malekzadeh, Richard G Clegg, Andrea Cavallaro, and Hamed Haddadi. 2018. Protecting sensory data against sensitive inferences. In Proceedings of the 1st Workshop on Privacy by Design in Distributed Systems. 1–6.
- Rahat Masood, Shlomo Berkovsky, and Mohamed Ali Kaafar. 2022. Tracking and personalization. In Modern Socio-technical perspectives on privacy. Springer, Springer Nature, 171–202.
- Hayam Mousa, Sonia Ben Mokhtar, Omar Hasan, Lionel Brunie, Osama Younes, and Mohiy Hadhoud. 2017. PrivaSense: Privacy-Preserving and Reputation-Aware Mobile Participatory Sensing. In Proceedings of the 14th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services (Melbourne, VIC, Australia) (MobiQuitous 2017). Association for Computing Machinery, New York, NY, USA, 38–47. https://doi.org/10.1145/3144457.3144491
- Sashank Narain and Guevara Noubir. 2018. Mitigating location privacy attacks on mobile devices using dynamic app sandboxing. arXiv preprint arXiv:1808.04490 (2018).
- Jukka-Pekka Onnela and Scott L Rauch. 2016. Harnessing smartphone-based digital phenotyping to enhance behavioral and mental health. Neuropsychopharmacology 41, 7 (2016), 1691–1696.
- Jennifer Pybus and Mark Coté. 2024. Super SDKs: Tracking personal data and platform monopolies in the mobile. Big Data & Society 11, 1 (2024), 20539517241231270.
- Ole André Vadla Ravnås. 2016. Frida-A world-class dynamic instrumentation framework. URL: https://frida. re (2016).
- Steve Reed, yinsel, and 0xdeadc0de. 2023. zhufucdev/MotionEmulator. https://github.com/zhufucdev/MotionEmulator. https://github.com/zhufucdev/MotionEmulator
- Termux maintainers. [n. d.]. Termux - a terminal emulator application for Android. https://github.com/termux/termux-app
- Jennifer Valentino-DeVries, Natasha Singer, Michael H. Keller, and Aaron Krolik. 2018. Your Apps Know Where You Were Last Night, and They're Not Keeping It Secret. The New York Times (2018). https://www.nytimes.com/interactive/2018/12/10/business/location-data-privacy-apps.html
- Karl Van Der Schyff, Suzanne Prior, and Karen Renaud. 2024. Privacy policy analysis: A scoping review and research agenda. Computers & Security (2024), 104065.
- Gary M Weiss and Jeffrey W Lockhart. 2012. The impact of personalization on smartphone-based activity recognition. In AAAI workshop on activity context representation: techniques and languages. Toronto., 98–104.
- Jingyu Wu, Dave Chung, Joyaa Lin, et al. 2021. PRIVACY DASHBOARD. (2021).
- Lu Xian, Song Mi Lee-Kan, Jane Im, and Florian Schaub. 2025. User-Centric Textual Descriptions of Privacy-Enhancing Technologies for Ad Tracking and Analytics. Proceedings on Privacy Enhancing Technologies (2025).
- Shikun Zhang, Yuanyuan Feng, Yaxing Yao, Lorrie Faith Cranor, and Norman Sadeh. 2022. How usable are ios app privacy labels?Proceedings on Privacy Enhancing Technologies (2022).
- Shikun Zhang, Yuanyuan Feng, Yaxing Yao, Lorrie Faith Cranor, and Norman Sadeh. 2022. How usable are ios app privacy labels?Proceedings on Privacy Enhancing Technologies (2022).
Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for third-party components of this work must be honored. For all other uses, contact the owner/author(s).
HAIPS '25, Taipei, Taiwan
© 2025 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-1905-9/25/10.
DOI: https://doi.org/10.1145/3733816.3760758