Cross-Vendor GPU Programming: Extending CUDA Beyond NVIDIA
DOI: https://doi.org/10.1145/3723851.3723860
HCDS '25: 4th Workshop on Heterogeneous Composable and Disaggregated Systems, Rotterdam, Netherlands, March 2025
The dominance of NVIDIA's CUDA platform in GPU programming has revolutionized fields such as machine learning (ML), scientific simulations, and computational biology. However, its exclusivity to NVIDIA GPUs poses significant challenges, including vendor lock-in, higher costs, and reduced hardware flexibility. Cross-platform solutions like HIP and SYCL often require extensive code rewrites, and while they provide tools to transform CUDA code into their APIs to reduce developer effort, these tools are frequently incomplete and fail to ensure seamless compatibility. Furthermore, the absence of a formal CUDA specification worsens these issues, creating the “CUDA dialect problem”, where NVIDIA's nvcc compiler behavior serves as the de facto standard, leading to incompatibilities with alternative compilers.
We present SCALE, a platform that enables seamless execution of CUDA applications on AMD GPUs without requiring any code modifications. Leveraging a “dual” compiler approach—a clang-based compiler with language extensions and an nvcc mode enabled in SCALE's clang compiler for existing CUDA codebases—SCALE effectively resolves the CUDA dialect problem. SCALE re-implements CUDA's runtime and driver APIs while mapping NVIDIA's compute capabilities to AMD architectures, ensuring native-level performance. Our evaluation demonstrates SCALE ’s capability to support a wide range of real-world frameworks implemented entirely in CUDA. SCALE provides broad compatibility across four AMD GPU microarchitectures and thirteen popular frameworks by supporting the majority of the CUDA API, reflecting 60% coverage. Finally, SCALE delivers minimal performance overhead compared to ROCm, enabling a unified codebase for both NVIDIA and AMD GPUs and greatly simplifying cross-platform development.
ACM Reference Format:
Manos Pavlidakis, Chris Kitching, Nicholas Tomlinson, and Michael Søndergaard. 2025. Cross-Vendor GPU Programming: Extending CUDA Beyond NVIDIA. In 4th Workshop on Heterogeneous Composable and Disaggregated Systems (HCDS '25), March 30, 2025, Rotterdam, Netherlands. ACM, New York, NY, USA 7 Pages. https://doi.org/10.1145/3723851.3723860
1 Introduction
Graphics Processing Units (GPUs) have become indispensable for accelerating a vast array of computationally intensive applications, spanning domains such as machine learning (ML), deep learning (DL), scientific simulations, data analytics, computational biology, and computer vision. Central to this transformation is NVIDIA's CUDA platform, widely regarded as the standard for GPU programming due to its comprehensive libraries, exceptional performance, and strong support from an extensive developer community.
However, the dominance of CUDA comes with a critical drawback: its exclusivity to NVIDIA hardware. This restriction locks developers into a single vendor ecosystem, limiting their ability to leverage GPUs or specialized accelerators [4, 8, 13, 20, 35], from other manufacturers. Vendor lock-in reduces hardware flexibility, increases hardware costs, and leads to supply chain risks. These limitations highlight the urgent need for solutions that enable true cross-platform GPU programming.
Two primary solutions address CUDA's platform exclusivity. Cross-platform frameworks, like HIP [1] and SYCL [15], require rewriting applications using specific programming models. Tools like HIPify [10] and SYCLomatic [24] ease this process but fail to fully convert CUDA code, requiring manual fixes and often separate codebases for optimal performance. The lack of a formal CUDA specification, with the "standard" defined by NVIDIA's nvcc, further complicates cross-platform portability due to inconsistencies with alternative compilers like clang. The second solution involves ML compilers like TVM [7] and OpenXLA [30]. These compilers rely on graph optimizers and libraries like cuDNN, which enhance performance but limit heterogeneity if equivalent implementations are unavailable for other accelerators. Additionally, their focus on AI workloads restricts applicability to broader domains like drug discovery and weather modeling, leaving many GPU-based applications unsupported.
In this paper, we propose SCALE, a platform enabling seamless execution of CUDA applications on AMD GPUs through ahead-of-time (AOT) compilation. By eliminating the need for runtime translation or code modifications, SCALE frees developers from vendor lock-in, allowing hardware selection based on performance and cost rather than compatibility constraints. By treating GPU code like CPU code—write once, compile anywhere—SCALE significantly reduces the cost and complexity of maintaining separate codebases, making it an essential tool for heterogeneous accelerator environments. SCALE effectively addresses four main challenges:
Avoid multiple code-bases. Unlike cross-platform approaches, SCALE does not introduce a new language; instead, it extends CUDA as C++ extends C, providing seamless compatibility while enhancing functionality. SCALE allows programs written using the widely popular CUDA language to be directly compiled for AMD GPUs using SCALE's nvcc-compatible compiler. Our compiler transforms CUDA kernel code and PTX [28] inline assembly to the AMD machine code. Additionally, SCALE implements CUDA runtime and driver API calls, such as cudaMalloc and cudaLaunchKernel, using Heterogeneous System Architecture (HSA [38]) and HSA kernel driver. For CUDA-X libraries like cuBLAS and cuSOLVER, SCALE seamlessly maps them to their ROCm equivalents. To further enhance portability and performance across existing and future accelerators, we plan to develop dedicated, high-performance implementations of these libraries, leveraging the adaptability of the SCALE compiler.
Ensure stability and security. CUDA interception approaches [19, 32, 40] intercept CUDA calls and translate them to equivalents for other accelerators. While effective in some cases, these interception-based methods introduce significant challenges, including potential security vulnerabilities and system instability. To address these issues, SCALE completely re-implements CUDA's runtime and driver APIs tailored for AMD GPUs. This design eliminates the need for interception, ensuring native performance and robust execution of CUDA applications. SCALE intends to fully support all CUDA features, enabling optimized and fully functional performance on AMD hardware.
Overcome CUDA dialect issue. The lack of a formal CUDA specification creates a CUDA dialect problem, where the “standard” is defined by NVIDIA's nvcc, leading to incompatibilities with LLVM-based compilers. Many CUDA programs rely on nvcc-specific semantics, causing failures during compilation or unexpected behavior when ported to LLVM-CUDA dialects. This inconsistency complicates cross-platform development, often requiring significant code modifications to maintain compatibility. SCALE resolves this by offering an nvcc mode on its clang compiler that accepts nvcc-style arguments and is closer to nvcc’s dialect allowing seamless compilation of existing CUDA programs. SCALE's clang-based compiler supports LLVM-dialect CUDA with language extensions that do not conflict with nvcc.
Map CUDA features to other architectures. GPUs from different vendors exhibit significant architectural differences, particularly in warp [3, 25] size and compute capability, creating challenges for cross-platform execution. NVIDIA and AMD GPUs use different warp sizes, whereas many CUDA applications assume NVIDIA's 32-thread warp behavior, making operations like ballot and shuffle inefficient or incorrect on AMD hardware. To address this, SCALE introduces warp size emulation and utilizes the cudaLaneMask_t data structure to adapt warp-level operations seamlessly. Additionally, NVIDIA's compute capability system, crucial for feature-specific compilation, differs entirely from AMD's. SCALE bridges this gap by mapping NVIDIA compute capabilities (e.g., sm_86) to AMD architecture IDs (e.g., gfx1030) through a customizable configuration file, allowing existing CUDA build systems to function without modification.
We developed SCALE to provide comprehensive support for the CUDA programming model on AMD GPUs, enabling the execution of real-world applications that would otherwise be incompatible with AMD hardware. Preliminary evaluations demonstrate that SCALE achieves near-native performance, with minimal overhead compared to ROCm, ensuring compatibility and efficiency. SCALE currently supports the most frequently used CUDA API calls, covering 60% of the CUDA API, which has been sufficient to run over thirteen popular applications across four different AMD GPUs.
The main contributions of this paper are:
- We design and implement SCALE, a novel platform that enables the execution of CUDA applications on AMD GPUs without requiring code modifications or runtime translation. By directly compiling CUDA code to AMD-compatible binaries, SCALE eliminates the need for maintaining multiple codebases, ensuring compatibility, and performance while freeing developers from vendor lock-in.
- We resolve the CUDA dialect issue using an nvcc-equivalent mode in SCALE's clang-based compiler, ensuring seamless CUDA compilation while providing full support for inline PTX assembly.
- We introduce language extensions that enhance GPU programming by incorporating modern C++ features into the CUDA API and providing mechanisms to bridge architectural differences across GPU platforms.
- We evaluate the applicability and performance of our prototype using well-known frameworks that lack native support for execution on AMD GPUs.
2 Limitations of Existing Solutions
| Approach |
|
|
|
|
||||||||
| Cross-platform [1, 15, 18] | - | ✓ | ✓ | ✓ | ||||||||
| ML compilers [7, 23, 30] | ✓ | ✓ | - | ✓ | ||||||||
| Clang CUDA [21, 39] | ✓ | - | ✓ | ✓ | ||||||||
| Intercept CUDA [19, 32] | ✓ | ✓ | ✓ | - | ||||||||
| SCALE | ✓ | ✓ | ✓ | ✓ |
2.1 Cross-platform languages
Cross-platform languages, such as HIP [1], SYCL [15], oneAPI [18], and Kokkos [37] require developers to rewrite applications or frameworks entirely using their specific languages and programming models. Tools like HIPify [10] and SYCLomatic [24] aim to ease this burden by facilitating partial code conversion through source-to-source transformation. However, these tools face significant limitations. First, they cannot fully convert CUDA code, leaving developers to address gaps in compatibility manually. Second, achieving optimal performance across different GPUs and accelerators often entails maintaining separate code versions for each platform, undermining the goal of unified programming. Lastly, neither HIP nor SYCL supports inline PTX assembly, necessitating manual removal or conditional compilation using macros, further complicating code maintenance and portability.
As shown in Table 1, SCALE addresses these limitations by compiling CUDA directly for AMD GPUs without introducing a new programming model. It seamlessly converts inline PTX to LLVM Intermediate Representation (IR) and utilizes the appropriate clang backend to generate accelerator-specific machine code. Additionally, its clang-based compiler supports language extensions, enabling unified programming without requiring code rewrites or maintaining separate codebases.
2.2 Machine Learning (ML) compilers
ML compilers, such as TVM [7], OpenXLA [30], and MAX [23], introduce extension languages, such as TVM's tensor language, which require developers to modify existing machine learning frameworks. This task becomes particularly challenging, similar to unified platform solutions. Additionally, ML compilers rely on graph optimizers that translate high-level operator descriptions into machine code, often leveraging libraries like cuDNN. While these libraries enhance performance, their dependency can limit heterogeneity; the cross-platform capability is compromised if equivalent implementations are unavailable for a specific accelerator. Moreover, ML compilers primarily cater to AI and ML workloads, limiting their applicability in other critical domains where GPUs are essential. For instance, fields such as drug discovery, weather modeling, and computational fluid dynamics often lack the attention afforded to AI and ML despite their reliance on GPU acceleration. This narrow focus restricts the potential of ML compilers to address the full spectrum of GPU-based applications.
SCALE operates directly at the CUDA level, providing seamless support for all types of applications, including both ML and non-ML workloads, as Table 1 shows. Moreover, developing CUDA-X libraries from scratch—one of our key future goals—will enable SCALE to ensure seamless compatibility across all existing and future accelerators without requiring any code modifications.
2.3 CUDA clang compiler and CUDA Dialect Issue
clang [21, 39] provides robust support for CUDA compilation but depends on a different dialect than nvcc. More specifically, nvcc uses a split compilation model to separate host and device code early in the process. In contrast, clang employs a merged parsing approach where both host and device code must be semantically correct during each compilation step. While this approach enhances clang’s robustness for complex C++ edge cases, it introduces compatibility challenges for CUDA codebases written with nvcc in mind. Many real-world CUDA programs rely on nvcc-specific behaviors and semantics, leading to compilation failures or the need for significant modifications when using clang. This dialect discrepancy also affects frameworks like HIP, which inherit the LLVM-dialect CUDA model, making seamless compatibility with nvcc-based codebases difficult and further complicating cross-platform development. Remove your paper from the ACM proceedings. The paper will appear in our website. SCALE resolves the CUDA dialect issue by offering an nvcc frontend in its clang compiler. The nvcc frontend replicates NVIDIA's behavior for seamless compilation of existing CUDA programs, similar to LLVM's clang-cl for Microsoft Visual C++ compatibility.
2.4 CUDA Interception approaches
Interception approaches, as explored in prior works [19, 32, 40], aim to enable cross-platform compatibility by intercepting CUDA calls and translating them into equivalent implementations for other accelerators. While effective in specific scenarios, these methods face critical limitations. First, these methods translate intercepted CUDA calls to equivalent functions on other accelerators, but if the target accelerator lacks an identical implementation, functionality or performance is degraded, ultimately hindering support for diverse GPU architectures and workloads. Second, these approaches are inherently fragile, relying on proprietary NVIDIA features, such as the undocumented CUDA export table [12, 31, 33], a crucial yet hidden data structure that stores function pointers for CUDA libraries. Due to the lack of official documentation, developers resort to unreliable hacks to replicate its behavior, making solutions prone to failure if NVIDIA modifies or removes this structure. Lastly, they introduce significant security vulnerabilities by employing techniques like LD_PRELOAD to override native CUDA libraries with custom implementations, bypassing standard library loading mechanisms. This practice is highly problematic in security-sensitive environments, as it exposes systems to potential vulnerabilities and unauthorized access.
SCALE overcomes these limitations, as shown in Table 1, by directly re-implementing CUDA's runtime and driver APIs for AMD GPUs using HSA.
3 The SCALE Platform
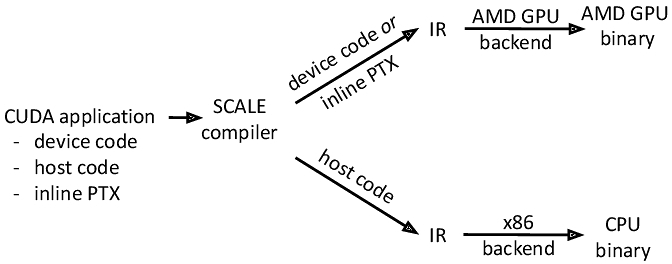
The design of SCALE is centered around addressing the limitations of existing cross-platform GPU programming solutions by providing seamless compatibility for CUDA applications on AMD GPUs. Unlike conventional approaches that require code rewrites or rely on fragile interception techniques, SCALE introduces a robust “dual”-compiler architecture and re-implementation of CUDA runtime and driver APIs. This design ensures support for diverse application domains, maintains high performance, and simplifies the developer experience while future-proofing compatibility with emerging accelerator architectures.
Figure 1 presents a high-level overview of SCALE. A CUDA application, including host and device code, as well as PTX [28] inline assembly, is processed by the SCALE compiler to generate an equivalent Intermediate Representation (IR). This IR is then translated into machine code using the backend of a targeted accelerator or CPU. While this paper focuses on AMD GPUs, the design of SCALE is extensible, allowing the IR to be easily transformed into binaries for other accelerators, provided an appropriate backend is available. Next, we provide an in-depth description of our compiler and the underlying mechanisms that enable its functionality.
3.1 Extend CUDA
SCALE's clang compiler enhances the GPU programming experience while providing robust support for heterogeneous accelerators through the following capabilities.
Inline PTX Assembly. SCALE supports CUDA's inline PTX assembly, enabling developers to incorporate low-level GPU instructions directly into their frameworks without using directly the CUDA API. This support ensures that performance-critical code sections can utilize hardware-specific optimizations while maintaining portability across platforms. SCALE handles several key features of PTX assembly by transforming them to AMD-specific equivalents. A critical aspect of SCALE is its handling of instructions like ballot and shuffle, which depend on GPU warp [3, 25] sizes—64 for some AMD GPUs and 32 for NVIDIA GPUs. SCALE introduces virtual warp size and cudaLaneMask data structure (described in more detail in § 3.4) to handle the warp size of the target hardware. It fully supports the shfl family of PTX instructions, enabling efficient data movement across threads within a warp, and handles PTX instructions that rely on specific integer lengths. Additionally, SCALE resolves inconsistencies in NVIDIA's nvcc handling of PTX asm inputs and outputs by establishing clear, predictable rules. Read-only inputs can be modified within the scope of the asm block, acting as local variables passed by value, while write-only outputs are treated as read-write, eliminating ambiguity between +r and =r constraints. Input or output types are determined by the expression type rather than the constraint letter, ensuring compliance with standard PTX rules for truncation, widening, or type-checking.
Compiler Warnings. By default, SCALE adopts clang’s stricter warning behavior, which is more rigorous than nvcc, meaning projects using -Werror may fail to compile unless the flag is adjusted or underlying code issues are resolved. Additionally, SCALE supports all standard clang++ flags alongside nvcc options, except where conflicts arise. The SCALE implementation of the CUDA runtime and driver APIs also applies [[nodiscard]] to error return codes, ensuring warnings for ignored CUDA API errors, which can be suppressed using -Wno-unused-result.
Language Extensions. SCALE enhances the CUDA programming model with optional language extensions that provide additional functionality and flexibility, empowering developers to write more expressive and efficient code while addressing the limitations of native CUDA. One notable extension is clang::loop_unroll, which provides explicit control over loop unrolling during compilation. This allows developers to optimize loops for performance-critical sections of code by specifying unrolling behavior directly, ensuring better utilization of GPU resources and improved runtime efficiency. Another feature is __builtin_provable(bool X), which serves as a powerful tool for static analysis and optimization. This build-in function enables code to opportunistically optimize for specific cases without incurring runtime branching overhead or requiring the propagation of such information throughout the program via templates.
3.2 Run CUDA calls to AMD
CUDA Runtime and Driver APIs. SCALE re-implements the majority of CUDA Runtime and Driver APIs using Heterogeneous System Architecture (HSA) [38]. This API includes a class for managing device memory, streams, events, and synchronization, allowing developers to retain the familiar CUDA programming model while achieving compatibility with AMD GPUs.
CUDA-X libraries APIs. SCALE provides partial support for CUDA-X libraries like cuBLAS and cuSOLVER by mapping their functionality to AMD's ROCm equivalents (e.g., rocBLAS). While the current implementation leverages existing ROCm libraries, we plan to develop its own high-performance versions of these libraries to improve portability and extend support to other accelerators. This approach ensures that frameworks using popular CUDA libraries can transition to AMD GPUs with minimal effort.
3.3 “Dual” Compiler
To overcome the challenges of the CUDA dialect problem, SCALE introduces an nvcc mode within its clang compiler, referred to as a second compiler for simplicity. The nvcc-compatible clang frontend replicates the behavior of NVIDIA's nvcc compiler. This frontend ensures that CUDA programs written with nvcc-specific semantics and behaviors can be compiled directly without modification. By emulating nvcc’s behavior, this compiler handles features like inline PTX assembly, NVIDIA-specific pragmas, and intricate details of nvcc’s compilation pipeline, such as its handling of preprocessor directives and device-specific functions.
3.4 Cross-Platform Compatibility
GPUs from different vendors have major architecture differences including warp [25] (or wavefront [3]) size and compute capability. Warp and wavefront sizes define how threads execute in parallel on different GPU architectures, creating a fundamental challenge for cross-platform execution. NVIDIA GPUs use warps of 32 threads, while some AMD GPUs rely on wavefronts of 64 threads. This difference affects thread scheduling, synchronization, and divergence handling, making it difficult to execute the same code efficiently on both architectures. Many CUDA applications are optimized for NVIDIA's 32-thread warps, assuming specific behaviors for operations like ballot and shuffle, which may not directly translate to AMD's 64-thread wavefronts. As a result, without proper adaptation, cross-platform execution can lead to incorrect results, inefficient thread utilization, or performance degradation. SCALE addresses this challenge using two techniques: (1) warp32 emulation, which logically splits a 64-lane wavefront into two 32-lane warps, preserving expected CUDA behavior for intra-warp operations such as shuffles. By leveraging (2) cudaLaneMask_t to extend warp-level operations to 64 lanes while allowing the compiler to issue warnings for patterns that assume a 32-lane warp.
NVIDIA's compute capability system allows developers to leverage hardware-specific features by enabling or disabling functionality through preprocessor directives. However, AMD GPUs use architecture identifiers like gfx1030, which fundamentally differ from NVIDIA's compute capability numbering scheme. Numeric comparisons on compute capability values, often used in CUDA projects, would malfunction if AMD identifiers were substituted directly, resulting in errors and incompatibilities. To bridge this gap, SCALE provides a separate CUDA installation directory for each AMD GPU target, mapping NVIDIA compute capability identifiers like sm_86 to the corresponding AMD architecture, such as gfx1030. This mapping ensures compatibility with existing build systems by allowing them to function as if targeting NVIDIA GPUs. The default mapping uses sm_86 to maximize compatibility with modern CUDA projects. By default, SCALE assigns AMD GPUs a compute capability number of at least sm_600000, ensuring backward compatibility while maintaining scalability for future architectures. However, developers are allowed to define different mappings.
4 Experimental Methodology
We now assess the performance and the applicability of SCALE by answering the following questions:
- Can SCALE compile and execute CUDA-only frameworks seamlessly on AMD GPUs?
- Does SCALE provide support for multiple AMD GPU micro-architectures?
- How extensive is SCALE's coverage of the CUDA API to support popular frameworks?
- What is the performance overhead of SCALE compared to ROCm?
5 Preliminary Evaluation
5.1 CUDA-Only Apps Execution on AMD GPUs
SCALE has been rigorously tested on a broad set of open-source CUDA projects, including AMGX, FLAMEGPU2, ALIEN, GOMC, GPU JPEG2K, XGBoost, and Fais that do not support AMD GPU natively. Table 2 presents the execution time, the availability of ROCm support for running on AMD GPUs, and the application names used from the framework. The parentheses in the App. Name column indicates the specific steps or image numbers used in the evaluation. ALIEN and GPUJPEG do not provide standalone applications, so we ran their unit tests to ensure compatibility with SCALE. It is important to note that, for all frameworks, we executed both their unit tests and multiple applications to validate their functionality. However, we report only one representative application per framework due to space constraints.
| Frameworks |
|
|
|
|||||
| AMGX [26] | 0.766 | No | dFFI (10) | |||||
| FLAMEGPU2 [34] | 1.032 | No | rtc_boids_bruteforce (100) | |||||
| ALIEN [17] | No App | No | unit tests | |||||
| GOMC [27] | 2.211 | No | NVT_GEMC (1000) | |||||
| GPU JPEG2K [9] | 1.18 | No | encoding(200) | |||||
| XGBoost [6] | 23 | No | House prices gbtree hist (1460) | |||||
| Faiss [11] | 1920 | No | search(100000) | |||||
| GPUJPEG [22] | No App | No | unit tests | |||||
| Rodinia [5] | See Fig. 2 | Yes | See Fig. 2 | |||||
| hashcat [16] | 7.4 | Yes | Hash-Mode 1400 | |||||
| LLaMA C++ [14] | 27 | Yes | llama-2-7b.Q4_0.gguf | |||||
| Thrust [29] | 4.7 | Yes | inclusive_scan.large_indices | |||||
| stdgpu [36] | 16.3 | Yes | deque_pop_back (10101000) |
5.2 Support Multiple AMD GPUs Architectures
SCALE supports state-of-the-art AMD GPU microarchitectures, including gfx900 (Vega 10, GCN 5.0), gfx1030 (Navi 21, RDNA 2.0), gfx1100 (Navi 31, RDNA 3.0), and the datacenter grade gfx942 (MI300X, CDNA3).
5.3 Coverage of the CUDA API
SCALE currently supports 47% of the CUDA 12.6 runtime API, 22% of the driver API, and 80% of the math API. While these percentages may seem modest, they can run thirteen real-world CUDA applications across multiple AMD GPU architectures. This success stems from the observation that, despite the extensive size of the CUDA API, only a small subset is commonly utilized in practice.
5.4 Performance Overhead Compared to ROCm
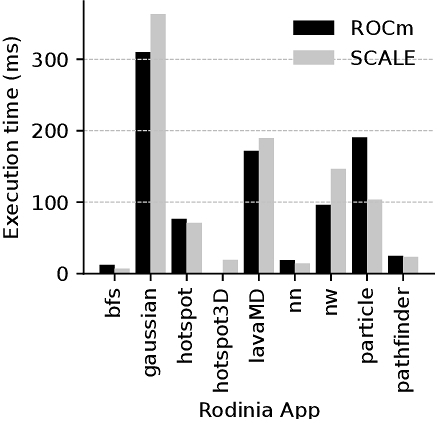
Figure 2 compares the execution time of CUDA applications compiled using our approach against their implementation using ROCm compiled with hipcc. This time includes all GPU operations: allocations, copies, kernel executions, and data frees. To better interpret our results, we analyze the execution time breakdown and find that SCALE generates highly optimized code, providing performance comparable to and, in some cases, surpassing native ROCm. These results highlight the effectiveness of our compiler in decreasing multiple code base issues without compromising performance. We also evaluated the execution of hashcat and LLaMA C++ which support AMD GPUs via ROCm. We observed that SCALE is not as performant as ROCm in these applications and are actively investigating the root cause. For Thrust, the ROCm implementation (rocThrust [2]) lacks the same benchmarks as the CUDA version, and due to time constraints, we were unable to adapt them for direct comparison. Lastly, for stdgpu, ROCm support remains experimental and fails to compile.
6 Conclusions and Future Work
SCALE offers a powerful new paradigm for GPU development by extending CUDA compatibility to AMD GPUs. Through its innovative platform, SCALE eliminates the need to port away from CUDA, providing GPU developers with unprecedented flexibility, cost savings, and hardware options. SCALE is poised to become a critical tool in the GPU market, empowering developers to choose the best hardware for their applications while remaining within the CUDA ecosystem.
As future work, we plan to further refine SCALE to minimize performance overhead and enhance efficiency across diverse AMD GPU microarchitectures and workloads. Expanding support for additional CUDA APIs and libraries, including advanced CUDA-X features, will be a key focus to improve compatibility with more complex applications. We also aim to extend SCALE to support other GPU vendors and accelerators, enabling broader adoption and eliminating vendor lock-in. Finally, we aim to extend the language beyond CUDA while incorporating advanced compiler optimizations to enhance performance and flexibility.
Acknowledgments
We would like to express our sincere gratitude to the team members at Spectral Compute who contributed to the development of SCALE. Special thanks go to Francois Souchay, Matthew Ireland, Ruben van Dongen, Andrei Stepanenko, Finlay Hudson, Vytautas Mickus, Patrick Ville, Allen Philip, Vanessa Oxley, Justine Khoo, Niki Järvinen, Aria Shrimpton, and Solomon Carden Brown for their invaluable efforts and expertise. The authors wish to acknowledge the use of Grammarly and Chatgpt to improve the language in the paper. The paper accurately represents the authors’ underlying work and novel intellectual contributions.
References
- AMD. 2022. Fundamentals of HIP Programming. Retrieved April 2023 from https://www.amd.com/system/files/documents/hip-coding-3.pdf
- AMD. 2025. rocThrust. Retrieved January 2025 from https://github.com/ROCm/rocThrust/tree/release/rocm-rel-6.2
- Yuhui Bao, Yifan Sun, Zlatan Feric, Michael Tian Shen, Micah Weston, José L. Abellán, Trinayan Baruah, John Kim, Ajay Joshi, and David Kaeli. 2023. NaviSim: A Highly Accurate GPU Simulator for AMD RDNA GPUs. In PACT ’22.
- Lukas Cavigelli, David Gschwend, Christoph Mayer, Samuel Willi, Beat Muheim, and Luca Benini. 2015. Origami: A Convolutional Network Accelerator. In GLSVLSI ’15.
- Shuai Che, Michael Boyer, Jiayuan Meng, David Tarjan, Jeremy W. Sheaffer, Sang-Ha Lee, and Kevin Skadron. 2009. Rodinia: A Benchmark Suite for Heterogeneous Computing. In IISWC ’09.
- Tianqi Chen and Carlos Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. In CoRR ’16.
- Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. 2018. TVM: An automated { End-to-End} optimizing compiler for deep learning. In OSDI ’18.
- Yunji Chen, Tianshi Chen, Zhiwei Xu, Ninghui Sun, and Olivier Temam. 2016. DianNao Family: Energy-Efficient Hardware Accelerators for Machine Learning. In MICRO ’16.
- Milosz Ciznicki. 2013. GPU JPEG2K. Retrieved January 2025 from https://github.com/ePirat/gpu_jpeg2k
- Advanced Micro Devices. 2020. HIPify. Retrieved May 2023 from https://docs.amd.com/bundle/HIPify-Reference-Guide-v5.1/page/HIPify.html
- Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. In ArXiv.
- Niklas Eiling, Jonas Baude, Stefan Lankes, and Antonello Monti. 2022. Cricket: A virtualization layer for distributed execution of CUDA applications with checkpoint/restart support. In Concurrency and Computation: Practice and Experience.
- Jouppi Norman et. al.2017. In-Datacenter Performance Analysis of a Tensor Processing Unit. In ISCA ’17.
- Georgi Gerganov. 2024. Inference of Meta's LLaMA model (and others) in pure C/C++. Retrieved November 2024 from https://github.com/ggerganov/llama.cpp
- Kronos Group. 2022. SYCL2020. Retrieved May 2023 from https://www.khronos.org/sycl/
- hashcat. 2022. hashcat. Retrieved January 2025 from https://github.com/hashcat/hashcat
- Christian Heinemann. 2025. ALIEN - Explore worlds of artificial life. Retrieved January 2025 from https://github.com/chrxh/alien
- Intel. 2020. oneAPI. Retrieved May 2023 from https://software.intel.com/content/www/us/en/develop/tools/oneapi.html#gs.4ac4fz
- Andrzej Janik. 2024. ZLUDA's third life. Retrieved October 2024 from https://vosen.github.io/ZLUDA/blog/zludas-third-life/
- Kyuho J Lee. 2021. Architecture of neural processing unit for deep neural networks. In Advances in Computers.
- LLVM. 2025. Compiling CUDA with clang. Retrieved January 2025 from https://llvm.org/docs/CompileCudaWithLLVM.html#id11
- B. Martin, J. Jan, M. Martin, P. Jiri, H. Martin, and H. Petr. 2019. JPEG Encoder and Decoder Library and Console Application for NVIDIA GPUs. Retrieved January 2025 from https://github.com/CESNET/GPUJPEG
- Modular. 2025. Welcome to MAX. Retrieved January 2025 from https://docs.modular.com/max/intro
- Robert Mueller-Albrecht. 2024. SYCLomatic: SYCL Adoption for Everyone - Moving from CUDA to SYCL Gets Progressively Easier: Advanced Migration Considerations. In IWOCL ’24.
- Veynu Narasiman, Michael Shebanow, Chang Joo Lee, Rustam Miftakhutdinov, Onur Mutlu, and Yale N. Patt. 2011. Improving GPU performance via large warps and two-level warp scheduling. In MICRO ’11.
- M. Naumov, M. Arsaev, P. Castonguay, J. Cohen, J. Demouth, J. Eaton, S. Layton, N. Markovskiy, I. Reguly, N. Sakharnykh, V. Sellappan, and R. Strzodka. 2015. AmgX: A Library for GPU Accelerated Algebraic Multigrid and Preconditioned Iterative Methods. In SIAM ’15.
- Younes Nejahi, Mohammad Soroush Barhaghi, Gregory Schwing, Loren Schwiebert, and Jeffrey Potoff. 2021. Update 2.70 to “GOMC: GPU Optimized Monte Carlo for the simulation of phase equilibria and physical properties of complex fluids”. In SoftwareX.
- NVIDIA. 2023. Parallel Thread Execution ISA. Retrieved May 2023 from https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
- NVIDIA. 2023. Thrust: The C++ Parallel Algorithms Library. Retrieved November 2024 from https://github.com/NVIDIA/thrust
- OpenXLA. 2025. OpenXLA. Retrieved January 2025 from https://openxla.org/xla
- Manos Pavlidakis, Anargyros Argyros, Stelios Mavridis, Giorgos Vasiliadis, and Angelos Bilas. 2024. Fine-Grained CUDA Call Interception for GPU Virtualization. In Middleware ’24.
- Manos Pavlidakis, Stelios Mavridis, Antony Chazapis, Giorgos Vasiliadis, and Angelos Bilas. 2022. Arax: A Runtime Framework for Decoupling Applications from Heterogeneous Accelerators. In SoCC ’22.
- Manos Pavlidakis, Giorgos Vasiliadis, Anargyros Argyros, Stelios Mavridis, Antony Chazapis, and Angelos Bilas. 2024. Guardian: Safe GPU Sharing in Multi-Tenant Environments. In MIDDLEWARE ’24.
- Paul Richmond, Robert Chisholm, Peter Heywood, Mozhgan Kabiri Chimeh, and Matthew Leach. 2023. FLAME GPU 2: A framework for flexible and performant agent based simulation on GPUs. In Software: Practice and Experience.
- Yakun Sophia Shao, Jason Cemons, Rangharajan Venkatesan, Brian Zimmer, Matthew Fojtik, Nan Jiang, Ben Keller, Alicia Klinefelter, Nathaniel Pinckney, Priyanka Raina, Stephen G. Tell, Yanqing Zhang, William J. Dally, Joel Emer, C. Thomas Gray, Brucek Khailany, and Stephen W. Keckler. 2021. Simba: Scaling Deep-Learning Inference with Chiplet-Based Architecture. In MICRO ’21.
- P. Stotko, S. Krumpen, M. B. Hullin, M. Weinmann, and R. Klein. 2019. SLAMCast: Large-Scale, Real-Time 3D Reconstruction and Streaming for Immersive Multi-Client Live Telepresence. In IEEE Transactions on Visualization and Computer Graphics.
- Christian R. Trott, Damien Lebrun-Grandié, Daniel Arndt, Jan Ciesko, Vinh Dang, Nathan Ellingwood, Rahulkumar Gayatri, Evan Harvey, Daisy S. Hollman, Dan Ibanez, Nevin Liber, Jonathan Madsen, Jeff Miles, David Poliakoff, Amy Powell, Sivasankaran Rajamanickam, Mikael Simberg, Dan Sunderland, Bruno Turcksin, and Jeremiah Wilke. 2022. Kokkos 3: Programming Model Extensions for the Exascale Era. In IEEE TPDS ’22.
- W Hwu Wen-mei. 2015. Heterogeneous System Architecture: A new compute platform infrastructure. In Morgan Kaufmann.
- Jingyue Wu, Artem Belevich, Eli Bendersky, Mark Heffernan, Chris Leary, Jacques Pienaar, Bjarke Roune, Rob Springer, Xuetian Weng, and Robert Hundt. 2016. GPUCC - An Open-Source GPGPU Compiler. In CGO ’16.
- Hangchen Yu, Arthur Michener Peters, Amogh Akshintala, and Christopher J. Rossbach. 2020. AvA: Accelerated Virtualization of Accelerators. In ASPLOS ’20.

This work is licensed under a Creative Commons Attribution 4.0 International License.
HCDS '25, Rotterdam, Netherlands
© 2025 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-1470-2/25/03.
DOI: https://doi.org/10.1145/3723851.3723860