TGEditor: Task-Guided Graph Editing for Augmenting Temporal Financial Transaction Networks
DOI: https://doi.org/10.1145/3604237.3626883
ICAIF '23: 4th ACM International Conference on AI in Finance, Brooklyn, NY, USA, November 2023
Recent years have witnessed a growth of research interest in designing powerful graph mining algorithms to discover and characterize the structural pattern of interests from financial transaction networks, motivated by impactful applications including anti-money laundering, identity protection, product promotion, and service promotion. However, state-of-the-art graph mining algorithms often suffer from high generalization errors due to data sparsity, data noisiness, and data dynamics. In the context of mining information from financial transaction networks, the issues of data sparsity, noisiness, and dynamics become particularly acute. Ensuring accuracy and robustness in such evolving systems is of paramount importance. Motivated by these challenges, we propose a fundamental transition from traditional mining to augmentation in the context of financial transaction networks. To navigate this paradigm shift, we introduce TGEditor, a versatile task-guided temporal graph augmentation framework. This framework has been crafted to concurrently preserve the temporal and topological distribution of input financial transaction networks, whilst leveraging the label information from pertinent downstream tasks, denoted as $\mathcal {T}$, inclusive of crucial downstream tasks like fraudulent transaction classification. In particular, to efficiently conduct task-specific augmentation, we propose two network editing operators that can be seamlessly optimized via adversarial training, while simultaneously capturing the dynamics of the data: Add operator aims to recover the missing temporal links due to data sparsity, and Prune operator is formulated to remove irrelevant/noisy temporal links due to data noisiness. Extensive results on financial transaction networks demonstrate that TGEditor 1) well preserves the data distribution of the original graph and 2) notably boosts the performance of the prediction models in the tasks of vertex classification and fraudulent transaction detection.
ACM Reference Format:
Shuaicheng Zhang, Yada Zhu, and Dawei Zhou. 2023. TGEditor: Task-Guided Graph Editing for Augmenting Temporal Financial Transaction Networks. In 4th ACM International Conference on AI in Finance (ICAIF '23), November 27--29, 2023, Brooklyn, NY, USA. ACM, New York, NY, USA 8 Pages. https://doi.org/10.1145/3604237.3626883
1 INTRODUCTION
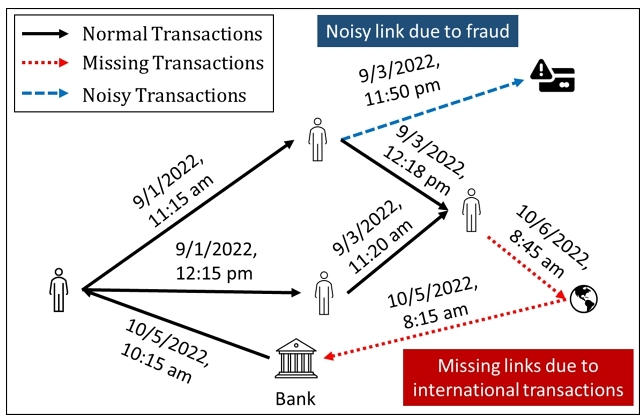
The financial transaction network provides a powerful data model to represent and organize massive financial transactions [2, 18]. An illustrative example of financial transaction networks is presented in Figure 1. It is crucial for financial institutions to understand the underlying transaction patterns motivated by high-stakes applications, such as anti-money laundering [27], identity protection [9, 27], product promotion [21], and service promotion [10],etc. In the past decades, a wealth of theories [8, 29], algorithms [5, 40] and open-source systems [12, 13] have been developed to mine the patterns of interest on financial transaction networks.
Despite the tremendous success, the performance of temporal graph mining approaches on financial transaction networks often suffers from high generalization errors, which are mainly constituted by the following three factors. 1) Data Sparsity: Real-world financial transaction networks are naturally sparse, i.e., the transaction records at a certain timestamp only occur among a relatively small subset of entities, compared with the massive transaction network. 2) Data Noisiness: The intricate process of data extraction and cleaning for these financial transaction networks can inadvertently introduce uncertainties. This uncertainty reflected in the constructed financial transaction networks can lead to redundant, missing, or even incorrect features and structures. 3) Data Dynamics: Realistic financial transactions are evolving in continuous time with multiple resolutions (e.g., seconds, minutes, hours, and days), whereas existing work often represent it as temporal graph snapshots with a certain resolution. In addition to these challenges, financial transaction networks often contain sensitive data, limiting the direct utilization of features like transaction amounts. Therefore, our paper primarily focuses on the structural patterns of these networks, paving the way for a more comprehensive and secure analysis.
Given these characteristics of financial transaction networks, a natural way to address these challenges is through structure-wise data augmentation. Data augmentation provides a powerful solution to address data contaminations and has gained phenomenal success in image and text data [4, 15]. The general strategy is to improve the training data by either injecting newly created synthetic data or modifying the existing contaminated data. More recently, a few lines of work [19, 32] have been proposed to augment the graph-structured data. However, some fundamental research questions largely remain nascent: C1. Task Guidance: when label information or prior knowledge from downstream tasks (e.g., anti-money laundering) is available, how can we conduct task-specific data augmentation (e.g., completing missing links due to international transactions in Figure 1) to improve the generalization performance of learning models? C2. Network Evolution: most of the existing techniques are designed for static networks, while many realistic networks are intrinsically dynamic. How can we automatically perform data augmentation for financial transaction networks, where the graph topology and the label distribution of downstream tasks are evolving over time? C3. Structure Preserving: the general learning objective of existing graph augmentation tools [31, 36] is to maximize the performance of downstream tasks without controlling the number of modifications. We argue that out-of-control data augmentation may inject artificial bias into data and thus deteriorate the generalization performance in the downstream tasks.
To answer the above questions, we propose to shift the paradigm from mining to augmenting financial transaction networks. In particular, given a task $\mathcal {T}$ on a financial transaction network G, how can we improve the performance of $\mathcal {T}$ by editing the local structure of G, while well preserving the structural and temporal distribution of G? To address this problem, we propose TGEditor, a generic task-guided financial transaction network augmentation framework. To address C1, we propose a task-guided context extractor that extracts network contextual information by preserving the graph evolution process of financial transaction networks conditioned on a specific task $\mathcal {T}$. To address C2, we propose a multi-resolution temporal generative model which jointly learns and infers from the financial transaction network's multi-resolution temporal properties and topological properties. To address C3, we propose a financial transaction editor which performs task-specific data augmentation via graph editing operations, including Add that aims to recover the missing temporal links due to data sparsity, and Prune that is formulated to remove irrelevant/noisy temporal links due to data noisiness.
To the best of our knowledge, this paper is one of the first works of data augmentation for dynamic financial transaction networks. Our contributions are summarized as follows.
- Problem.We formalize the financial transaction networks augmentation problem and identify multiple unique challenges inspired by real applications.
- Algorithm. We propose a novel method named TGEditor, which learns the temporal and structure distribution of input graphs and leverages the label information from downstream tasks $\mathcal {T}$ to conduct task-guided data augmentation for financial transaction networks.
- Evaluation. We systematically evaluate the performance of TGEditor from two aspects: 1) how well TGEditor preserves the data distribution of the input data and 2) how much the performance of downstream tasks is improved after conducting augmentation. Extensive results prove the superior performance of TGEditor under both settings.
- Reproducibility. We publish our data and our code, at https://github.com/zshuai8/TGEditor-ICAIF2023.
2 PRELIMINARY
We define the financial transaction network, temporal random walk (TWR), and temporal neighbors as follows.
Definition 2.1 (Financial Transaction Network) A financial transaction network $G = (\mathcal {V}, \mathcal {E})$ consists of a set of vertices (clients) $\mathcal {V} = \lbrace v_1, v_2, \ldots \rbrace$ and a series of timestamped edges (transactions) $\mathcal {E}$. Each transaction ei connects two vertices and is associated with a timestamp denoted by $t_{e_i}$.
Definition 2.2 (Temporal Random Walk) A temporal random walk w is a series of connected temporal edges $\lbrace e^{t_{e_1}}_1, e^{t_{e_2}}_2, \ldots, e^{t_{e_l}}_l\rbrace$ sampled from G following temporal constraints (i.e., $t_{e_i} \le t_{e_{i+1}}$), where l is the walk length and $e^{t_{e_i}}_i$ is directly connected to $e^{t_{e_{i+1}}}_{i+1}$.
Definition 2.3 (Temporal Graph Neighborhood) Given a temporal vertex vi, the spatial and temporal neighborhood $\mathcal {N}$ associated with it is defined as $\mathcal {N} = \lbrace v_i^{t_{v_i}} \mid D_{spa}(v_i^{t_{v_i}},v_j^{t_{v_j}}) \le d_{spa}, D_{tem}(t_{v_i},t_{v_j}) \le d_{tem}\rbrace$, where Dspa(vi, vj) indicates the spatial distance (shortest path) from vertex vi to vj and i ≠ j, $D_{tem}(t_{v_i},t_{v_j})$ indicates the temporal distance from time stamp $t_{v_i}$ to $t_{v_j}$, and dspa and dtem are user-defined spatial distance and temporal distance thresholds, respectively.
In our problem formulation, we consider a financial transaction network with a limited number of labeled transactions from $|\mathcal {C}|$ classes, where the classes are determined by the downstream task. Without loss of generality, we denote the labeled set for the downstream tasks $\mathcal {T}$ as $\mathcal {L}$ = {v1, v2,... $v_{|\mathcal {L}|}$ }. Our objective is to utilize this label information to modify a sparse graph by adding "missing" links and removing "noisy" links. For instance, as depicted in Figure 1, there are three categories of transactions: normal, missing, and noisy transactions. By augmenting the provided financial transaction network (e.g., by adding missing links highlighted in red or removing noisy links colored in blue), patterns of interest (e.g., fraudulent transactions) become more pronounced, thereby facilitating their identification by machine learning (ML) models. In this paper, our goal is to learn a data augmentation function $\mathcal {G}_\theta$ that maintains the true data distribution, enabling us to fill in the missing links and eliminate the noisy links in the observed financial transaction network G. We formally define the problem as follows:
Problem 1 Financial Transaction Network Augmentation
Given: 1) An observed directed financial transaction network G= ($\mathcal {V}$, $\mathcal {E}$), 2) Task-specific vertex labels or edge labels.
Find: The structurally augmented $\tilde{G}$ that 1) enhances performance on downstream task $\mathcal {T}$ (i.e., node classifications and fraudulent transaction prediction), 2) preserves the topological and temporal properties of the input temporal graph G, and 3) is consistent with the label information.
3 MODEL
In this section, we introduce a generic learning framework named TGEditor, a deep graph generative model specifically designed for data augmentation on financial transaction networks. In the following subsections, we first present the overall architecture of TGEditor and then dive into the technical details of its three key modules. At last, we provide an optimization algorithm for training TGEditor.
3.1 ${\rm TGE{\small DITOR}}$ framework
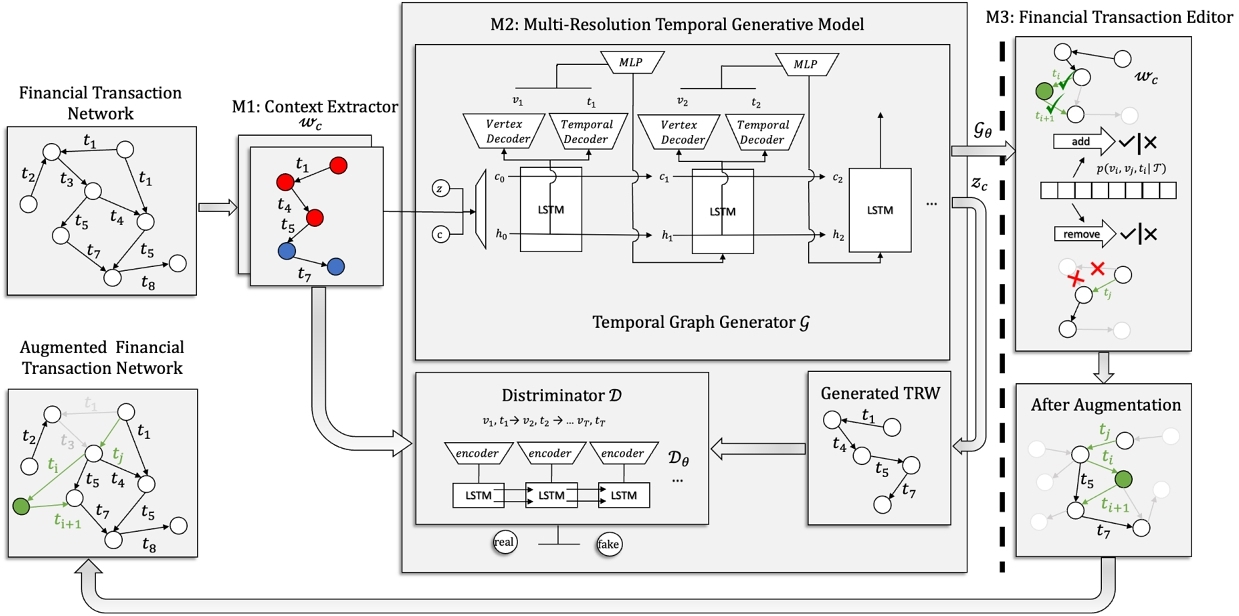
An overview of our proposed ${\rm TGE{\small DITOR}}$ framework is presented in Figure 2 which consists of three modules: M1) Task-Guided Context Extractor, M2) Multi-Resolution Temporal Generative Model, and M3) Financial Transaction Editor. Given a financial transaction network, M1 first extracts task-guided network contextual information of financial transaction networks by sampling a set of TRW sequences $\mathcal {W}_c$ conditioned on a specific task $\mathcal {T}$ [23]. In M2, we develop a multi-resolution context generative model which consists of a TRW generator and a TRW discriminator to approximate the joint topological and temporal distribution of G, i.e., $p(v^{t_{v}} | G, \mathcal {T})$. In this module, we learn important task-guided contextual information from the extracted task-specific TRW sequences $\mathcal {W}_c$ in M1. In M3, we propose a novel financial transaction editor to augment G by proposing a handful of editions, including Add aims to recover the missing temporal links due to data sparsity, and Prune is formulated to remove irrelevant/noisy temporal links due to data noisiness.
M1. Task-Guided Context Extractor. In the field of graph-based data augmentation, prior methods have primarily been unsupervised, utilizing pre-established augmentation techniques such as structural perturbation and graph diffusion (e.g., structural-wise perturbation [28] and graph diffusion [11], contrastive learning [37]). However, these unsupervised approaches may not guarantee optimal performance in downstream tasks, particularly when label information is available. For instance, in the context of financial fraud detection, it is commonly observed that fraudsters are rare and skilled at evading detection systems. As a result, unsupervised data augmentation methods may not effectively emphasize fraudulent patterns without supervision. Furthermore, improper data augmentation may introduce artificial biases and degrade overall performance. Motivated by these considerations, we propose a task-guided context extractor that leverages both the input data G and the label information $\mathcal {L}$ from the downstream tasks $\mathcal {T}$ to achieve improved performance. Given a financial transaction network G with a label set $\mathcal {L}$ from the downstream task $\mathcal {T}$, M1 aims to extract task-specific contextual information to train M2. We utilize the technique of Temporal Random Walks (TRW) as a tool for sampling and extracting contextual information, such as neighborhood topology and temporal properties, from the given financial transaction network.
A straightforward approach to capture task-specific contextual information would be to conduct TRWs starting from each labeled vertex in $\mathcal {L}$. However, the label set may consist of both representative and boundary examples, such as examples located at the center versus the boundary of the support region of a class. To effectively capture task-specific contextual information, it is crucial to understand the task-specific contextual importance of each vertex in the labeled set $\mathcal {L}$.
We propose to quantify the task-specific contextual importance of each vertex $v^{t_{v}}$ in the labeled set $\mathcal {L}$ through the following conditional probability:
(1)
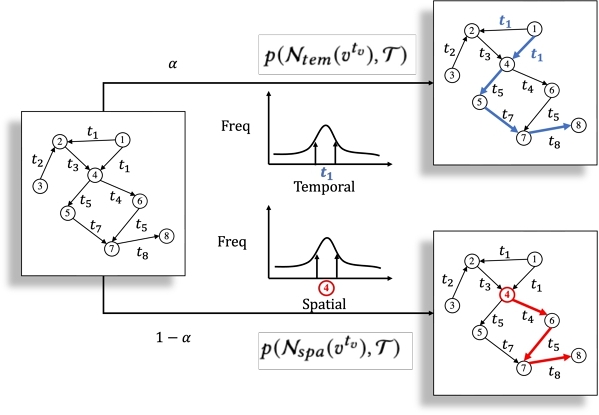
The results from many existing literature [1, 41] indicate a weak relationship between spatial distribution and temporal distribution in realistic temporal networks: vertices with high degrees tend to be active in future timestamps, while those with low degrees tend to be inactive. Specifically, clients who are highly active in making transactions are more likely to continue doing so in the future, whereas clients who are less active in making transactions are less likely to do so in the future. Following [1, 41], in this paper, we make the assumption that the task-specific topological distribution $p(v^{t_{v}} | \mathcal {N}_{spa}(v^{t_{v}}), \mathcal {T})$ and the task-specific temporal distribution $p(v^{t_{v}} | \mathcal {N}_{tem}(v^{t_{v}}), \mathcal {T})$ follow a weakly independent relationship. With that, we have, for δ > 0,
Based on the above equation, we propose a novel contextual sampling strategy. For each class c in $\mathcal {T}$, we sample a collection of TRWs with the length of T as $\mathcal {W}_c = \lbrace \mathbf {w}_1...\mathbf {w}_{|\mathcal {W}_c|} |c \in \mathcal {T}\rbrace$. With probability of α ∈ [0, 1], we sample temporal-guided graph context from vertices with high $p(v^{t_{v}} | \mathcal {N}_{tem}(v^{t_{v}}), \mathcal {T})$. With probability 1 − α, we sample spatial-guided graph context from vertices with high $p(v^{t_{v}} | \mathcal {N}_{spa}(v^{t_{v}}), \mathcal {T})$. By sampling representative vertices from both distributions, we aim to maximally capture topological and temporal properties for the given class c from G. In Figure 3, we show an illustrative example of how to jointly extract temporal and spatial neighborhood contextual information. After selecting corresponding class representative vertices, we use label-informed TRW sampler [24] to extract TRWs from each class, which will be fed into M2 for training purposes.
M2. Multi-Resolution Temporal Generative Model. Through M1, we extract task-guided temporal random walks (TRW) $\mathcal {W}_c$ that preserve the temporal and topological properties of the financial transaction network and the label information from downstream tasks $\mathcal {T}$. Most existing methods for learning temporal graph representations from TRWs, such as [40, 41], are task-agnostic and rely heavily on preprocessing steps to transform the temporal transactions from multi-resolution to single resolution (e.g., coarsening the resolution of timestamps in days as shown in Figure 1). To overcome this limitation, we propose to jointly utilize the extracted TRWs $\mathcal {W}_c$ and label information to infer the task-guided conditional probability distribution of temporal edges $p(v_i, v_j, t_i | \mathcal {T})$ in the given financial transaction network G, where {vi, vj ∈ G, ti} is a set of continuous timestamps, and $\mathcal {T}$ is the downstream task. By learning this distribution, we can better understand how a client vertex from class c interacts with other client vertices temporally and topologically, given the task $\mathcal {T}$. However, directly approximating this distribution is challenging due to the correlation between (vi, vj, ti). Inspired by [23], we propose to model the distribution of $p(v_i, v_j, t_i | \mathcal {T})$ in a conditional generative manner. The proposed method utilizes a temporal generator $\mathcal {G}_{\theta }$ with two decoders to separately decode a vertex $v_{t_i}$ and continuous timestamp ti. Additionally, a discriminator $\mathcal {D_{\theta }}$ is used to evaluate a sequence of TRWs to identify whether they are true TRWs sampled from G or ones generated by the temporal generator $\mathcal {G}_{\theta }$. The overall objective function of M2 is defined as:
Generator. We aim to generate TRW samples from class c to explicitly capture temporal and topological properties from class c. A latent vector is initialized as a multi-variant vector $\mathbf {z} \in \mathcal {N}(0, \mathbf {I}_d)$ which is a multi-variant normal distribution. A one-hot vector of class c is further concatenated with z to form the initial label-informed latent vector zc. As shown in Figure 2, in each LSTM cell, there are mainly two sub-modules: a vertex decoder and a temporal decoder. The vertex decoder decodes a client vertex with the highest probability from learned $\mathcal {G}_{\theta }$ and LSTM state hi, c. The temporal decoder decodes a timestamp from the current LSTM hidden state hi following the temporal constraint (i.e., $t_{e_i} \le t_{e_{i+1}}$) and prior temporal distributions. Specifically, in each unique time step i, an LSTM cell produces a cell state vector mi, c and a hidden state vector hi, c as input. The concatenated cell state is denoted as $\mathbf {\tilde{m}}_{i,c}$. The detailed process is shown in Figure 4, where ‖ denotes a concatenate operation.
Discriminator. The discriminator $\mathcal {D}$ uses a standard LSTM architecture. At each time step, a one-hot vertex representation vt and a temporal representation t are concatenated as input to the LSTM cells. After processing the entire sequence of T vertices, the discriminator outputs a logit indicating the probability of the input TRW being sampled from G. With the Temporal Graph Generator, $\mathcal {G}_{\theta }$, and Discriminator, $\mathcal {D}_{\theta }$, the model learns the joint probability distribution of $p(v_i, v_j, t_i | \mathcal {T})$ to characterize properties of G. This information is used in M3 to augment the financial transaction network through the financial transaction editor in M3.

M3. Financial Transaction Editor. In M2, we learn a multi-resolution temporal generative model $\mathcal {G}_{\theta }$, which samples from a task-guided joint temporal edge probability distribution $p(v_{i}, v_j, t_i | \mathcal {T})$. To answer C3, we propose an augmentation constraint to preserve most G’s temporal and topological properties while fully capturing label information without "over-augmenting" (i.e., injecting extensive artificial biases) which may hurt the performance on a downstream task $\mathcal {T}$. In particular, we take sampled W as a basis for augmentation, without perturbation from these artificial biases. To this goal, we propose a general financial transaction editor module that consists of two graph editing operations{${\tt add}$, ${\tt prune}$}:
- add: The add operation is done in a three-step fashion. First, we decode the joint probability distribution p(v1, v2, t1) of candidate vertices from the output of the vertex decoder and temporal decoder. At each time step, we examine whether argmax(p(vi|v1, v2, t1)) is over our add threshold ζadd. As shown in Figure 2, vargmax and ti are decoded from a temporal vertex decoder and a time decoder, respectively. For each instance, only one edge is added to avoid over-editing.
- prune: The prune operation is similar to the add operation, but instead of adding an edge to $\mathcal {G}$, we prune edges associated to the current vertex if p(vi − 1, vi, ti) is lower than our prune threshold ζprune for the purpose of consistency.
In addition to $\mathcal {G}_{\theta }$ and $\mathcal {D}_{\theta }$, a TRW editor discriminator $\mathcal {D}_{\mathcal {W}}$ is introduced to prevent overediting if an edited sequence z is less likely preserving G’s network properties.
4 EXPERIMENTS
In this section, we evaluate the performances of the ${\rm TGE{\small DITOR}}$ framework using five synthetic datasets. The following sections introduce the experimental setup, quantitative analysis of network properties and data augmentation.
4.1 Experimental Setup
Datasets. We evaluate ${\rm TGE{\small DITOR}}$ on 5 real temporal graphs with vertex labels/edge labels, including variations of DBLP [41], SO [41], Chase [2], Bitcoin [34]. DBLP and SO are temporal collaboration networks, Chase [2] is a temporal fraudulent transaction network, and Bitcoin [34] is an anti-money laundering temporal transaction network.
| Datasets | $|\mathcal {V}|$ | $|\mathcal {E}|$ | $|\mathcal {T}|$ | $|\mathcal {C}|$ | Vertex Class. | Fraud Pred. |
| SO | 9298 | 23540 | 10 | 3 | ✓ | |
| DBLP | 3263 | 19926 | 36 | 2 | ✓ | |
| Chase | 3390 | 17314 | 101 | 2 | ✓ | |
| Bitcoin | 10970 | 86368 | 36 | 3 | ✓ |
Comparison Methods. We compare ${\rm TGE{\small DITOR}}$ with baseline models in two different aspects: 1) Temporal graph generative model adapted for data augmentation [2] and 2) traditional graph data augmentation methods [3]. For 1), we further divide our baseline models into two sets of models: Static graph generative models (i.e., Barabási Albert (BA) [3]) and temporal graph generative models (TagGen [41] and TGGAN [40]). To uniformly compare methods on financial transaction networks and other temporal graphs, we use a well-known embedding method HTNE [42] as a basis to process augmented graph $\tilde{G}$ from our baseline methods and the proposed methods. We then use logistic regression to evaluate the models’ performances on the downstream tasks.
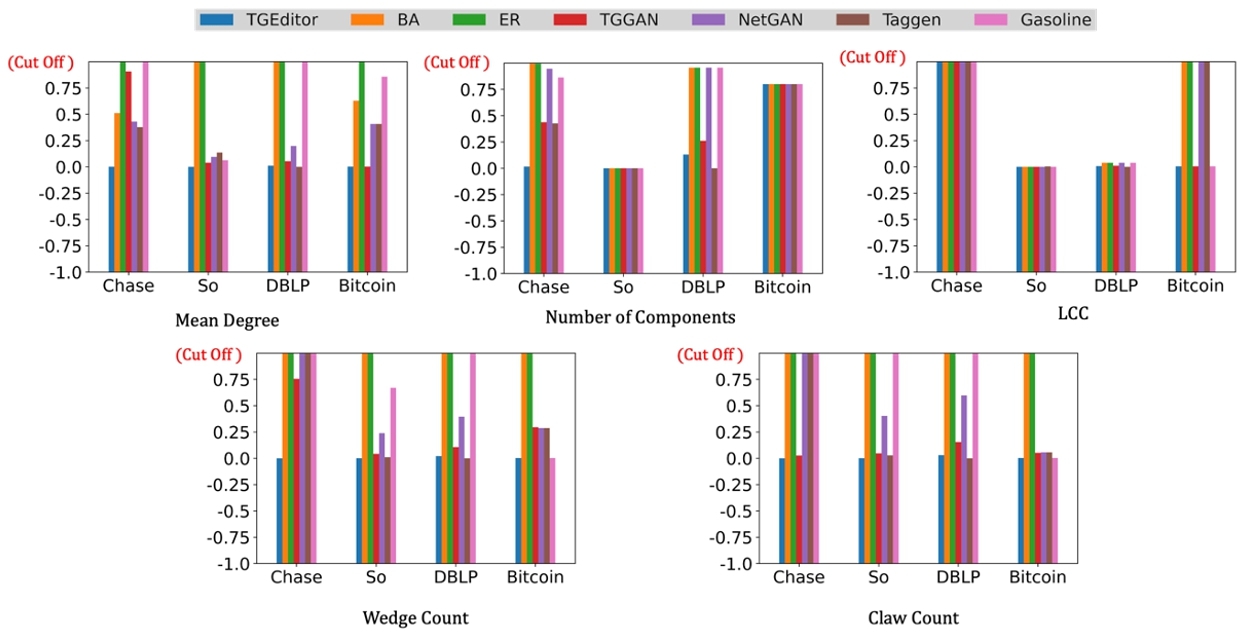
Evaluation Metrics. We evaluate performances with baseline models in two aspects: 1) network properties and 2) effectiveness on downstream tasks (vertex classification and fraud detection). For evaluating network properties, we consider five widely-used network properties (i.e., Mean Degree, Number of components, LCC, Wedge Count, Claw Count) for evaluation. They help us how well a given model preserves the topological properties of a given financial transaction network. Given input financial transaction network G, the augmented network $\tilde{G}$ and the evaluating metric $\tilde{m}$, we measure each property $f_{\tilde{m}}(\cdot)$ as follows.
4.2 Quantitative Results in Preserving Network Properties
From our evaluation results, we draw several interesting observations from these results. 1) ${\rm TGE{\small DITOR}}$ outperforms the baseline methods across the five evaluation metrics and four datasets in most of the cases. 2) Two random graphs (i.e., BA and ER) generated $\tilde{G}$s have the worst performance. We suspect such random graph algorithms are often designed to model a certain structural distribution (e.g., n-component distribution) which leads to a lack of understanding of capturing many other network properties (e.g., LCC the largest connected component of the graph). (3) Deep generative models (NetGAN, TGGAN, TagGen) have outperformed random graph generators and the graph augmentation model (GASOLINE) but are not comparable with ${\rm TGE{\small DITOR}}$ in most cases even though it shows competitive performance on classification tasks. From our assumptions, we suspect the following reasons why our ${\rm TGE{\small DITOR}}$ is better compared with other baseline models: 1) Task guidance from label-informed TRWs helps ${\rm TGE{\small DITOR}}$ framework preserve and understand topological properties.
2) ${\rm TGE{\small DITOR}}$ framework's $D_{\mathcal {W}}$ prevents ${\rm TGE{\small DITOR}}$ framework from overediting G to minimally alters the topological properties.
Overall, from our observations, we find TGEditor accurately captures and preserves G’s topological properties.
4.3 Quantitative Results in Data Augmentation
In this subsection, we compare ${\rm TGE{\small DITOR}}$ framework with 6 baseline methods across 4 datasets on 2 evaluation downstream tasks: vertex classification and fraudulent transaction identification. We split the data set into training and test sets with the three sets of ratio: 10% training set: 90% test set, 15% training set: 85% test set, and 20% training set: 80% test set. Each experiment is repeated five times, and we report the average score (recall for fraudulent transaction indentification or Marco F1 score for vertex classification) across 4 datasets in Table 2 and Table 3.
| Model | SO | DBLP | ||||
|---|---|---|---|---|---|---|
| 10% | 15% | 20% | 10% | 15% | 20% | |
| HTNE | 43.79 | 44.25 | 45.24 | 30.68 | 29.53 | 31.31 |
| NetGAN | 45.39 | 46.29 | 46.49 | 28.97 | 30.10 | 30.78 |
| TAGGEN | 45.61 | 46.70 | 47.1 | 31.23 | 31.79 | 32.54 |
| TGGAN | 46.21 | 46.34 | 47.52 | 31.73 | 32.33 | 32.47 |
| GASOLINE | 46.02 | 46.81 | 48.31 | 32.32 | 33.44 | 34.06 |
| Graph Editor | 47.21 | 48.12 | 49.36 | 32.45 | 32.83 | 34.12 |
Vertex Classification. In this task, we use the SO and DBLP datasets for temporal collaboration graph classification. The goal is to predict vertex labels based on the model's understanding of temporal and topological context. Results in Table 2 show that: 1) HTNE, a temporal graph embedding method, performs the worst due to its lack of deep understanding of topological and temporal attributes. 2) Deep generative models (NetGAN, TGGAN, TagGen) perform better than HTNE but underperform compared to the traditional graph data augmentation model (GASOLINE) and TGEditor. This is likely due to the fact that temporal collaboration networks are not sensitive to temporal attributes and topological properties are more important for classifying vertices. 3) ${\rm TGE{\small DITOR}}$ outperforms other baseline models, demonstrating that task-guided label information can be a key factor in augmenting a temporal graph and improving performance on vertex classification tasks.
| Model | Chase | Bitcoin | ||||
|---|---|---|---|---|---|---|
| 10% | 15% | 20% | 10% | 15% | 20% | |
| HTNE | 43.85 | 48.34 | 49.70 | 37.31 | 39.12 | 39.44 |
| NetGAN | 48.12 | 50.23 | 51.45 | 40.17 | 39.44 | 42.32 |
| TAGGEN | 50.08 | 51.42 | 53.40 | 43.52 | 45.31 | 47.03 |
| TGGAN | 50.38 | 52.44 | 55.75 | 46.27 | 45.92 | 48.91 |
| GASOLINE | 54.24 | 53.84 | 58.59 | 44.24 | 45.12 | 47.81 |
| Graph Editor | 52.43 | 55.28 | 60.12 | 48.31 | 49.12 | 50.24 |
Fraudulent Transaction Identification. The detection of fraudulent transactions is a critical problem for financial institutions. This task is challenging due to the time-sensitive and complex nature of the problem, as fraudulent transactions are often large in scale and the sparsity of financial transaction networks G presents a significant challenge for models to generalize effectively. We demonstrate a detailed comparison across different models in this task in TABLE 3. In our experiments, we employed an MLP-based classification approach to determine whether a given edge, e, in the network, represented by the concatenation of two vertex embeddings, v1 and v2, e = [v1, v2], is fraudulent or not, based on the encoded contextual information. Our proposed method, TGEditor, outperforms other methods, including GASOLINE and other deep generative models. This is attributed to the incorporation of task-guided label information, $\mathcal {L}$, and multi-resolution properties in TGEditor, which addresses the challenges of sparsity in financial transaction networks. Furthermore, ${\rm TGE{\small DITOR}}$ preserves both topological and temporal properties of the original network, G, minimizing the potential injection of noisy information into the augmented network, $\tilde{G}$. Overall, the comparison experiments demonstrate that ${\rm TGE{\small DITOR}}$ effectively improves the generalization performance of the augmented financial transaction network $\tilde{G}$ across all datasets.
5 RELATED WORK
In this section, we briefly review the existing literature in the context of learning on financial transaction networks, temporal graph mining, and data augmentation on graphs.
ML on financial transaction network. ML has gained a significant impact in the field of finance. Researchers have explored various techniques to understand transaction patterns from financial transaction networks for different purposes (i.e., promotion, and fraud detection). Existing ML works are mainly focused on two categories: graph embedding-based methods and graph neural network (GNN) based methods. The graph embedding-based methods[22, 35] aim to embed important financial attributes(i.e., transaction amount, merchant types) and implicit topological information to vertices. But such methods usually perform worse than GNN methods since their understanding of interactions between vertices is much more shallow. GNN-based methods[14, 17] can fully utilize topological patterns but often disregard the importance of temporal patterns. In our work, we propose a general framework, which benefits from both characteristics to help state-of-the-art temporal graph mining algorithms to generalize better on various tasks.
Data augmentation on graphs. Data augmentation is pivotal in improving ML models’ generalization for downstream tasks. Generally, three types of graph augmentation exist 1) Feature-wise augmentation, which includes feature generation [20], and perturbation [30]. 2) Label-wise augmentation that deals with sparse label information via pseudo-labeling [7] and data mixup [39]. 3) Structure-wise augmentation involving edge/vertex perturbation, graph diffusion (e.g., Personalized Pagerank [25], heat kernel [16]), graph sampling [26], and graph generation [38]. Moving these ideas to temporal graphs, [33] pioneered a multi-level module augmenting temporal graphs via time perturbation, and edge addition and removal. We present a framework modeling and editing temporal graphs to amplify task-specific temporal and topological patterns. This augmentation benefits downstream tasks with particular class patterns. To our knowledge, TGEditoris the first deep generative temporal graph augmentation model.
6 CONCLUSION
We presented TGEditor, a novel deep generative financial transaction network editor, which augments financial transaction networks on various downstream tasks $\mathcal {T}$ by incorporating task-guided label information while preserving topological and temporal properties. We present comprehensive evaluations of TGEditor by conducting the quantitative evaluation in network properties and two data augmentation downstream tasks (vertex classification and fraudulent transaction identification). We observe that: 1) ${\rm TGE{\small DITOR}}$ consistently outperforms the baseline methods on preserving the network properties. 2) ${\rm TGE{\small DITOR}}$ significantly boosts the generalization power of prediction models from augmented $\tilde{G}$ on vertex classification and fraudulent transaction identification approaches. Extensive empirical results show that ${\rm TGE{\small DITOR}}$ is reliable and effective in alleviating challenges of data sparsity, data noisiness, and data dynamics.
ACKNOWLEDGMENTS
We thank the anonymous reviewers and area chair for their valuable time and constructive comments. This work is supported by Virginia Tech, Cisco, Deloitte, Commonwealth Cyber Initiative, 4-VA, and MIT-IBM Watson AI Lab – a research collaboration as part of the IBM AI Horizons Network. The views and conclusions are those of the authors and should not be interpreted as representing the official policies of the funding agencies or the government.
REFERENCES
- Steven Abney. 2002. Bootstrapping. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, 360–367. https://doi.org/10.3115/1073083.1073143
- Samuel A Assefa, Danial Dervovic, Mahmoud Mahfouz, Robert E Tillman, Prashant Reddy, and Manuela Veloso. 2020. Generating synthetic data in finance: opportunities, challenges and pitfalls. In Proceedings of the First ACM International Conference on AI in Finance. 1–8.
- Albert-László Barabási and Réka Albert. 1999. Emergence of scaling in random networks. science (1999).
- Markus Bayer, Marc-André Kaufhold, and Christian Reuter. 2021. A survey on data augmentation for text classification. Comput. Surveys (2021).
- Aleksandar Bojchevski, Oleksandr Shchur, Daniel Zügner, and Stephan Günnemann. 2018. NetGAN: Generating Graphs via Random Walks. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018. 609–618.
- Zdravko I Botev, Joseph F Grotowski, and Dirk P Kroese. 2010. Kernel density estimation via diffusion. The annals of Statistics (2010).
- Paola Cascante-Bonilla, Fuwen Tan, Yanjun Qi, and Vicente Ordonez. 2021. Curriculum labeling: Revisiting pseudo-labeling for semi-supervised learning. In Proceedings of the AAAI Conference on Artificial Intelligence.
- Arnaud Casteigts, Kitty Meeks, George B Mertzios, and Rolf Niedermeier. 2021. Temporal graphs: Structure, algorithms, applications (dagstuhl seminar 21171). In Dagstuhl Reports. Schloss Dagstuhl-Leibniz-Zentrum für Informatik.
- Dawei Cheng, Xiaoyang Wang, Ying Zhang, and Liqing Zhang. 2020. Graph neural network for fraud detection via spatial-temporal attention. IEEE Transactions on Knowledge and Data Engineering (2020).
- Lianyue Feng, Helian Xu, Gang Wu, and Wenting Zhang. 2021. Service trade network structure and its determinants in the Belt and Road based on the temporal exponential random graph model. Pacific Economic Review (2021).
- Johannes Gasteiger, Stefan Weißenberger, and Stephan Günnemann. 2019. Diffusion Improves Graph Learning. In Conference on Neural Information Processing Systems (NeurIPS).
- Wentao Han, Kaiwei Li, Shimin Chen, and Wenguang Chen. 2018. Auxo: a temporal graph management system. Big Data Mining and Analytics (2018).
- Thomas Hartmann, Francois Fouquet, Matthieu Jimenez, Romain Rouvoy, and Yves Le Traon. 2017. Analyzing complex data in motion at scale with temporal graphs. (2017).
- Jianguo Jiang, Jiuming Chen, Tianbo Gu, Kim-Kwang Raymond Choo, Chao Liu, Min Yu, Weiqing Huang, and Prasant Mohapatra. 2019. Anomaly detection with graph convolutional networks for insider threat and fraud detection. In MILCOM 2019-2019 IEEE Military Communications Conference (MILCOM). IEEE, 109–114.
- Nour Eldeen Khalifa, Mohamed Loey, and Seyedali Mirjalili. 2021. A comprehensive survey of recent trends in deep learning for digital images augmentation. Artificial Intelligence Review (2021), 1–27.
- Risi Imre Kondor and John Lafferty. 2002. Diffusion kernels on graphs and other discrete structures. In Proceedings of the 19th international conference on machine learning.
- Wataru Kudo, Mao Nishiguchi, and Fujio Toriumi. 2020. GCNEXT: graph convolutional network with expanded balance theory for fraudulent user detection. Soc. Netw. Anal. Min. (2020). https://doi.org/10.1007/s13278-020-00697-w
- Eren Kurshan, Hongda Shen, and Haojie Yu. 2020. Financial crime & fraud detection using graph computing: Application considerations & outlook. In 2020 Second International Conference on Transdisciplinary AI (TransAI). IEEE, 125–130.
- Guangyao Li, Zequn Sun, Lei Qian, Qiang Guo, and Wei Hu. [n. d.]. Rule-based data augmentation for knowledge graph embedding. AI Open ([n. d.]).
- Songtao Liu, Rex Ying, Hanze Dong, Lanqing Li, Tingyang Xu, Yu Rong, Peilin Zhao, Junzhou Huang, and Dinghao Wu. 2022. Local augmentation for graph neural networks. In International Conference on Machine Learning. PMLR, 14054–14072.
- Eli Meirom, Haggai Maron, Shie Mannor, and Gal Chechik. 2021. Controlling graph dynamics with reinforcement learning and graph neural networks. In International Conference on Machine Learning. PMLR, 7565–7577.
- Naoto Minakawa, Kiyoshi Izumi, Hiroki Sakaji, and Hitomi Sano. 2022. Graph Representation Learning of Banking Transaction Network with Edge Weight-Enhanced Attention and Textual Information. In Companion Proceedings of the Web Conference 2022. 630–637.
- Mehdi Mirza and Simon Osindero. 2014. Conditional Generative Adversarial Nets. CoRR (2014). arXiv:1411.1784 http://arxiv.org/abs/1411.1784
- Giang Hoang Nguyen, John Boaz Lee, Ryan A Rossi, Nesreen K Ahmed, Eunyee Koh, and Sungchul Kim. 2018. Continuous-time dynamic network embeddings. In Companion proceedings of the the web conference 2018. 969–976.
- Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. 1999. The PageRank citation ranking: Bringing order to the web.Technical Report. Stanford InfoLab.
- Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, and Jie Tang. 2020. Gcc: Graph contrastive coding for graph neural network pre-training. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1150–1160.
- Nitendra Rajput and Karamjit Singh. 2022. Temporal Graph Learning for Financial World: Algorithms, Scalability, Explainability & Fairness. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Washington DC, USA) (KDD ’22). Association for Computing Machinery, 4818–4819.
- Yu Rong, Wenbing Huang, Tingyang Xu, and Junzhou Huang. 2019. Dropedge: Towards deep graph convolutional networks on node classification. arXiv preprint arXiv:1907.10903 (2019).
- Jason Schoeters. 2021. Contributions to temporal graph theory and mobility-related problems. Ph. D. Dissertation. Bordeaux.
- Lichao Sun, Yingtong Dou, Carl Yang, Ji Wang, Philip S Yu, Lifang He, and Bo Li. 2018. Adversarial attack and defense on graph data: A survey. arXiv preprint arXiv:1812.10528 (2018).
- Susheel Suresh, Pan Li, Cong Hao, and Jennifer Neville. 2021. Adversarial graph augmentation to improve graph contrastive learning. Advances in Neural Information Processing Systems (2021).
- Zhenwei Tang, Shichao Pei, Zhao Zhang, Yongchun Zhu, Fuzhen Zhuang, Robert Hoehndorf, and Xiangliang Zhang. 2022. Positive-Unlabeled Learning with Adversarial Data Augmentation for Knowledge Graph Completion. arXiv preprint arXiv:2205.00904 (2022).
- Yiwei Wang, Yujun Cai, Yuxuan Liang, Henghui Ding, Changhu Wang, Siddharth Bhatia, and Bryan Hooi. 2021. Adaptive data augmentation on temporal graphs. Advances in Neural Information Processing Systems (2021).
- Mark Weber, Giacomo Domeniconi, Jie Chen, Daniel Karl I Weidele, Claudio Bellei, Tom Robinson, and Charles E Leiserson. 2019. Anti-money laundering in bitcoin: Experimenting with graph convolutional networks for financial forensics. arXiv preprint arXiv:1908.02591 (2019).
- Yunyi Xie, Jie Jin, Jian Zhang, Shanqing Yu, and Qi Xuan. 2021. Temporal-Amount Snapshot MultiGraph for Ethereum Transaction Tracking. In International Conference on Blockchain and Trustworthy Systems. Springer, 133–146.
- Zhe Xu, Boxin Du, and Hanghang Tong. 2022. Graph sanitation with application to node classification. In Proceedings of the ACM Web Conference 2022. 1136–1147.
- Yuning You, Tianlong Chen, Yang Shen, and Zhangyang Wang. 2021. Graph contrastive learning automated. In International Conference on Machine Learning. PMLR, 12121–12132.
- Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph contrastive learning with augmentations. Advances in Neural Information Processing Systems (2020).
- Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. 2018. mixup: Beyond Empirical Risk Minimization. International Conference on Learning Representations (2018). https://openreview.net/forum?id=r1Ddp1-Rb
- Liming Zhang, Liang Zhao, Shan Qin, and Dieter Pfoser. 2020. TG-GAN: Deep Generative Models for Continuously-time Temporal Graph Generation. CoRR (2020). arXiv:2005.08323 https://arxiv.org/abs/2005.08323
- Dawei Zhou, Lecheng Zheng, Jiawei Han, and Jingrui He. 2020. A Data-Driven Graph Generative Model for Temporal Interaction Networks. In KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, August 23-27, 2020, Rajesh Gupta, Yan Liu, Jiliang Tang, and B. Aditya Prakash (Eds.). ACM, 401–411. https://doi.org/10.1145/3394486.3403082
- Yuan Zuo, Guannan Liu, Hao Lin, Jia Guo, Xiaoqian Hu, and Junjie Wu. 2018. Embedding temporal network via neighborhood formation. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2857–2866.

This work is licensed under a Creative Commons Attribution-NonCommercial International 4.0 License.
ICAIF '23, November 27–29, 2023, Brooklyn, NY, USA
© 2023 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-0240-2/23/11.
DOI: https://doi.org/10.1145/3604237.3626883