1 Introduction
As artificial intelligence (AI) is increasingly used in public services, concerns have grown about bias and misalignment with community values. A growing body of research and public evidence has raised concerns that these AI systems can inadvertently amplify societal inequalities and reproduce systemic biases present in data and institutional practices. For example, biased training data or flawed model design have led to gender and racial disparities in hiring and criminal risk assessment algorithms, prompting public outcry and the rollback of such tools [42]. These cases underscore that without careful oversight, AI can reinforce existing discrimination rather than mitigate it. As a result, calls for heightened fairness, accountability, and transparency in algorithmically informed public decisions are now commonplace [41].
As the adoption of AI expands in public governance, the risks associated with algorithmic opacity and bias carry profound implications for citizens’ rights and well-being. The opacity of many government-used algorithms, from predictive policing systems to social service eligibility scoring, poses challenges for democratic oversight and can erode public trust if decisions are perceived as unfair. Ensuring that AI-driven decisions align with public values has thus become a pressing concern. Prior work highlights that purely technical solutions to algorithmic bias may be insufficient; sustainable governance of AI requires incorporating broader social perspectives and values into the oversight process [7, 41]. In this context, there is a strong argument for directly involving citizens evaluating public-sector AI. Citizen participation can serve as a corrective lens on algorithmic decisions, bringing in local knowledge about community needs and normative expectations of fairness that might be missed by experts alone. Enabling stakeholder participation can also improve the legitimacy of governing institutions and can increase public trust in services [26].
In this paper, we examine non-experts as auditors of public-sector AI. While research has established frameworks for expert-led algorithmic auditing, including technical assessments by data scientists [34], regulatory evaluation protocols [22], and industry-driven bias detection tools [5], little is known about how non-experts can audit AI systems in practice. This raises important questions about auditors’ capacity to perform meaningful evaluations, the role of subjectivity in their assessments, and how they navigate tensions between recognizing bias and translating that awareness into actionable priorities. In addressing these dynamics, we pose the question: How do non-expert auditors apply contextual and value-based reasoning to identify algorithmic harms, prioritize affected groups, and navigate fairness trade-offs in public-sector AI systems?
Our evaluation of auditor dynamics revealed four main findings:
-
auditors demonstrate principled subjectivity, applying consistent value orientations while adapting their evaluations to specific contexts, suggesting they engage in thoughtful rather than arbitrary assessment of algorithmic systems.
-
Auditors can meaningfully differentiate AI risks across domains by using context-sensitive risk evaluations that align with expert-coded severity assessments.
-
awareness of bias does not automatically translate to design prioritization; we observed systematic gaps between bias recognition and actionable design focus, revealing challenges in moving from problem identification to solution planning.
-
auditors function as normative agents rather than mere error detectors, demonstrating that effective auditing involves surfacing latent value tensions rather than simply identifying technical flaws.
2 Background
In this section, we review the literature on public sector AI deployment and algorithmic auditing practices, with particular attention to the limitations of expert-driven approaches and the potential for community-based oversight.
2.1 Public Sector AI and Harm
AI technologies are being rapidly adopted by government agencies across federal, state, and municipal levels. Public sector organizations now use machine learning models for a range of tasks, including predictive analytics for determining benefits eligibility, fraud detection in welfare programs, resource allocation for public housing, and predictive policing to anticipate crime hotspots [1, 9, 16]. These applications promise increased efficiency and data-driven decision-making in domains traditionally guided by human administrators.
While replacing discretionary human judgment with automated systems might streamline operations, it also risks concealing the value judgments and trade-offs inherent in policy decisions. For instance, predictive policing algorithms may disproportionately target neighborhoods of color if trained on historically biased police data, echoing longstanding patterns of over-policing [19]. Similarly, automated welfare eligibility systems might unfairly flag or sanction low-income individuals due to biased design or data, exacerbating feelings of alienation and unfairness.
A particular risk of adoption is that AI tools may not align with local cultural and contextual factors. Many AI systems are developed for broad markets and may embed assumptions or data that do not align with a particular community's needs or values. When a city or agency adopts an off-the-shelf algorithm (e.g., for policing or child protective services), it may not account for local context, leading to misaligned or unfair outcomes [41]. In practice, this could mean that an algorithm trained on data from one jurisdiction performs poorly or inappropriately in another with different demographics or policy priorities. Such misalignment can undermine the tool's effectiveness and legitimacy in the eyes of both officials and the public.
Therefore, without adequate oversight, public-sector AI systems could reinforce existing power imbalances, biases, and institutional inequities, thereby undermining democratic accountability and eroding public trust in government institutions.
2.2 Evaluating AI through Audits
In recent years, there has been considerable momentum in developing frameworks, guidelines, and tools for auditing AI systems for potential issues such as bias, unfairness, and broader societal harms (e.g., [2, 5, 8, 29]). An algorithm audit is a technique that systematically interacts with an algorithm and analyzes its outputs to infer details about its internal processes and potential external consequences [28].
Most algorithm audits are conducted by specialized groups, including industry professionals, academic researchers, activists, and regulatory bodies [28], who use a range of toolkits and frameworks to evaluate RAI principles. For example, Algorithmic Impact Assessments (AIA) (i.e., systematic evaluations of an algorithm's potential effects on fairness, privacy, and rights) are used before the system is deployed [35]. AIAs are analogous to environmental impact statements for algorithms, often involving public input and review to anticipate harms and inform mitigation strategies. In addition to process-oriented assessments, technical toolkits are available to examine and improve model fairness. For example, IBM's AI Fairness 360 toolkit and Google's What-If Tool provide practitioners with libraries and interfaces to test bias models, explore how changes in data or thresholds affect outcomes, and compare different fairness metrics. These tools help translate abstract criteria into concrete diagnostics and adjustments throughout an AI system's development lifecycle. Using such techniques, developers can proactively identify biases and adjust the model or decision-making policies accordingly.
However, expert-driven audits often miss significant issues that end users readily identify once systems are deployed in real-world environments [22, 39]. Expert auditors may lack the cultural insight or lived experience necessary to recognize certain forms of harm or to know where to look for them [14, 22, 39, 43]. Additionally, some harms only emerge, or are only perceived as problematic, within specific use contexts, which formal audits may not adequately simulate [13, 18, 20, 22, 38, 39].
As such, evaluating an AI system's impact is not purely a technical task. For instance, understanding fairness in a housing allocation algorithm might require insights from social work or urban studies to know what equity in housing means for different communities. The most effective responsible AI practices bring together data scientists, legal experts, policymakers, and community stakeholders to interpret audit findings and determine acceptable trade-offs [4, 7, 38]. This socio-technical collaboration is necessary because fairness is socially defined; what counts as a fair outcome or a sufficient explanation can vary with community values and historical context.
2.3 Auditing with Non-Experts
While traditional expert-led audits have been instrumental in identifying algorithmic harms, they also exhibit notable limitations, particularly in recognizing context-specific or culturally embedded biases. A growing body of work has begun exploring how everyday users can meaningfully contribute to the auditing process. Recent research and industry practices highlight a shift toward more user-engaged approaches, where non-experts are empowered through tools, platforms, and incentive structures to detect and report harmful algorithmic behaviors.
Numerous cases have demonstrated how everyday users, rather than experts, have detected critical flaws in deployed systems ranging from search engines [10] to review platforms [40] and machine translation tools [33]. In response to these trends, Shen et al. [39] introduced the concept of "everyday algorithm auditing," which describes how ordinary users, through routine engagement with algorithmic systems, can collaboratively uncover and investigate biased behaviors. These users often organically form hypotheses and test them to reveal systemic issues. Building on this insight, DeVos et al. [14] conducted behavioral studies to explore why users are frequently so effective at surfacing algorithmic harms that expert audits might overlook.
Recognizing users’ potential in algorithm auditing, researchers have increasingly focused on developing systems that directly engage users in uncovering harmful algorithmic behaviors [14, 25]. This line of work has produced various tools, including interfaces, interactive visualizations, and crowdsourcing pipelines, that support user participation in identifying biases and problematic outputs [3, 11, 23, 31]. These approaches span a spectrum from practitioner-led audits to user-driven initiatives where individuals take greater control. Examples include Search Atlas by Ochigame and Ye [32], which allows users to compare Google search results across different countries, and Dynabench by [23], a platform where users generate test inputs and flag problematic model behaviors. Lam et al. [25] advanced this approach with IndieLabel, empowering users to detect biases and author audit reports for decision-makers. Industry efforts have likewise begun to incorporate user engagement. Twitter's 2021 "algorithmic bias bounty" challenge invited users to surface biases in its image cropping algorithm [36] while Meta adopted Dynabench to audit natural language processing models [23]. Google's AI Test Kitchen also encourages users to experiment with LLM-powered agents and report harmful behaviors.
However, algorithmic auditing is not merely a technical process but a deeply normative, participatory practice. Community-centered approaches to AI alignment foreground whose values guide system behavior. For example, Bergman et al. [6] proposed the STELA methodology, which uses deliberative sessions with underrepresented groups to ‘elicit latent normative perspectives’ and rich contextual insights about what AI should do. Similarly, Reisman et al. [35] argues that accountability frameworks (e.g., Algorithmic Impact Assessments) exist to ensure that public agencies protect ‘basic democratic values, such as fairness and due process,’ when deploying automated systems. In these frameworks, community stakeholders play an important role in surfacing the value judgments and trade-offs inherent in different definitions of fairness. This literature suggests that audits should invite affected communities to apply their own fairness criteria, so that audits reflect pluralistic, context-sensitive values rather than a single technical metric.
User-driven auditing research further shows that non-expert auditors naturally use personal values and lived experiences when interpreting system behavior. DeVos et al. [14] found that users’ search and evaluation strategies are “heavily guided by their personal experiences with and exposures to societal bias.” That collective sensemaking among auditors is crucial for uncovering harms. In practice, audit participants form normative expectations of how an algorithm should behave, rooted in their own notions of right and wrong. These expectations function as a values-informed lens through which auditors notice biases and imagine remedies. Unlike purely quantitative audits, this value-based reasoning makes latent value tensions visible (e.g., conflicts among privacy, accuracy, and equity). In privileging diverse perspectives, non-expert auditing can reveal when technical definitions of fairness conflict with community priorities.
2.4 Normatively Grounded Audits
We argue that auditorship should be conceived as a normative reasoning practice based on these insights. Foregrounding whose values count and how they might conflict, audits surface the hidden trade-offs and equity tensions in AI systems, guiding more democratic and aligned design of algorithmic tools. Non-expert algorithmic audits differ fundamentally from technical audits in that they foreground subjective assessments of fairness rooted in lived experience. While technical audits evaluate algorithms against predefined metrics (e.g., demographic parity, equal opportunity), non-expert audits ask stakeholders to assess whether algorithmic outcomes align with their notions of right and wrong [7, 35]. This normative orientation emerges organically because: (1) affected communities possess contextual knowledge about historical inequities that shape their expectations of fairness [43], (2) participants naturally invoke moral reasoning when evaluating high-stakes decisions affecting vulnerable populations [14], and (3) the absence of technical training means auditors rely on ethical intuitions rather than formal metrics [39].
2.5 Defining Good Auditorship
The question then becomes, what defines a good auditor or, more broadly, a good crowd of auditors in public sector AI? A good auditor is not simply a detector of errors but should be a normative reasoner, i.e., someone who engages with the underlying value trade-offs in algorithmic systems. Prior work in participatory AI and value alignment emphasizes the importance of surfacing “latent normative perspectives” [6]. This suggests that good auditors must be attuned not just to technical flaws, but to the broader social and ethical implications of automated decisions. Drawing from existing literature, several qualities emerge:
-
Good auditors bring contextual sensitivity, recognizing that fairness is not universal but shaped by domain-specific factors such as the stakes of a decision or the vulnerability of affected groups. Rather than applying a single standard across all settings, effective auditors adapt their reasoning to the nuances of each scenario [14]. Research in user-centered audit studies reveals that participants draw on their own experiences of bias to identify system harms that experts might overlook, demonstrating the value of situated knowledge in algorithmic evaluation [14].
-
Effective auditors exhibit principled subjectivity, that is, their evaluations reflect stable value commitments (e.g., equity, harm prevention), even as they accommodate situational complexity. This echoes findings in participatory design research, where stakeholders maintain consistent orientations while remaining responsive to contextual details [26]. Good auditors are neither rigidly dogmatic nor arbitrarily subjective; they balance personal commitments with situational awareness.
-
Good auditors demonstrate discernment in their ability to identify affected groups and articulate plausible risks that stem from algorithmic deployment. This quality is particularly important when harm is diffuse or socially contingent. Research on everyday algorithm auditing shows that users often detect harms that escape formal evaluation because they possess cultural insight and lived experience necessary to recognize certain forms of bias [14, 39]. Finally, a good audit crowd reflects value pluralism by aggregating judgments from individuals with diverse lived experiences and priorities, illuminating tensions and trade-offs that might otherwise remain invisible in formal evaluation protocols [35].
With these principles in mind, we evaluate auditors’ performance across multiple dimensions of good auditorship. We assess whether participants demonstrate normative reasoning by articulating value-driven concerns, exhibit contextual sensitivity by adapting their evaluations to different AI deployment contexts, show principled subjectivity through consistent yet flexible fairness orientations, and display discernment by accurately identifying at-risk populations and high-stakes scenarios.
3 Method
We conducted a research study employing scenario-based audits of public-sector AI systems to investigate how citizens from different backgrounds evaluate the fairness of algorithmic decisions. Our methodology was designed as a quantitative inquiry using scenario-based evaluations of AI. We specifically examined how demographic factors, including race/ethnicity, gender, and socioeconomic status, shape individuals’ fairness evaluations of algorithmic outcomes. This focus is motivated by prior evidence that personal background influences perceptions of algorithmic justice [39, 42]. Capturing participant perspectives allows us to understand whether certain groups systematically see an AI system as more or less fair, and why. This study was approved by our University's Institutional Review Board (IRB) under protocol #2023-1080.
3.1 The Audit Process
We developed an exemplar-based introduction and structured audit protocol to guide participants through the evaluation of AI systems. Our approach was designed to make algorithmic auditing accessible to non-experts while maintaining the rigor necessary to capture meaningful fairness judgments.
3.1.1 Guiding Audit Overview. Since auditing an AI system can be challenging for participants without prior exposure to the process, we created a guided introduction that illustrates key audit concepts and procedures through a worked example. In this introductory material, we presented a fictional community member, Eric, who demonstrates how one might approach auditing an algorithmic system. Eric's inclusion draws from research showing that relatable, narrative-based exemplars can reduce cognitive load in complex tasks and help participants understand nuanced decision-making processes [12, 30].
When choosing a persona, we considered facets of Eric's identity. We selected social work as Eric's profession to model non-expert reasoning. Social workers frequently navigate ethical trade-offs and advocate for marginalized populations, making this profession appropriate for demonstrating values-informed auditing. We deliberately chose a male persona despite social work being a female-dominated profession. Here, we sought to avoid reinforcing gender stereotypes about care work while still conveying empathy and a focus on community. Overall, in our characterization of Eric aimed, we sought to emphasize the value of human-centered perspectives in AI evaluation. In this, Eric is portrayed as a compassionate social worker who collaborates with community groups to address issues like housing insecurity and employment barriers.
Figure 1figure.caption.2 (left) shows Eric's profile and background, illustrating his role as a bridge between technical systems and community concerns. This persona provides participants with a concrete reference point for how real-world experience and community knowledge inform algorithmic evaluation. Through Eric's reasoning process, participants gain a deeper understanding of how context factors (in Eric's case, socio-historical) are factored into algorithmic assessment.
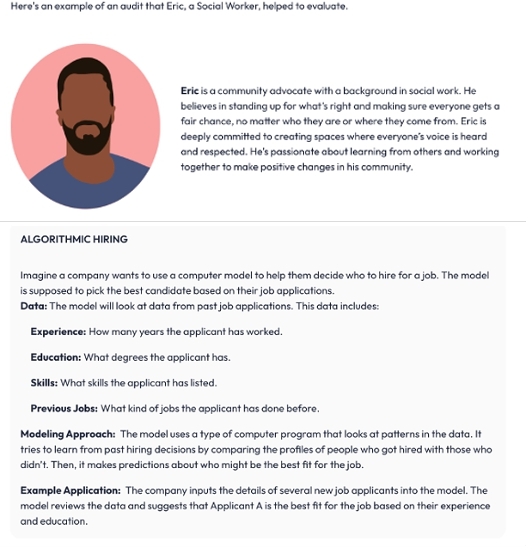
Following Eric's introduction, participants encountered a demonstration scenario featuring an AI system designed to help companies decide which job applicants to interview. This exemplar was intended to ensure participants understood the audit logic before proceeding to the main evaluation tasks. The scenario provided background information on how the model ranks applicants based on education, work experience, and other factors, as well as the potential implications of relying on algorithmic recommendations in hiring decisions. We provided sufficient technical detail to convey the model's purpose and inputs without overwhelming participants with unnecessary complexity. This approach aligns with established guidelines for scenario-based evaluations in HCI research, which emphasize accessible contexts that elicit engaged and authentic responses [17, 41].
Figure 1figure.caption.2 (right) describes the information that the developer might provide for a hiring algorithm. The description includes data collection (e.g., résumés) and where the model might be implemented. The overview concluded with participants reviewing sample audit questions that probe AI systems for concerns related to fairness, transparency, and accountability. To scaffold this process, we displayed Eric's responses in a distinct red font alongside each question. This design served two purposes. First, it demonstrated possible reasoning for identifying overlooked or context-specific factors (e.g., training data gaps that might disadvantage certain groups). Second, it modeled how to justify fairness judgments, reinforcing the importance of reflective reasoning in algorithmic evaluation [7, 26].
Figure 2figure.caption.3 shows the interface where Eric's responses appear, accompanied by hover icons that participants can activate to reveal additional justification or commentary. This interactive feature encourages deeper engagement by allowing participants to consider Eric's reasoning before deciding whether to adopt or challenge his perspective. Consistent with participatory design principles, such elements demonstrate how non-technical stakeholders can meaningfully contribute to algorithmic evaluation when provided with accessible, context-rich scaffolding [25].

3.1.2 Audit Protocol. To develop realistic audit scenarios, we identified common areas in which AI is deployed in public-sector decision-making. We drew from documented cases of government AI implementation across domains, including housing allocation, healthcare resource distribution, and social service delivery. For instance, in the Housing Allocation scenario, the description reads, “An algorithm used by a city housing authority to prioritize applicants for public housing units.” In another domain i.e., Social Service Eligibility, the description reads “A machine-learning tool used to predict families at risk of adverse outcomes (such as child neglect) to trigger preventive social services.” The complete list of scenarios are listed in Appendix 2table.caption.7. These scenarios were developed from cases reported in actual public sector AI deployments, with technical details simplified for accessibility in this study. For each scenario, participants received explanations of how the AI system operated, including input factors and decision-making processes, accompanied by a specific example illustrating potential outcomes (like the information displayed in Figure 1figure.caption.2, right).
We focused our analysis on fairness evaluations because fairness represents a critical concern in public acceptance of AI systems. Discrepancies between algorithmic fairness (as defined by designers) and perceived fairness by citizens can lead to mistrust and rejection of automated decision-making [42]. Assessing fairness judgments allows us to identify biases and value misalignments that purely technical audits might overlook. Furthermore, fairness perception serves as a tractable proxy for broader questions of AI legitimacy. When auditors overwhelmingly find an AI decision unfair, it signals issues that warrant redress to maintain the social license for the system to operate. Our methodological approach aligns with participatory auditing models, where laypeople serve as ’auditors’, applying their own fairness criteria to evaluate AI behavior [14, 25]. This approach enables us to capture rich, context-dependent notions of fairness that diverse communities bring to algorithmic governance.
To support deeper reflection, each scenario included audit prompts aligned with participatory fairness auditing frameworks [27]. These comprised both multiple-choice and open-ended questions about potential harms, impacted groups, and contextual or cultural considerations the model might overlook. Participants were also asked to identify which vulnerable groups (e.g., race, age, disability) they believed were most important to prioritize when mitigating bias in each specific context.
| Question | Description |
| Are there any factors (e.g., data, community or cultural practices) that the model might not be considering? | Inviting participants to think about overlooked factors helps reveal blind spots and promotes more comprehensive model design in data completeness and contextual gaps. |
| Is there a high risk of negative consequences if the model makes an incorrect decision? | This item prompts participants to consider the gravity of errors in high-stakes settings (e.g., denying someone a job or housing). |
| What do you believe to be the potential consequences if the model makes a mistake in its predictions? | Prompts participants to consider real-world harms arising from incorrect algorithmic decisions, such as unjust denials of opportunity or heightened social inequities [7, 34]. |
| Which of the following groups in your community might be negatively impacted by the model's decisions? | From a list of protected identities (e.g., Age, Disability, Gender, Gender identity/expression), this question encourages participants to reflect on disparate impact across diverse populations [4, 21]. |
| When building the model, which actor do you believe is the most important to focus on to limit potential bias? | AI designers must often make trade-offs among multiple fairness criteria. Asking participants to identify the most crucial factor reveals subjective values and local priorities [26]. |
|
2gray!15white |
|
3.2 Participant Recruitment and Screening
Participants were recruited through Prolific, an online platform known for its diverse participant pool and reliable data collection [15]. Prolific was selected to enable targeted recruitment criteria, including age (18 years and older) and English language proficiency, consistent with similar crowdsourced studies in social computing [24, 41].
After clicking our Prolific advertisement, respondents completed a screening questionnaire to determine if they were qualified for the study. The screening included questions about (1) knowledge of AI in decision-making contexts, (2) a short video on AI bias, and (3) two questions to evaluate what they learned from the video (i.e., “What is one reason why AI systems can develop biases?” and “What is a possible consequence of biased AI systems?”). These questions probe whether participants understand that AI models can inherit biases from training data, a key point highlighted in fairness and accountability research [4], and whether they understand the real-world implications of bias (e.g., discrimination against specific groups). Responses to these questions allowed us to evaluate a baseline understanding of AI concepts (or the ability to learn them). If participants answered either question incorrectly, they were removed from the study.
3.2.1 Demographics and Value Orientations. We received responses from 130 participants. Table 4table.caption.9 (Appendix C) provides detailed demographic breakdowns. Our sample included representation across minoritized groups:
-
Racial/Ethnic minorities: 28.5% (n=37), i.e., belonging to racial/ethnic minority groups
-
Gender minorities: 46.2% (n=60) i.e., women or non-binary individuals
-
LGBTQ+ community: 26.9% (n=35)
-
People with disabilities: 10.8% (n=14)
-
Socioeconomic minorities: 12.3% (n=16) i.e., socioeconomically disadvantaged
-
Immigration background: 3.8% (n=5) i.e., as immigrants or refugees
The aggregate demographics indicate a reasonably diverse sample, skewing towards young, educated adults with mixed economic status.
Participants were presented with the Portrait Values Questionnaire (PVQ-21), a 21-item instrument derived from Schwartz's theory of basic human values [37]. The PVQ-21 presents short verbal portraits of different people, each emphasizing particular motivational goals (e.g., achievement, security, benevolence). In the PVQ-21, respondents rate how similar they perceive themselves to be to each portrait, thereby capturing the relative importance of each value domain. The PVQ-21 is widely used in cross-cultural and psychological research to assess how individuals prioritize various universal values, such as self-direction, conformity, hedonism, or universalism. In this study, we investigate potential correlations between participants’ value orientations and their subsequent evaluations of the scenarios, aligning wconsistent with prior research suggesting thatvalues can significantly influence attitudes toward technology and governance [26, 39]. Once participants completed the questionnaire, they were directed to the AI auditing platform, where they entered their unique identifier and completed the audit.
3.3 Data Analysis
We used quantitative modeling to understand how participants reason about fairness, risk, and harm in various AI scenarios. Our analytical approach was designed to assess the four dimensions of good auditorship identified in our theoretical framework, i.e., normative reasoning, contextual sensitivity, principled subjectivity, and discernment. We discuss each in turn:
-
To assess contextual sensitivity, we first examined if participants made differentiated risk assessments across scenarios rather than applying uniform judgments. We fit a linear mixed-effects model with scenario as a fixed effect and participant ID as a random intercept, allowing us to estimate systematic variation in risk perceptions by use case while accounting for repeated measures within individuals. We conducted pairwise comparisons of marginal means across scenarios using Tukey's HSD adjustment for multiple comparisons to identify specific contextual differences in perceived risk.
-
To test for principled subjectivity (i.e., the extent to which participants maintained consistent value orientations while adapting to contextual specifics) we estimated a cumulative link mixed model (CLMM) predicting ordinal risk ratings. Fixed effects included scenario context, participant demographics (gender, age, income, education, minoritized identity status), fairness-related beliefs measured on Likert scales, and theoretically relevant values from the Portrait Values Questionnaire (PVQ-21), including benevolence, universalism, security, tradition, and power. Participant ID was included as a random intercept to capture individual-level consistency in risk sensitivity. This model structure allowed us to assess whether fairness orientations remained stable across contexts (evidenced by significant random effects) while still being responsive to scenario-specific features (evidenced by significant fixed effects for scenario).
-
To evaluate participants’ discernment (i.e., their ability to distinguish between high-risk and low-risk AI applications), we compared participant risk ratings with expert-coded severity assessments. The research team independently rated each scenario's expected harm severity using a 5-point scale based on three criteria: (1) likelihood of disproportionate harm, (2) vulnerability of affected populations, and (3) severity of real-world consequences (See Table 3table.caption.8). We then fit a linear mixed-effects model treating expert severity codes as predictors of participant risk ratings, with participant ID as a random intercept. A significant positive relationship would indicate that participants could meaningfully differentiate scenarios based on substantive equity concerns rather than responding arbitrarily.
-
To assess normative reasoning capabilities, we analyzed participants’ identification of vulnerable groups using precision and recall metrics. For each scenario, we compared participant-identified groups to researcher-coded expected vulnerable populations, calculating the percentage of correctly identified groups (precision) and the percentage of expected groups that were identified (recall). We also conducted chi-squared tests to examine relationships between bias recognition (groups identified as potentially harmed) and design prioritization (groups selected as most important to protect), revealing potential tensions between awareness and actionable focus.
3.3.1 Individual Consistency and Reliability. We calculated intraclass correlation coefficients (ICC) to quantify within-participant consistency in risk assessments across different scenarios. The ICC represents the proportion of total variance attributable to between-participant differences, with higher values indicating more stable individual orientations toward risk perception. This measure helped us distinguish systematic individual differences from measurement error or random variation.
All mixed-effects models were fit using the lme4 package in R, with significance assessed at α = 0.05. Model assumptions were verified through residual plots and normality tests. Missing data were handled through listwise deletion, as the proportion of missing responses was less than 5% across all variables.
4 Results
This section presents our empirical findings on participants’ engagement with AI auditing tasks. We organized the results into five analytic components, each corresponding to a dimension of auditor behavior introduced in the previous section. These dimensions reflect context-sensitive reasoning and participant-level variation, providing a multifaceted view of ’good auditing’.
First, we assess whether participants made context-aligned risk evaluations, rating some AI deployment scenarios as riskier than others in consistent and interpretable ways. Next, we examine how demographic, attitudinal, and value-based factors shaped risk assessments, testing whether risk sensitivity was more a function of personal traits or context-specific reasoning. Third, we explore stability in risk assessments, evaluating whether individuals showed consistent orientations across scenarios. Fourth, we assess the discernment of participants in risk evaluation, asking if they could distinguish high-risk scenarios (e.g., with equity concerns) from those with a lower potential for harm. Finally, we analyze fairness trade-off awareness and group harm recognition, examining how participants prioritized competing fairness goals and identified impacted populations.
4.1 Fairness Attitudes
We included several attitudinal measures in our analysis, reflecting how participants think about fairness in decision-making (e.g., emphasis on equity, inclusion, objectivity). Participants responded to six Likert-scale items, each reflecting a different conception of fairness in algorithmic systems. Several patterns emerged. First, there was overwhelming agreement that fairness should account for individuals’ needs and circumstances. Specifically, 90% of participants agreed with the statement “AI should consider people's needs and well-being to create fair and personalized experiences,” while only 4% disagreed. This response demonstrates a broad endorsement of personalized, human-centered fairness. Second, participants broadly supported equity- and inclusion-oriented approaches to fairness. When asked whether algorithms should “sometimes consider people's backgrounds to make fairer and more inclusive decisions,” 87.3% agreed and only 6.4% disagreed. Similarly, 79.1% agreed that systems should “take people's backgrounds into account to address past inequalities and promote fairness,” with just 9.1% disagreeing. These responses suggest that most participants recognize the need for historically informed and context-sensitive models of fairness.
Third, participants largely rejected the purely formal notions of fairness based on objectivity. For the statement “AI should base decisions only on objective data to ensure fairness and eliminate discrimination,” only 16.4% agreed, while 73.6% disagreed. This view challenges dominant narratives that equate fairness with objectivity or neutrality, highlighting a general skepticism toward technocratic definitions of fairness. Fourth, efficiency and profit motives were viewed as incompatible with fairness. In response to the statement “AI should prioritize objectives like efficiency or profitability over people's needs and well-being,” 70% disagreed, while 20% agreed. This underscores a perceived tension between organizational performance goals and moral obligations toward fairness. Fifth, opinions were more divided when participants considered goal-focused design approaches. Asked whether algorithms should “focus only on their main goals and not consider people's needs or well-being,” 49.5% agreed, 29.4% disagreed, and the rest were neutral. This ambivalence may reflect a lack of clarity about what constitutes a “main goal,” or discomfort reconciling goal-orientation with human-centered concerns.
4.2 Evaluating Good Auditorship
The findings in the previous section reveal a general orientation among auditors toward contextual, equity-aware, and person-centered understandings of fairness. Most participants rejected the idea that fairness can be achieved through neutrality or strict objectivity. Instead, they endorsed fairness approaches that consider individual and group-based circumstances. These attitudes provide important scaffolding for understanding how participants later approached specific audit tasks, especially when weighing trade-offs or identifying at-risk groups. They also suggest a readiness to engage with nuanced, value-laden conceptions of fairness in algorithmic systems. To evaluate the quality and character of participants’ audit behavior, we turn to several dimensions of what we term ‘good auditor-ship.’ By this, we mean the degree to which participants engage in thoughtful, informed, and context-sensitive evaluation of algorithmic harms. Specifically, we examine whether participants align their fairness preferences with context (e.g., varying their responses based on the domain of use or the stakes involved); demonstrate stability in risk assessments (i.e., showed consistency in evaluating similar risk scenarios); exhibit discernment in assessing different types of risks (rather than responding uniformly across contexts); recognize fairness trade-offs and could prioritize among competing fairness goals when asked to make optimization choices; identified impacted or marginalized groups, thereby demonstrating sensitivity to equity and historical disadvantage.
4.2.1 Context-Aligned Risk Evaluations. To set the stage for upcoming analyses, we first examine whether participants rated certain AI deployment contexts as riskier than others. Participants evaluated each scenario in response to the question “How risky do you think it would be for this system to make a mistake?” Responses were measured on a 5-point Likert scale and converted to ordinal values where “Very Low” = 1 and “Very High” = 5.
To determine whether risk perception varied systematically by context, we fit a linear mixed-effects model with scenario context as a fixed effect and participant ID as a random intercept. This approach allowed us to account for the nested structure of the data since each participant rated up to three different AI scenarios and isolate the influence of scenario context from baseline risk sensitivity across individuals. We examined marginal means and conducted pairwise comparisons between contexts (adjusted for repeated measures) to estimate differences in perceived risk across scenarios. Among the thirteen scenarios, the average risk evaluation was 3.77 (σ = 0.98). The full set of means is reported in Appendix C. The model revealed a significant effect of the scenario context on risk ratings, F(11, 316) = 3.77, p <.001, with a moderate marginal R2 of.11 and conditional R2 of.44, indicating that both scenario-level and participant-level factors contributed meaningfully to perceived risk.
Several important differences emerged. Participants rated Immigration Fraud Detection (M = 4.33, SE = 0.16) as significantly riskier than Optimize Renewable Energy Production (M = 3.20, SE = 0.18), t(283) = 2.77, p =.02. Similarly, Sex Disparities in Opioid Drug Safety Signals (M = 4.20, SE = 0.16) was perceived as significantly riskier than Student Performance Monitoring (M = 3.29, SE = 0.13), t(285) = –4.53, p <.001. Industrial Pollution Monitoring (M = 3.85) was also seen as riskier than Student Performance Monitoring, t(286) = 4.90, p <.001. In contrast, scenarios like COVID Vaccine Distribution, Misinformation Detection, and Evaluate Educational Content did not significantly differ from most other contexts.
These results confirm that participants made contextually sensitive and differentiated risk assessments, rather than assigning similar levels of risk across domains. Notably, contexts involving immigration enforcement and medical bias scenarios with clear ethical and social stakes were rated as higher risk, suggesting that participants intuitively weighted risk based on perceived human consequences. This aligns with our broader claim that auditors are capable of assessing AI systems in situated and value-conscious ways.
4.2.2 Stability in Risk Assessments. Beyond context and attitudinal alignment, we also examined how consistently participants evaluated risk across scenarios. Each participant rated up to three unique AI use cases, allowing us to examine within-person consistency. We observed moderate individual-level consistency, and some participants consistently rated the scenarios as higher or lower risk. Statistically, the random intercept for participants in our mixed model showed substantial variance (τ = 0.32), yielding an intraclass correlation coefficient (ICC ≈ 0.37, 95% CI ≈ 0.25–0.50), which was significantly greater than zero, χ2(1) = 52.1, p <.001. This means that approximately 37% of the variance in risk ratings was due to differences between individuals, confirming that participants had relatively stable orientations toward perceived AI risk, even as they adapted to the specific context of each scenario.
4.2.3 Risk Differentiation. To assess whether participants were able to differentiate between scenarios based on the presence or absence of equity-related concerns, we evaluated whether their risk ratings aligned with expert-coded assessments of harm (Table 3table.caption.8). The rationale here is that effective auditors should assign higher risk ratings to scenarios with more severe or inequitable outcomes (e.g., predictive policing or biased welfare allocation) and lower ratings to more benign or infrastructural use cases (e.g., environmental modeling with minimal human impact).
We then tested whether these severity codes predicted participants’ numerical risk ratings using a linear mixed-effects model with scenario severity as a fixed effect and participant ID as a random intercept. The model revealed a statistically significant effect of severity on perceived risk (β = 0.14, p <.001), indicating that participants were generally sensitive to the underlying severity of each scenario. As severity increased by one unit, average risk ratings also increased, suggesting that participants were not rating arbitrarily, but rather responding to substantive cues of harm. This provides preliminary evidence that non-expert auditors can meaningfully distinguish high-risk algorithmic systems from low-risk ones, even when the domain varies.
4.2.4 Discernment in Risk Assessment. To assess whether participants were able to differentiate between scenarios based on the presence or absence of equity-related concerns, we evaluated whether their risk ratings were aligned with expert-coded harm assessments. The rationale is that effective auditors should rate objectively more harmful systems (e.g., predictive policing, biased welfare allocation) as higher risk than more benign or technical systems (e.g., automated resource optimization with minimal human impact). To benchmark this, the research team independently coded the expected risk related to equity in each scenario using a heuristic that accounts for the severity of human impact, population sensitivity, and likelihood of disproportionate harm. These author-generated risk codes are reported in Table 3table.caption.8. We then compared these with the average scores of the participants for each scenario.
Good auditors should also be able to name relevant groups in each scenario to demonstrate awareness of who may be most affected by algorithmic decisions. To evaluate whether participants successfully identified at-risk populations, we assessed both (1) the groups participants named in response to the question “Which groups might be negatively impacted by the model's decisions?” and (2) whether those responses aligned with researcher-identified groups for each scenario.
We first calculated whether each participant named at least one group that matched those identified by the research team as high-risk for the scenario in question. Across all responses, 81.5% of participants named at least one relevant group. Match rates varied considerably by scenario. For example, 100% of responses correctly identified at least one expected group in scenarios like Covid Vaccine Distribution Planning and Allocation of Housing Programs, while only 29.6% did so in Evaluate Educational Content, a scenario with more ambiguous social impact. On average, participants matched 51.6% of the expected groups per scenario (SD = 0.12).
We then assessed which social groups were most accurately identified across all scenarios by calculating group-level precision and recall. Socioeconomic Status, Race/Ethnicity, and Disability had the highest number of true positive mentions overall, indicating that participants frequently recognized these populations as vulnerable. However, recall scores varied substantially; while National Origin and Race/Ethnicity had relatively high recall (0.86+), other categories like Parental Status (recall = 0.29), Age (0.43), and Gender (0.50) were under-identified even when relevant to the scenario. Several groups, such as Gender Identity/Expression, Sexual Orientation, Veteran Status, and Marital Status, were mentioned by participants even when not designated as at-risk in any scenario. These “false positives” suggest broader social sensitivity, but may also indicate participants applying generalized risk heuristics rather than scenario-specific reasoning.
4.2.5 Awareness vs. Design Prioritization. To better understand the relationship between participants’ awareness of bias and their design priorities, we compared the demographic categories they identified as likely to be negatively impacted by the AI system to those they believed developers should explicitly prioritize in the system's design. Although both questions aimed to surface equity concerns, the former elicited a more diagnostic lens (that is, “who could be harmed?”), while the latter focused on intervention (that is, “whose needs should be centered?”). We conducted a chi-squared independence test to assess the alignment between these two dimensions. The analysis of standardized residuals revealed some discrepancies between bias recognition and design prioritization. For instance, Veteran Status (residual = + 1.22 in awareness, − 1.42 in design prioritization) and Parental Status (+ 0.87 vs. − 1.02) were more frequently flagged as at-risk populations than they were selected for design attention. This suggests that participants may recognize these groups as vulnerable but struggle to translate that awareness into actionable design choices. In contrast, Socioeconomic Status showed the opposite pattern (− 1.30 in awareness, + 1.52 in design prioritization), indicating that participants may view addressing class-based disparities as a moral imperative, even when they do not immediately identify this category as affected in a specific scenario.
4.3 Demographics, Attitudes, and Risk Evaluations
We next examined the extent to which individual differences, e.g., demographics, fairness attitudes, and personal values, influenced participants’ assessments of algorithmic risk. As in earlier models, we focused on participants’ ordinal risk judgments at the scenario level, using a five-point Likert scale ranging from “Very Low” to “Very High.” To evaluate whether these assessments reflected stable dispositions or adaptive responses, we estimated a cumulative link mixed model (CLMM) predicting risk ratings. Fixed effects included the AI deployment context, participant demographics (gender, age, income, education, and minoritized identity status), fairness-related beliefs (e.g., support for individual needs or efficiency), and a subset of theoretically relevant values from the PVQ-21 framework (e.g., benevolence, power, and tradition). A random intercept for each participant accounted for baseline variation in risk sensitivity.
The model explained a substantial share of variance (marginal R2 =.318, conditional R2 =.456), reinforcing the interpretation that both contextual features and certain attitudinal differences meaningfully shaped participants’ perceptions of AI risk. As in prior analyses, scenario context remained a significant and powerful driver of risk judgments. Compared to the baseline, participants assigned significantly higher risk ratings to Immigration Fraud Detection (β = 1.18, SE = 0.53, p =.027), while both Monitor Student Performance (β = -1.37, SE = 0.49, p =.005) and Optimize Renewable Energy Production (β = -1.30, SE = 0.56, p =.021) were rated as significantly less risky.
Among the fairness attitude variables, one predictor reached significance, i.e., participants who expressed neutrality toward the importance of demographic inclusion were less likely to perceive a scenario as risky (β = 0.93, SE = 0.43, p =.031). This may reflect uncertainty or ambivalence about whether background-based considerations should shape model design, and aligns with prior findings that principled reasoning (not blanket concern) guides fairness reasoning. Other fairness predictors, including support for individual needs or efficiency, were not statistically significant in this specification.
None of the demographic variables (gender, age, income, education, or minority association) was significantly associated with risk perception. Likewise, none of the value-based predictors (benevolence, universalism, tradition, security, or power) emerged as significant, suggesting that while these orientations may inform broader social judgments, they were not reliably associated with higher or lower risk sensitivity in this task. The variance of the participant-level random intercept (τ00 = 1.03) indicates some individual variation in baseline risk perception, but these effects were modest relative to the dominant role of context.
Again, we find evidence that participants acted as principled, context-sensitive evaluators rather than as biased or ideologically driven evaluators. Their judgments were shaped by the specific contours of each scenario and, to a lesser extent, by attitudinal orientations toward fairness.
5 Discussion
Our findings highlight several dimensions of good auditorship in non-expert audits. First, auditors displayed principled subjectivity- they applied their own values consistently, yet adapted judgments to specific scenarios. For instance, a mixed-effects model shows “strong evidence of principled subjectivity, that is, auditors brought a values-informed lens to their evaluations but did not apply their attitudes uniformly across scenarios. Instead, they tailored their assessments to the details of each AI deployment, demonstrating thoughtful engagement and scenario sensitivity”. In practice, this meant a participant might emphasize equity in one scenario but shift focus based on context in another. Such flexibility suggests auditors were not rigidly dogmatic; they balanced personal commitments with situational nuances.
Second, auditors exhibited context sensitivity and discernment. Participants did not rate systems arbitrarily; their risk judgments rose with expert-rated harm severity. A mixed-effect analysis found that higher expert-coded severity predicted higher perceived risk (β = 0.14, p<.001). In other words, auditors generally distinguished high-risk from low-risk AI applications based on inequity cues. This empirical sensitivity indicates that non-experts can meaningfully differentiate harms across domains. Moreover, most auditors identified at least one relevant affected group per scenario; 81.5% of participants correctly named a high-risk group. However, on average, they cited only about 52% of the expected groups. This partial success suggests auditors were often aware of vulnerable populations, even if they missed some. Overall, these patterns demonstrate a strong capacity for contextually grounded evaluations of risk and impact.
Our results suggest design guidance for supporting auditorship. Interfaces should amplify contextual cues and provide structure for value-driven reasoning. Given auditors’ normative orientation, audits could invite participants to explicitly articulate their fairness criteria (e.g., via prompts or deliberative prompts). Features like “value dashboards” or checklists of affected communities might help auditors remember to consider multiple perspectives, potentially improving coverage (e.g, raising group-identification from 52% toward 100%). Interactive fairness metrics tools that translate values into model constraints could also bridge the gap between identification and action. In summary, effective auditing combines principled subjectivity with scenario awareness and active consideration of trade-offs. Where we observed tension – strong identification of risks but uncertainty about fixes – we recommend tooling that scaffolds decision-making, helping auditors weigh harms, understand policy options, and surface community priorities.
5.1 Consensus on Principles and Context-Sensitive Application
One of the most significant findings of this work is the consensus among auditors regarding fairness principles, despite their demographic backgrounds. This finding both supports and extends prior literature on fairness perceptions while challenging assumptions about demographic variation in algorithmic fairness preferences. Participants in our study rejected purely technical approaches to fairness in favor of contextual, equity-aware approaches. Specifically, 90% of participants agreed that AI should consider people's needs and circumstances, 87.3% supported algorithms considering backgrounds for inclusive decisions, and 73.6% disagreed with basing decisions solely on "objective" data. This consensus aligns with Binns et al. [7] finding that citizens view fairness as fundamentally relational rather than mathematical, requiring consideration of individual circumstances and social context. Importantly, our quantitative analysis found that demographic variables including gender, age, income, education, and minority status—were not significantly associated with risk perception or fairness attitudes. This finding contrasts with some prior work suggesting demographic differences in algorithmic fairness preferences [42], but supports research indicating that context and system characteristics often matter more than individual demographics in shaping fairness judgments [22]. The consensus we observed may reflect the inherently social nature of fairness and that technical metrics must be grounded in shared social understandings of justice [38]. Our participants’ rejection of purely objective approaches (73.6% disagreement) echoes findings that citizens view algorithmic neutrality as insufficient for achieving fairness in high-stakes public decisions [41].
The patterns we observe demonstrates the need for participatory approaches that allow communities to negotiate fairness criteria for specific contexts rather than imposing universal technical standards. While there may be broad agreement on fairness principles such as the importance of considering individual circumstances and addressing historical inequities, the operationalization of these principles requires context-specific deliberation. Furthermore, the tension between consensus on principles and variation in application reflects the challenge of translating abstract fairness concepts into concrete algorithmic implementations [35]. Our results suggest that effective AI governance requires both recognition of shared democratic values and mechanisms for non-expert input on context-specific applications of these values. Rather than seeking demographic representation to capture different fairness perspectives, our results suggest that participatory processes should focus on facilitating deliberation about how shared fairness principles apply to specific deployment contexts, aligning with recent work on deliberative AI governance stressing collective reasoning over demographic sampling [6].
5.2 Participatory Oversight Mechanisms
A major implication of this research is that community-based algorithm audits are a feasible and valuable form of participatory AI oversight. We demonstrated that ordinary citizens, when provided with an accessible scenario description, can engage in substantive evaluation of an algorithm's fairness and even identify potential biases or improvements. This finding contributes to the growing body of HCI work on end-user algorithm auditing [14, 25, 39] by extending it to the public sector context. Designing effective participatory audits will require careful attention to usability (so that non-experts understand the AI system sufficiently), representativeness (ensuring diverse participation, especially of those most impacted by the algorithm), and empowerment (giving citizens confidence that their input will have an impact). Our study offers a template for how such audits might be structured in practice, using scenario-based evaluations that resonate with participants’ experiences, and facilitating deliberation to draw out collective insights. We see an opportunity for designers and researchers to create toolkits that support non-expert audits – for example, simplified audit interfaces that allow individuals to test “what if” scenarios on an algorithm (similar to Google's What-If Tool), or visualizations that show the community how decisions are distributed across groups. By lowering the barrier to auditing, such tools could enable non-expert groups or civil society organizations to regularly audit local government algorithms and publish their findings, much like watchdog NGOs.
Importantly, although not tested in this study, participating in the audit process may increase trust in AI. As individuals and communities have a say in how algorithms are constructed, they may feel more confident in and accepting of the outputs of models even if they do not fully align with their values [26]. This suggests a need for feedback loops where participatory audits not only gather data about fairness but also build algorithmic literacy and trust among citizens, as long as the process is genuine and their voices are heard. Our work contributes to CSCW and CHI discussions by illustrating a concrete way to operationalize participatory algorithmic governance. Audits can act as a “safety net” that catches technical audits that miss and as a bridge between AI developers and the public.
5.3 Integrating Audits into AI Development
Finally, our study proposes insight into how AI developers might integrate feedback throughout the lifecycle of an algorithm. One contribution is identifying that fairness issues often become apparent only when viewed through the lived realities of affected communities. The literature suggests that good auditors are reflective, situated, and morally engaged participants whose contributions extend beyond performance assessment to normative critique. Designing for this kind of auditorship requires supporting both individual reasoning and structured collective deliberation, so that audits can function not only as diagnostic tools but as mechanisms of democratic alignment in AI governance. Therefore, AI development teams (or government contractors building public algorithms) should seek input early, during problem formulation and dataset selection, not just after deployment. Techniques from participatory design could be employed by convening focus groups from target user communities to discuss what fairness means to them in the given context, which could inform the choice of model objectives or constraints. We show that individuals can engage with the concept of an algorithm and raise relevant concerns, such as transparency or undue harm to a group, so their input can be specific and actionable. We suggest establishing feedback channels, such as user advisory boards for algorithms, community testing phases (analogous to beta tests, but for policy algorithms), and ongoing surveys or reporting tools that allow citizens to flag perceived unfair decisions. The AI Incident Database is one such materialization of these recommendations. Incorporating these into the development cycle could lead to AI systems that are more robust to public scrutiny.
6 Limitations and Future Work
Our study has several important limitations that should be acknowledged when interpreting these findings. First, our use of Prolific crowd workers, while providing demographic diversity, differs meaningfully from engaging actual local community members who face real algorithmic decisions. Participants in our study were acting as proxies and may not have had personal stakes in the scenarios presented. For instance, someone evaluating a policing algorithm scenario may not live in an affected community or fully grasp its real-world implications. This limitation does not invalidate our approach but suggests that results should be interpreted as evidence of citizens’ capacity for algorithmic evaluation rather than definitive assessments of specific systems.
Second, our exemplar-based introduction may have introduced training or priming effects that shaped participants’ auditing approaches. While Eric's persona as a social worker focusing on housing insecurity and employment barriers was designed to demonstrate community-grounded reasoning, it may have inadvertently cued participants toward emphasizing social equity issues. Although such scaffolding was necessary to elicit quality responses, it may have reduced the spontaneity and diversity of participants’ perspectives. Importantly, the audit protocol did not explicitly instruct participants to reason from values. Rather, our prompts asked open-ended questions about potential harms, affected groups, and overlooked factors. Thus, the values extracted from responses emerged from participants’ reasoning processes, not from our framing. For example, when asked “Which groups might be negatively impacted?”, participants consistently invoked equity concerns and vulnerable populations. Future work should explore methods that provide adequate guidance while preserving more authentic viewpoints.
Third, our individual-focused methodology, while revealing important patterns in auditor behavior, does not capture the collective deliberation processes that would likely characterize real-world audits. Research in participatory design suggests that group sensemaking often produces richer insights than individual assessments alone [14], and our findings hint at the value of aggregating diverse perspectives to surface value tensions.
Fourth, while our sample provides reasonable diversity across multiple axes, we acknowledge limitations in capturing certain perspectives (e.g., non-English speakers, individuals without internet access, those unfamiliar with online research platforms). Further, our screening ensured basic literacy about algorithmic bias but selected for participants with some AI familiarity. This may limit generalizability to populations with no prior exposure to algorithmic fairness concepts. However, as AI systems increasingly affect public services, baseline awareness is growing. Our screening reflects realistic conditions where auditors might receive brief training before participating in oversight activities. Future research should examine completely naive participants to assess whether fundamental capacity for normative reasoning differs from our sample.
Future research should address these limitations by investigating audits in more naturalistic settings, such as having citizens audit in teams or participate in workshop-style deliberations where they can build on each other's insights. Such studies would better reflect the collaborative nature of democratic oversight while maintaining the principled reasoning we observed at the individual level. Additionally, longitudinal studies tracking how audit findings influence actual algorithmic deployment decisions would help establish the practical impact of participatory oversight mechanisms.
7 Conclusion
This study investigated how ordinary citizens reason about fairness and risk when auditing public-sector AI systems through community-based evaluations. Drawing on responses from 110 participants across thirteen scenarios inspired by real-world government AI deployments, we found that auditors demonstrate principled subjectivity, applying consistent value orientations while adapting their assessments to specific contexts. Participants made differentiated risk evaluations based on scenario characteristics, with higher-stakes systems involving vulnerable populations receiving appropriately elevated risk ratings. Most auditors successfully identified at least one relevant affected group per scenario, though coverage of all expected groups remained incomplete. Our findings challenge the notion that effective AI auditing requires technical expertise alone. Instead, we argue that good auditors function as normative agents who surface latent value tensions and bring contextual knowledge that formal assessments might overlook. Participants rejected purely technical definitions of fairness in favor of approaches that consider individual circumstances and historical inequities, suggesting that community audits can reveal misalignments between designer intentions and public values.
